On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Write | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Description: | This Snap allows you to execute arbitrary SQL.
Valid JSON paths that are defined in the where clause for queries/statements will be substituted with values from an incoming document. Documents will be written to the error view if the document is missing a value to be substituted into the query/statement.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Prerequisites: | [None] | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Support and limitations: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Behavior Change |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Account: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Configuring PostgreSQL AccountAccounts for information on setting up this type of account. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Views: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Settings | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Label* | Required.The Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipelinePipeline. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
SQL statement* | If selected, the input document will be passed through Required.Specifies Specify the SQL statement to execute on the server. There are two possible scenarios that you encounter when working with SQL statements in SnapLogic.
For exampleExamples:
Default value: [None] |
Default Value: [None] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Query type | Select the type of query for your SQL statement (Read or Write). When Auto is selected, the Snap tries to determine the query type automatically. Default Value: Auto | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Pass through | Select this checkbox to pass the input document to the output view under the key 'original'. This property applies only to the Execute Snaps with SELECT statement. Default valueValue: Selected | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Ignore empty result | If selected, no document will be written to the output view when a SELECT operation does not produce any result. If this property is not selected and the Pass through property is selected, the input document will be passed through to the output view. Default valueValue: Not selected | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Advanced properties | By default, the advanced properties are not required and is an empty table property. Press "+" button to add an advanced property if a value other than the default value should be set. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Properties: Auto Commit | Enter true or false. This advanced property applies only if the SQL statement property is a SELECT query. If the SQL statement property is of other types (e.g. INSERT, UPDATE, SELECT ... INTO, etc.), this property value is ignored. If the Auto commit in the account is set to true, the PostgreSQL JDBC driver stores the entire result set of a SELECT query before it provides the result set to the Snap. If the result set is larger than the available system memory, it may cause an "Out of Memory" situation, rendering the Snaplex node inoperative. Therefore, the Snap automatically turns off the Auto commit during the SELECT operation so that the JDBC driver streams result sets from the server to the Snap (the number of rows in each fetch of results from the driver is as specified in the account's "Fetch size" property). However, in some use cases (e.g. when using a PostgreSQL replica), the feature of automatic turning-off auto-commit may cause errors in the SELECT query if an UPDATE or INSERT query is being executed simultaneously in another Snap elsewhere in the same pipeline. In such cases, this advanced property can be used with 'Auto commit' = true to override the setting and prevent the error from being thrown. The "'Auto commit' = true" entry will force the Auto commit to "True" during the SELECT query execution. If the "'Auto commit' = true" entry causes out of memory because of the result set of SELECT query being larger than the available system memory, instead of using this advance property, the Fetch size property in the account can be used to prevent both out of memory and other errors. The value of Fetch size should be large enough to avoid the SELECT query error and small enough to prevent out of memory. Also, in such case, the larger the Fetch size is, the higher performance of the SELECT query operation. Default value: empty (null) If 'Auto commit' is not selected in the Advanced properties, the state of 'Auto commit' in the account will remain unchanged. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Number of retries | Specify the maximum number of retry attempts the Snap must make in case there is a network failure and is unable to read the target file. The request is terminated if the attempts do not result in a response.
Ensure that the local drive has sufficient free disk space to store the temporary local file. Default Value: 0
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Retry interval (seconds) | Specifies the time interval between two successive retry requests. A retry happens only when the previous attempt resulted in an exception. Default Value: 1 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Auto commit | Select one of the options for this property to override the state of the Auto commit property on the account. The Auto commit at the Snap-level has three values: True, False, and Use account setting. The expected functionality for these modes are:
Default Value: Use account setting
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
.png?version=1&modificationDate=1489886486706&cacheVersion=1&api=v2)
Troubleshooting
| Error | Reason | Resolution |
|---|---|---|
Pipeline is no longer running. | When you use numerous self-joins in SQL SELECT statements with bind values, the Snap is likely to fail after the 11th statement. | Use either of the following workaround solutions to avoid Pipeline failure:
|
Examples
Inserting a record in a table using stored procedure in PostgreSQL-Execute Snap
Stored procedure:
A stored procedure is a named set of pre-written instructions or commands that are saved in a database. Instead of giving instructions whenever you want to perform an operation like inserting, updating, fetching, or deleting records, you write them down in a procedure. Then, whenever you need to do that specific task again, you call the stored procedure.
This example pipeline demonstrates how to create a stored procedure and call the stored procedure to insert a record in an existing table.
