Profile
- Kalpana Malladi
- Mohammed Iqbal
- Anand Vedam
On this Page
Overview
This is a Transform type Snap that computes statistics of the incoming data. Each field can be either numeric or categorical, you can use the Type Converter Snap to change the data type appropriately. This is helpful in deriving a statistical analysis of the data in datasets.
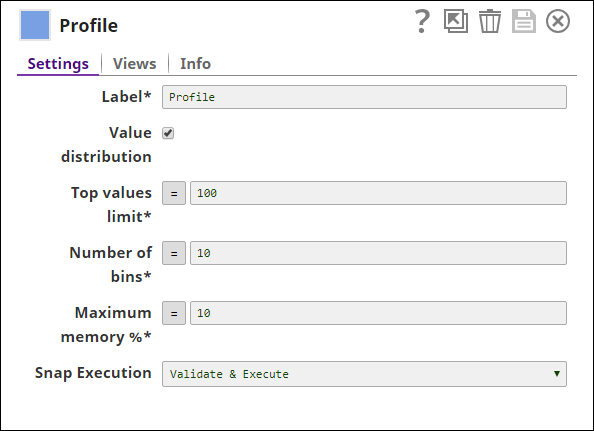
The Snap also has an optional second output view. When enabled, this view outputs an HTML file that is a graphical visualization of the first output. If you enable the Value distribution property, the value distribution of each class is also included in the output.
Output without value distribution:
Input and Output
Expected input: The dataset as a document stream.
Expected output: Statistical details of the dataset. Computation is different based on the type of fields.
- First Output: Statistical details of the dataset. Computation is different based on the type of fields.
- For categorical fields, the following is computed:
- popular: The most popular value
- total: The total number of documents in the dataset
- unique values: The number of unique values
- missing values: The number of whitespaces, null values, and missing values
- value distribution: The distribution of values. It is presented with value-frequency pairs. This is not shown if the Value distribution property is not selected.
- For numerical fields, the following is computed:
- mean: Average value
- min: Minimum value
- max: Maximum value
- sd: Standard deviation
- popular: The bin with the highest number of data (if binning is enabled) or the most popular value (if binning is disabled).
- total: The total number of documents in the dataset
- unique values: The number of unique values
- missing values: The number of missing values
- value distribution: The distribution of bins (if number of bins is greater than 0) or values (if number of bins is 0). It is presented with bin/value-frequency pairs. This is not shown if the Value distribution property is not selected.
- For categorical fields, the following is computed:
- Second Output: Optional. HTML-version of the output from the first output view.
Expected upstream Snaps: Any Snap that generates documents. For example, CSV Generator, JSON Generator, or a combination of File Reader and JSON Parser.
Expected downstream Snaps: Any Snap that accepts a document input. For example, Mapper.
Prerequisites
The input document must not have a nested structure.
Configuring Accounts
Accounts are not used with this Snap.
Configuring Views
Input | This Snap has exactly one document input view. |
|---|---|
| Output | This Snap has at most two document output views. |
| Error | This Snap has at most one document error view. |
Troubleshooting
None
Limitations and Known Issues
None
Modes
- Ultra Pipelines: Does not work in Ultra Pipelines.
Snap Settings
| Label | Required. The name for the Snap. Modify this to be more specific, especially if there are more than one of the same Snap in the pipeline. |
|---|---|
| Value distribution | If selected, the Snap includes the value distribution of the fields in the output. Default value: Selected |
| Top values limit | Required. This property is applicable only to the categorical fields. However, if binning is disabled, this property is also applied to numeric fields. This property limits the number of value-frequency pairs in the value distribution. For example, if the value in this property is 2, then the Snap lists two most-popular values in the dataset along with the number of documents with those values. Default value: 100 Configure this as 0 to include all values. |
| Number of bins | Required. This property is applicable only to the numerical fields in the dataset. It specifies the number of bins. Binning is a method of splitting the data space into N-equally sized ranges where N is the number of bins. Default value: 10 Configure this as 0 to disable binning. |
| Maximum memory % | Required. The maximum portion of the node's memory, as a percentage, that is utilized to buffer the incoming dataset. If this percentage is exceeded then the dataset is written to a temporary local file. This configuration is useful in handling large datasets without over-utilization of the node memory. The minimum default memory to be utilized by the Snap is set at 100 MB. Default value: 10 |
Temporary Files
During execution, data processing on Snaplex nodes occurs principally in-memory as streaming and is unencrypted. When larger datasets are processed that exceeds the available compute memory, the Snap writes Pipeline data to local storage as unencrypted to optimize the performance. These temporary files are deleted when the Snap/Pipeline execution completes. You can configure the temporary data's location in the Global properties table of the Snaplex's node properties, which can also help avoid Pipeline errors due to the unavailability of space. For more information, see Temporary Folder in Configuration Options.Examples
Computing Statistics
This example demonstrates how the Profile Snap is used to compute data statistics.

