...
...
...
...
...
...
...
On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Problem Scenario
Machine Learning is has been showing promising results in various technology domainsapplications. Healthcare is one of them. Machine Learning can accurately help doctors diagnose patients accurately. In this use case, we are trying to use machine learning algorithms to predict the progression of diabetes in patients.
Description
The In this paper, the baseline measurements: Age, Sex, BMI, BP, and 6 Serum Measurements (S1, S2,...S6) of 422 patients is available in this paperwere collected. One year after that, a measure of diabetes progression was collected. Our goal here is to teach the machine to predict the diabetes progression based on these 10 measurements. The live demo is available at our Machine Learning Showcase.The following
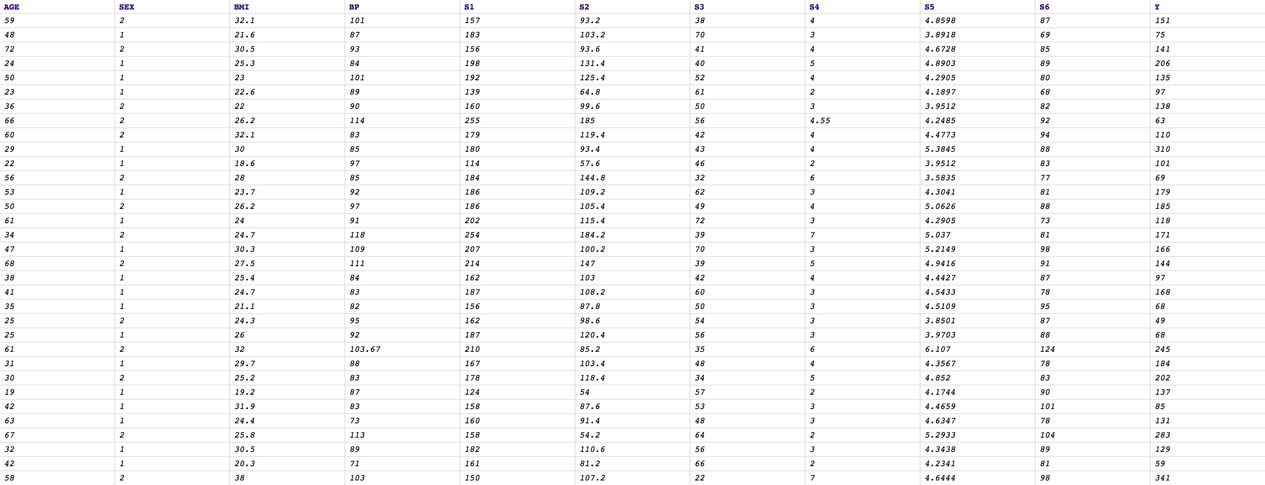
Below screenshot is the preview of this dataset. There are 10 measurements and diabetes progression represented as $Y which is the rightmost field.
The live demo is available at our Machine Learning Showcase.