Step 1: Configure the PostgreSQL-Execute Snap with Create Procedure statement to create a stored procedure, genre_insert_data, to insert GenreIdand Namein the Genre table.
a. CREATE OR REPLACE PROCEDURE public.genre_insert_data("GenreId" integer, "Name" character varying ) statement creates a stored procedure that has INPUT parameters GenreId and Name values.
b. INSERT INTO "public"."Genre" VALUES ("GenreId", "Name"); this statement inserts the values in the Genre table.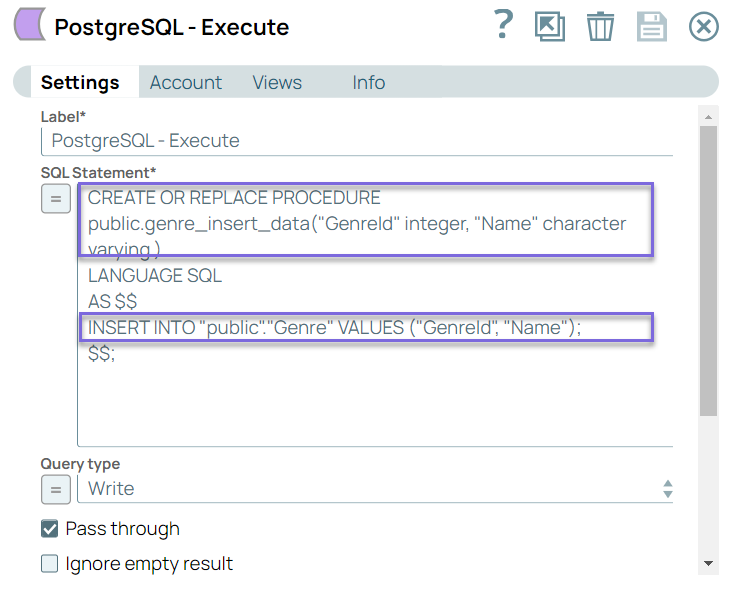
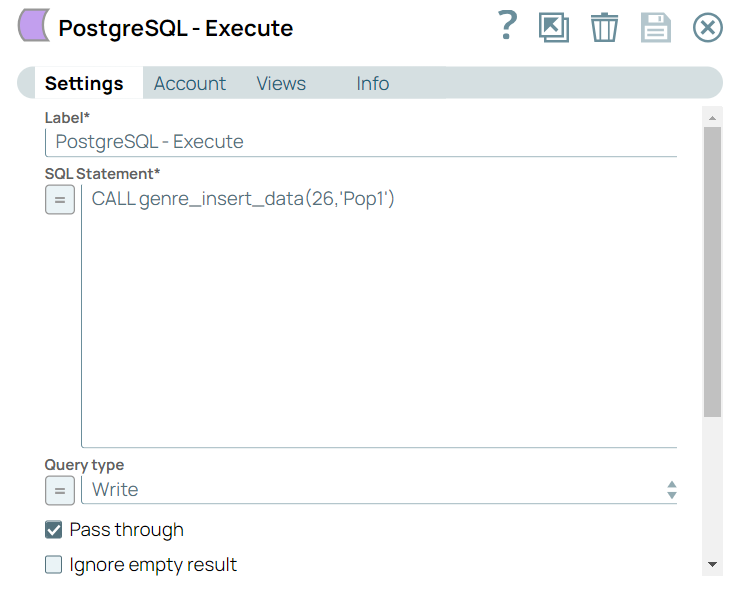
Step 2: Configure the PostgreSQL-Execute Snap with a call statement to trigger the stored procedure by passing values for GenreId and Name.
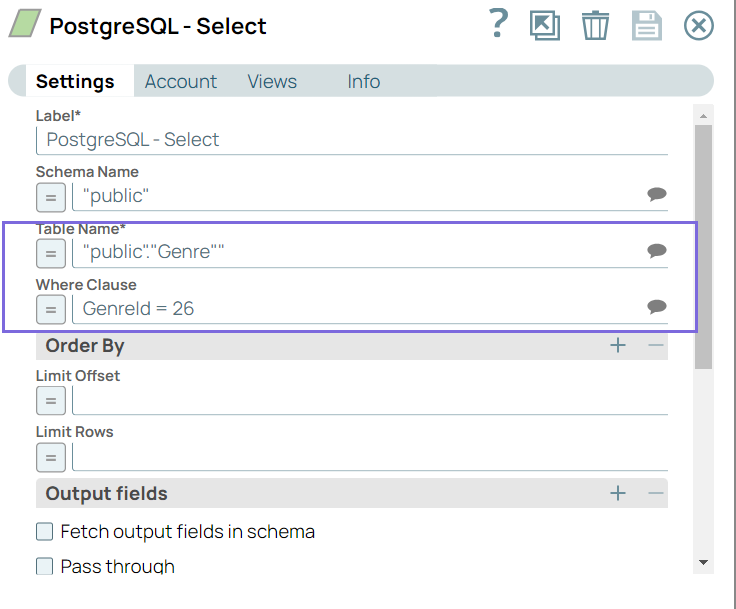
Step 3: Configure the Table Name and GenreId in the PostgreSQL-Select Snap as follows to fetch the inserted record to verify if the record has been inserted.