Download this pipeline
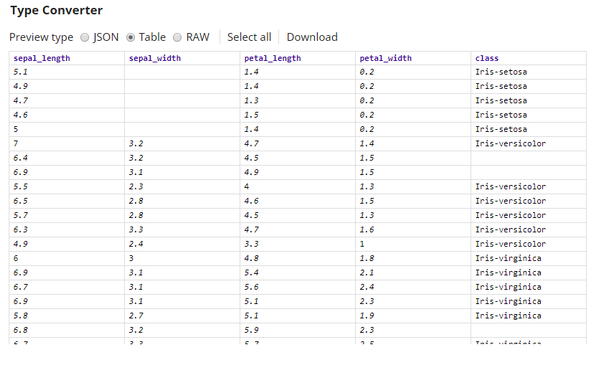
The input is a CSV document generated by the CSV Generator Snap. This document contains categorical ($class) as well as numeric ($sepal_length, $sepal_width, $petal_length, and $petal_width) fields. There are also some values missing. Since the output from the Profile Snap depends upon the data types in the input, a Type Converter Snap is added downstream so that all data types are correct. The Type Converter Snap is configured to automatically convert data types based on the field's values. Below is a preview of the output from the Type Converter Snap, this serves as the input for the Profile Snap:
The Profile Snap is configured as shown below:
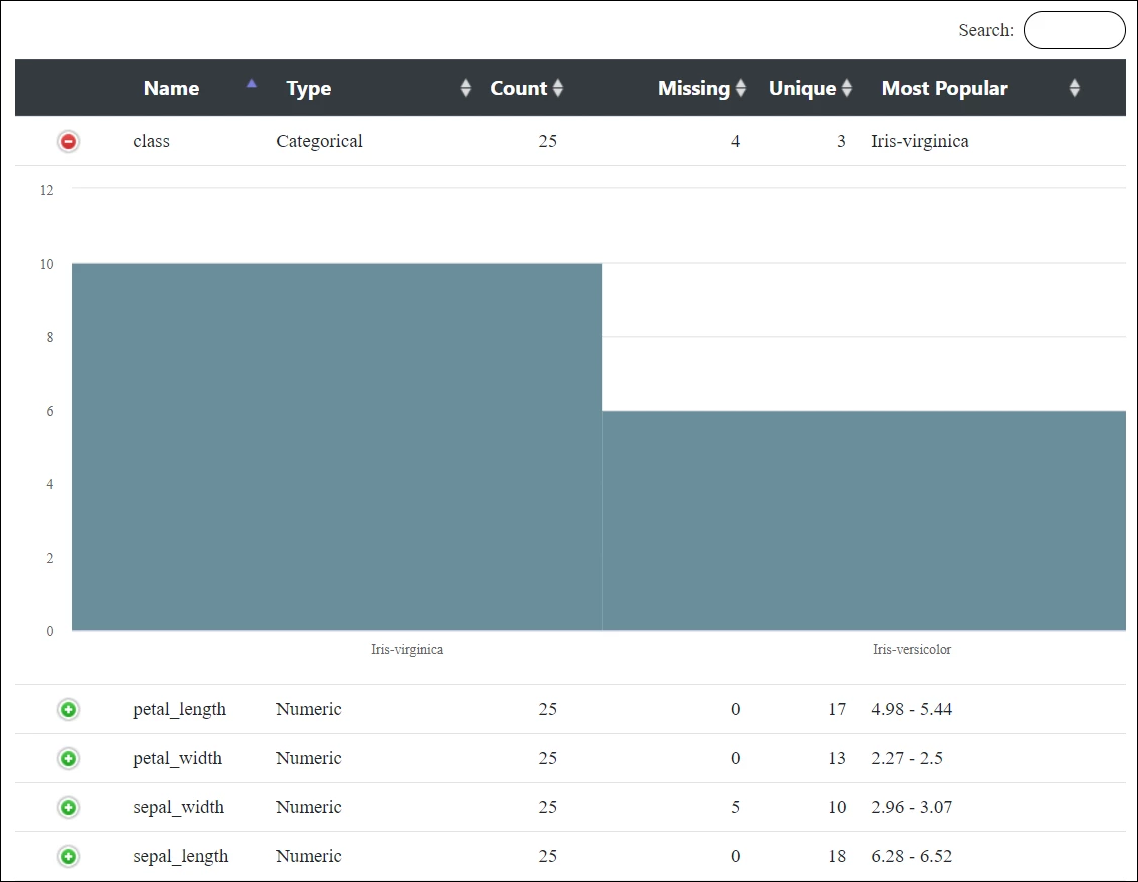
