On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
The Clean Missing Values is a Transform type Snap that is used to process any missing values in an incoming dataset by dropping or imputing (replacing) values. The Clean Missing Values Snap supports the following four approaches to process missing values:
- Drop Row
- Impute with Average
- Impute with Popular
- Impute with Custom Value
Input and Output
Expected input
- First input view: A document containing the missing values.
- Second input view: A document containing data statistics computed by the Profile Snap.
| Info |
|---|
The Clean Missing Values Snap processes the data in streams, while the Profile Snap consumes all the data before it derives any statistics. Therefore, while using the Profile Snap, we recommend the following:
|
Expected output: A document where all missing values have been processed.
Expected upstream Snaps
- First input view: A Snap that has a document output view. For example, Mapper, CSV Generator, or Categorical to Numeric.
- Second input view: A sequence of File Reader and JSON Parser Snaps. These Snaps read the data statistics computed by the Profile Snap in another Pipeline. It is required to select Value distribution in the Profile Snap and set Top value limit according to the number of unique values; or set to 0, which means unlimited.
Expected downstream Snaps: A Snap that has a document input view. For example, Mapper, JSON Formatter, or Type Converter.
Prerequisites
None
Configuring Accounts
Accounts are not used with this Snap.
Configuring Views
Input | This Snap has exactly two document input views, the Data input view and the Profile input view. |
|---|---|
| Output | This Snap has exactly one document output view. |
| Error | This Snap has at most one document error view. |
Troubleshooting
None
Limitations and Known Issues
None
Modes
- Ultra pipelinesPipelines: Works in Ultra pipelinesPipelines.
- Spark mode: Not supported in Spark mode.
Snap Settings
| Label | Required. The name for the Snap. You can modify this to be specific, especially if you have more than one of the same Snap in your pipeline. | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
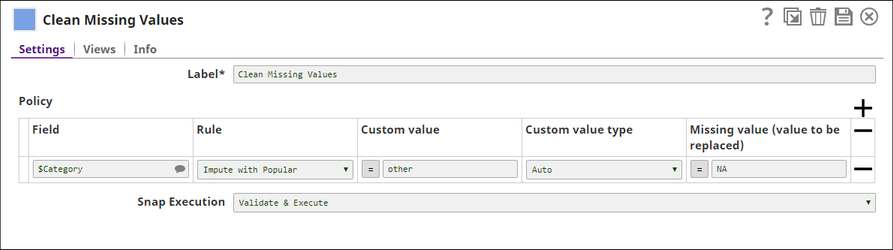
| Policy | Specifies the preferences for fields, missing values, and handling methods. For each policy, select the field with missing values, the handling method, the custom value for Impute with Custom Value, and the missing value to be handled. | ||||||||||||
| Field | The field that contains missing values. This is a suggestible field that suggests all the fields in a dataset. Default value: None | ||||||||||||
| Rule | The handling method for missing values in the selected field. The available options are:
Default value: Drop Row | ||||||||||||
| Custom value | The value the Snap uses to replace missing values when you select Impute with Custom Value option. Default value: None | ||||||||||||
| Custom value type | The type of value that the Snap must use to replace missing values when you select Impute with Custom Value option. The available options are:
Default value: Auto | ||||||||||||
| Missing value (value to be replaced) | Specify the missing value here. This option is available only when the field has specific missing values. For example, fields that contain "N/A", "None", "Unknown", "-1", etc as the missing value. Default value: None | ||||||||||||
|
|
Example
Handling Missing Values in a Dataset
The pipeline in this example, Clean_Missing_Values_Popular_Value.slp, demonstrates how you can use the Clean Missing Values Snap to process missing values in a dataset with its most popular value.
In this example:
- We input a CSV file with some missing values.
- We process the smaller dataset in the first input view of the Clean Missing Values Snap.
- We process the larger dataset along with data statistics in the second input view. Profile Snap is used to get the data statistics of the input.
