On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap Type: | Write | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap executes a SQL update with the given properties. Keys from the document will be used as the columns to update and their values will be the updated value in the column. ETL Transformations & Data FlowThis snap is a data source. It works by performing a standard JDBC DatabaseMetaData#getTables() query for the tables within the database. The Schema name value is used to populate the schemaPattern parameter in that query. This snap does not require any temporary files or other external resources. Input & Output
Expected upstream Snaps: Any Snap with a document output view. Expected downstream Snaps: Any Snap with a document input view. Note: nothing is written to the output view so pipelines should only be used to sequence operations. Modes
| |||||||||||||||||
| Prerequisites: |
| |||||||||||||||||
| Limitations and Known Issues | None at the moment.
| |||||||||||||||||
| Configurations: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Redshift Account for information on setting up this type of account. Views:
| |||||||||||||||||
Settings | ||||||||||||||||||
Label | Required The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||||||||||
Schema name | The database schema name. Selecting a schema filters the Table name list to show only those tables within the selected schema. The property is suggestible and will retrieve available database schemas during suggest values.
Example: test Default value: [None] Expression property: No | |||||||||||||||||
Table Name | Required. Name of the table to execute the update on
Example: people Default value: Not selected Expression property: No | |||||||||||||||||
Update condition | Specify the SQL WHERE clause of the update statement. You can define specific values or columns to update (Set condition) in the upstream Snap, such as Mapper Snap, and then use the WHERE clause to apply these conditions on the columns sourced from the upstream Snap. For instance, here is a sample of an Update SQL query:
Condition to execute the update on.
Example: email = 'customer@example.com' Refer to the example to understand how to use the Update Condition. Examples: Without using expressions
Using expressions
Default value: Not selected Expression property: Yes | |||||||||||||||||
| Number of retries | Specifies the maximum number of attempts to be made to receive a response. The request is terminated if the attempts do not result in a response. Example: 3 Default value: 0
| |||||||||||||||||
| Retry interval (seconds) | Specifies the time interval between two successive retry requests. A retry happens only when the previous attempt resulted in an exception. Example: 10 Default value: 1 | |||||||||||||||||
|
| |||||||||||||||||
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|
Troubleshooting
| Error | Reason | Resolution |
|---|---|---|
| This issue occurs due to incompatibilities with the recent upgrade in the Postgres JDBC drivers. | Download the latest 4.1 Amazon Redshift driver here and use this driver in your Redshift Account configuration and retry running the Pipeline. |
Example
Basic Use Case
- The following pipeline describes how the Snap functions along with Mapper snap in a pipeline. Refer to the "Redshift Update_1.slp" in the Downloads section for pipeline reference.

Following is a selection from the "testupdate" table listing the customers information:

Assume we wish to update the customer with the id = "3" with a new age = "31".
Enter testupdate in the Table name property and id='3' in the Update condition property.
Assume that the Update Snap receives a Map data in the input view as following from the Mapper Snap:
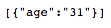
The selection from the "testupdate" table will now look like this:

- Be careful when updating records. If we had omitted the Update condition property, in the example above, the "testupdate" table would have looked like this:

The pipeline preview will look like below:

Typical Snap Configurations
When you save and execute the above pipeline as shown in the example with the update condition, the Snap internally formats a standard SQL UPDATE statement as following:
| Code Block |
|---|
UPDATE testupdate SET age='31' WHERE id='3'; |
and submit the request to the database server.
Advanced Use Case
The following pipeline describes how the Snap functions along with other Snaps such as Redshift Execute and Mapper in a pipeline. Refer to the "Redshift Update_2.slp" in the Downloads section for pipeline reference.

We are using "Redshift Execute" to select all the records in the table "testupdate":
We are then using the "Mapper" to select the appropriate column "$age" in the Expression property and creating the new set of updated values there ($age+31) and finally specifying the target column name, "$age" in Target path.

After validating/ executing the above pipeline, the "testupdate" table has been changed to:

Downloads
| Multiexcerpt include macro | ||||
|---|---|---|---|---|
|
| Attachments | ||
|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|