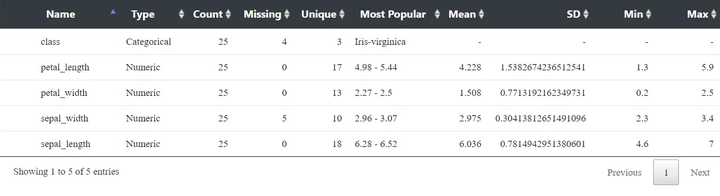
Statistics of the input documents are computed by the Profile Snap based on its configuration. This is shown in the output preview below:
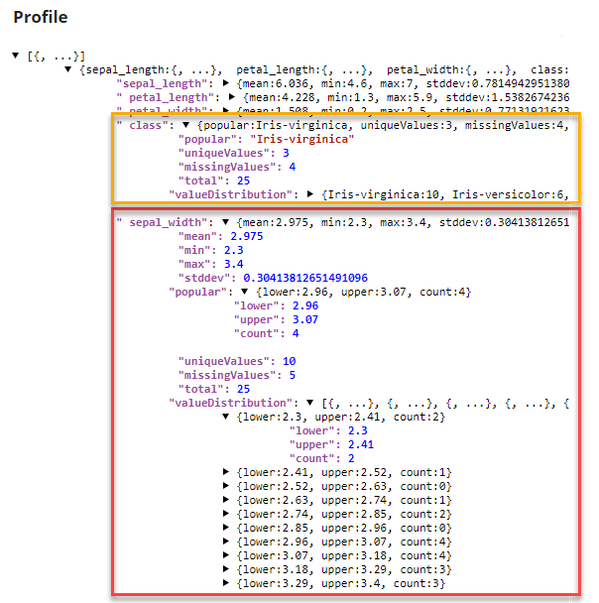
Statistics of the documents are computed by the Snap depending upon the type of fields.
The $class field being a categorical field, the statistics include:
- $popular
- $uniqueValues
- $missingValues
- $total
- $valueDistribution
The $sepal_length, $petal_length, $petal_width, and $sepal_width being numeric fields, the statistics include:
- $mean
- $min
- $max
- $stddev
- $popular
- $uniqueValues
- $missingValues
- $total
- $valueDistribution
See the Input and Output section above for a description of these fields.