Download this pipeline.
| Expand | ||
|---|---|---|
| ||
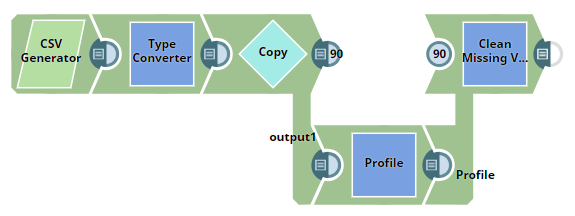
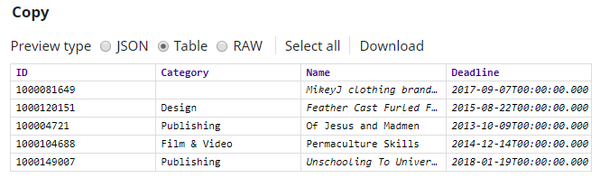
The input is generated by the CSV Generator Snap. The Type Converter Snap is used downstream of the CSV Generator Snap to automatically convert data types of the values. The output from the Type Converter Snap is then passed into the Copy Snap. The Copy Snap is configured to generate two streams of the input documents. One stream is fed to the Clean Missing Values Snap, and the other is fed to the Profile Snap. Below is an output preview of the Copy Snap, this is the data input for the Clean Missing Values Snap.
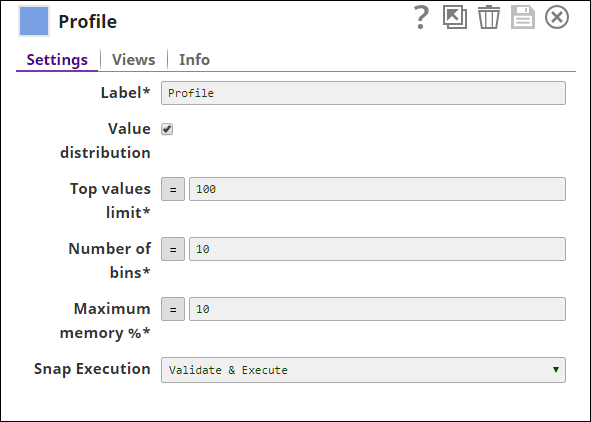
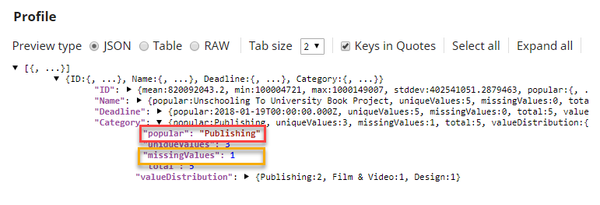
One of the documents does not have its corresponding value in the $Category field. For smaller datasets it is easy to identify if there are any values missing. For large datasets it is easier to identify missing values using the Profile Snap. Since the Clean Missing Values Snap also requires the data statistics of the input when selecting Impute with Popular or Impute with Average in the Rule property, using a Profile Snap is always helpful. In this case, the $popular field in the Profile Snap's output is used. The Profile Snap is configured as shown below:
Based on its configuration, the Profile Snap has the following output:
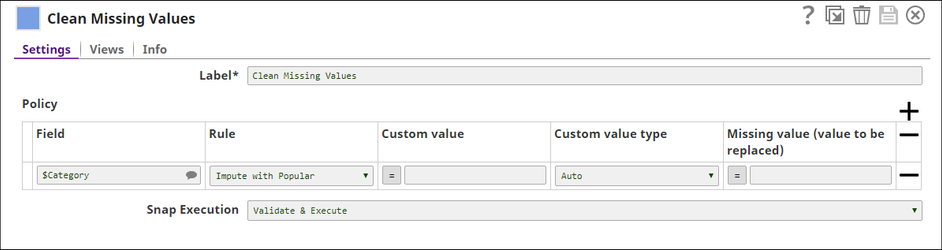
This output denotes that the input documents have one missing value in the $Category field, and the most popular value is Publishing. The Clean Missing Values Snap uses this value to handle the missing value in the document. The output from the Copy Snap (data) and the output from the Profile Snap (statistics) serve as the input for the Clean Missing Values Snap. This Snap is configured as shown below:
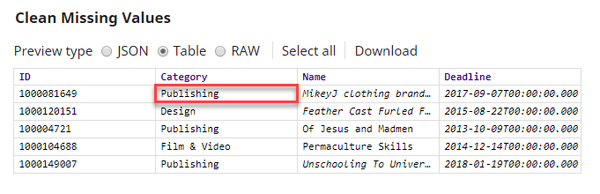
Based on the Snap's configuration, missing values in the $Category field are handled by the Snap using Impute with Popular as the rule. The Snap treats absence of values, null, and whitespaces as missing values. The Snap uses the value of the $popular field in the Profile Snap's output to handle missing values in the $Category field. The output of the Snap is as shown below:
You may write the output from the Clean Missing Values Snap into another file using the File Writer Snap. Download this pipeline. |
Downloads
| Multiexcerpt include macro | ||||
|---|---|---|---|---|
|
| Attachments | ||
|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|