Step 4: On validation, the PostgreSQL-Select Snap fetches the previously inserted record.
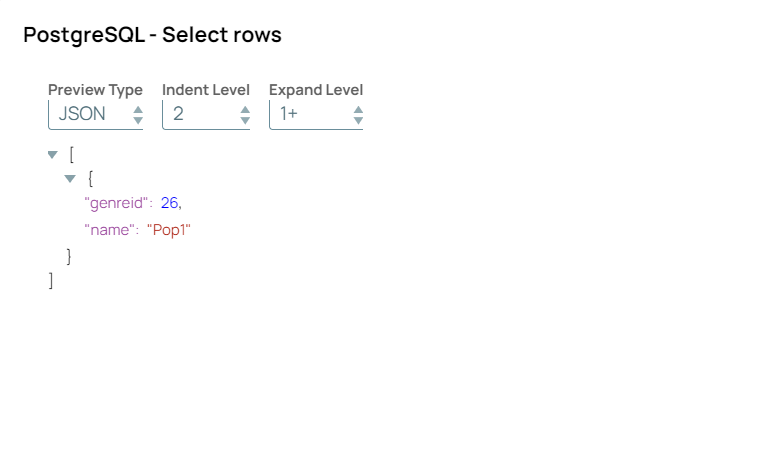
The following single-Snap Pipeline runs an SQL query containing a JOIN command to collate data between two PostgreSQL tables.

Let us consider the following tables in a PostgreSQL DB. Notice that the column employee_id is common between these tables.
| Table 1: AVemployees | Table 2: AVempsalary |
|---|---|
| 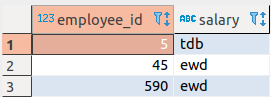 |

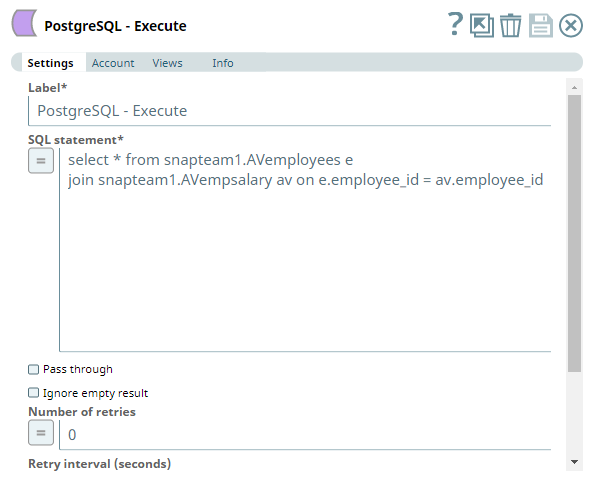
The Snap accesses the PostgreSQL tables using a valid account and runs an SQL query that contains a JOIN command based on the following settings:
The output preview after executing this Pipeline displays the result for the SQL query.
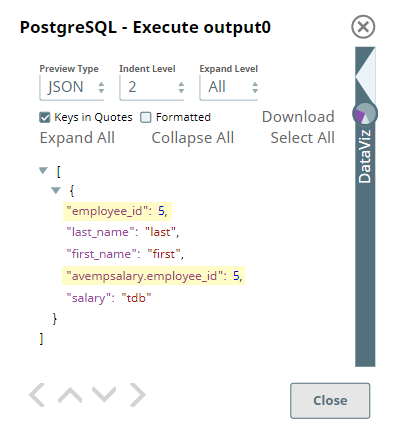
Upon joining the two tables as defined in the SQL query, we can see the employee_id column in the second table is prefixed with its table name AVempsalary to differentiate it from the column with the same name in the AVemployees table. This is how the PostgreSQL - Execute Snap handles column with conflicting names in tables when the SQL statement contains a JOIN command.
Downloads
Multiexcerpt include macro name download_instructions page OpenAPI
| Attachments | ||
|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|