The second output preview of the Profile Snap displays the report. The report is passed to a Document to Binary Snap and then to a File Writer Snap where you can save and download the report in HTML format. The preview of the report in HTML from the File Writer Snap is as follows:
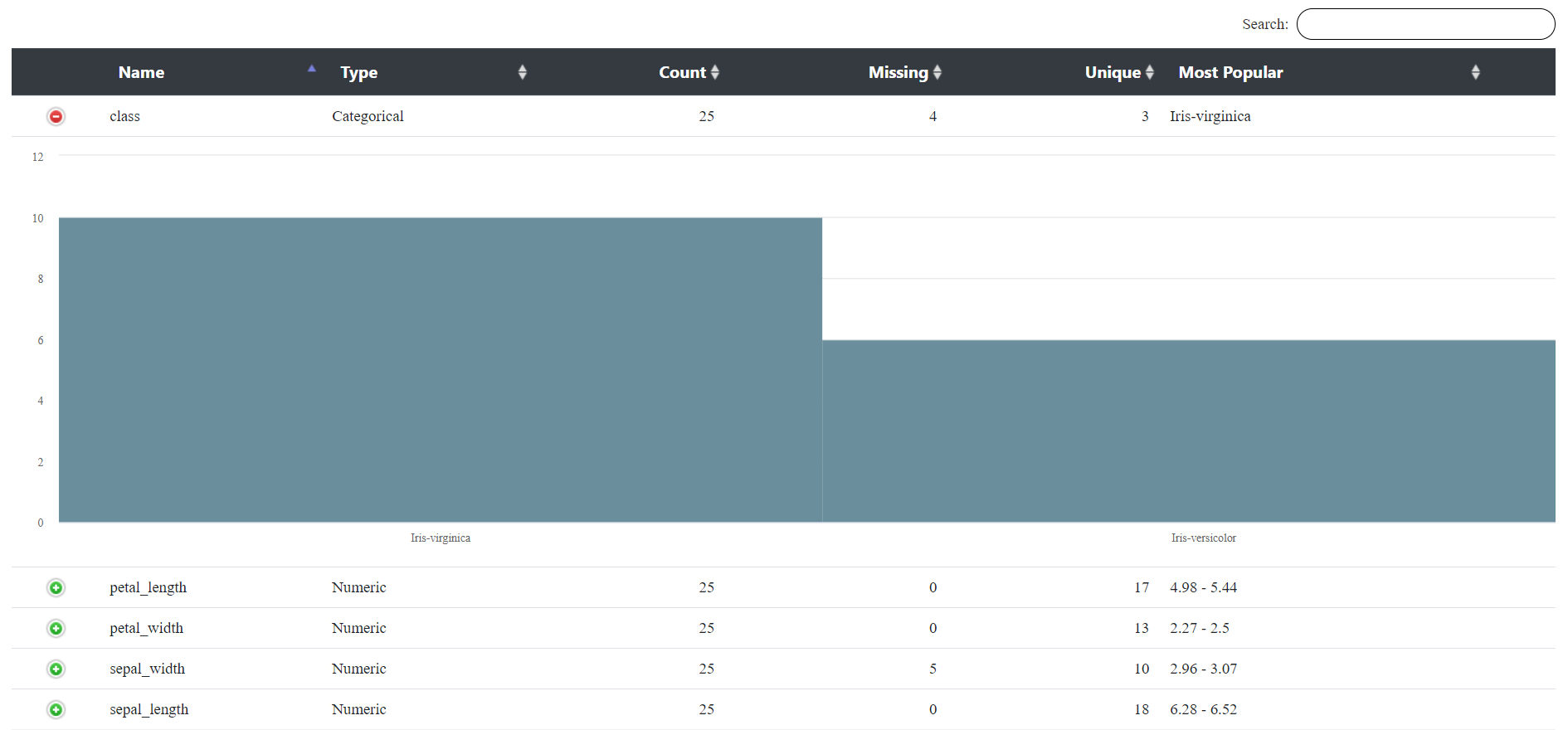
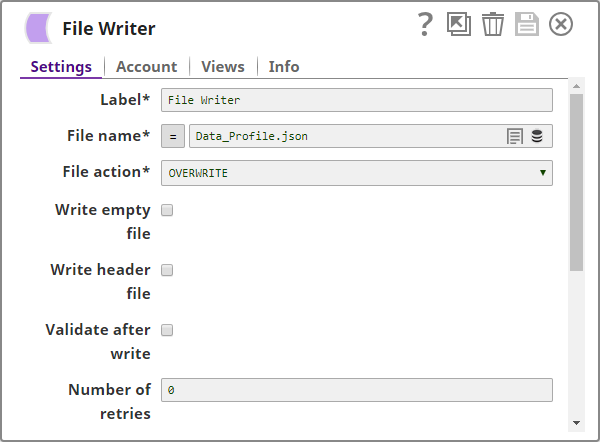
Since the Profile Snap does not work in Ultra Pipelines, you may write the output from the Profile Snap into a file using the JSON Formatter and File Writer Snap. In the Ultra Pipeline, use a File Reader Snap to read this profile. The File Writer Snap in this example is configured as shown below:
Download this pipeline
Additional Example
The following use case demonstrates a real-world scenario for using this Snap:
Downloads
Important steps to successfully reuse Pipelines
- Download and import the pipeline into the SnapLogic application.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.
Snap Pack History
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.