Objectives
- Cross - Validation: Use the Cross Validator (Regression) Snap from ML Core Snap Pack to perform a 10-fold cross - validation with Linear Regression algorithm. K-Fold Cross Validation is a method of evaluating machine learning algorithms by randomly separating a dataset into K chunks. Then, K-1 chunks will be used to train the model which is will be evaluated on the last chunk. This process repeats K times and the average error and other statistics are computed.
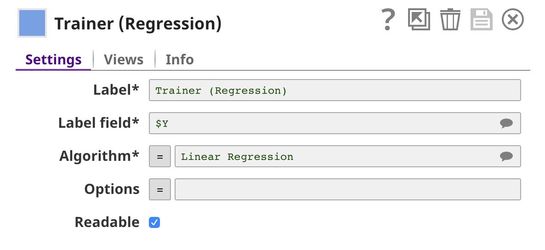
- Model Building: Use the Trainer (Regression) Snap from ML Core Snap Pack to build the linear regression model based on the training set of 392 samples; then serialize and store.
- Model Evaluation: Use Predictor (Regression) Snap from ML Core Snap Pack to apply the model on the test set containing the remaining 50 samples and compute error.
- Model Hosting: Use Predictor (Regression) Snap from ML Core Snap Pack to host the model and build the API using Ultra Task.
- API Testing: Use REST Post Snap to send a sample request to the Ultra Task to make sure the API works is working as expected.
To accomplish the objectives, we We are going to build 5 pipelines: Cross Validation, Model Building, Model Evaluation, Model Hosting, and API Testing; and an Ultra Task to accomplish the above objectives. Each of these pipelines is described in the Pipelines section below.
Pipelines
Cross
...
Validation
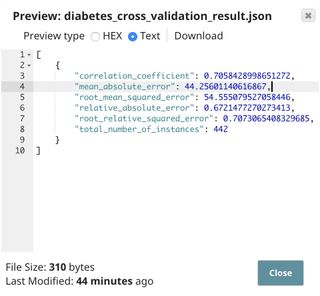
In this pipeline, we use the Cross Validator (Regression) Snap to perform a 10-fold cross validation using a linear regression algorithm. The result shows that the overall mean absolute error is 44.256.
In this pipeline,
The File Reader Snap reads the dataset which is in CSV format.
...
Then, the CSV Parser Snap converts binary data into documents.
...
Since the types of documents from CSV Parser Snap are text represented by String data type
...
, we use Type Converter Snap to automatically derive types of data. In this case, the data is converted into either BigInteger or BigDecimal representing numeric values.
...
Then, the Cross Validator (Regression) Snap performs 10-fold cross validation using
...
linear regression algorithm.
| View file | ||||
|---|---|---|---|---|
|
...


Finally, we use the JSON Formatter Snap and File Writer Snap to save the result.
...
In this case, we save the result on SnapLogic File System (SLFS) which can be previewed by clicking at the document icon next to the File name in the File Writer Snap or download from the Manager page. The screenshot below shows that the overall mean absolute error is 44.256.
...
You may try other regression algorithms in the Cross Validator (Regression) Snap and see which algorithm performs the best on this dataset.


Model Building
In this pipeline, we use the Trainer (Regression) Snap to build the model from the training set using the linear regression algorithm.
The File Reader Snap reads the training set containing 392 samples.
...
Then, the CSV Parser Snap converts binary data into documents.
...
Since the types of documents from CSV Parser Snap are text represented by String data type, we use the Type Converter Snap to automatically derive types of data.
...
Then, the Trainer (Regression) Snap trains the model using
...
linear regression algorithm.
...
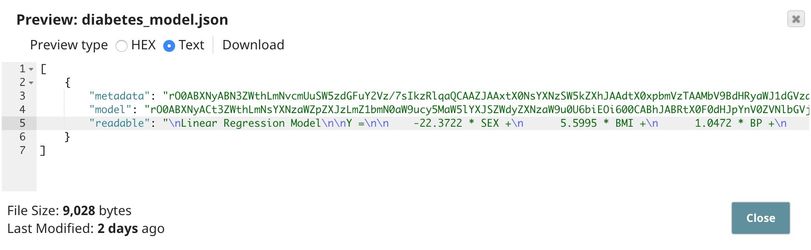
The model consists of two parts: metadata describing the schema (field names and types) of the dataset, and the actual model. Both metadata and model are serialized. If the Readable option in the Trainer (Regression) Snap is
...
selected, the readable model will be generated.
...
Finally, the model is written as a JSON file on the SLFS using
...
JSON Formatter Snap and
...
File Writer Snap.




Model Evaluation
In this pipeline, the model generated above is evaluated against the test set.
The Predictor (Regression) Snap has two input views
...
. The first input view is for the test set
...
. The second input view accepts the model generated in the previous pipeline. In this case, the Predictor (Regression) Snap predicts the progression of diabetes.
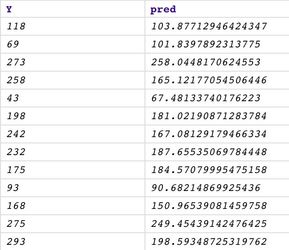
The predictions from the Predictor (Regression) Snap are merged with the real diabetes progression (answer) from the Mapper Snap which extracts the $Y field from the test set.
...
The result of merging is displayed in the screenshot below
...
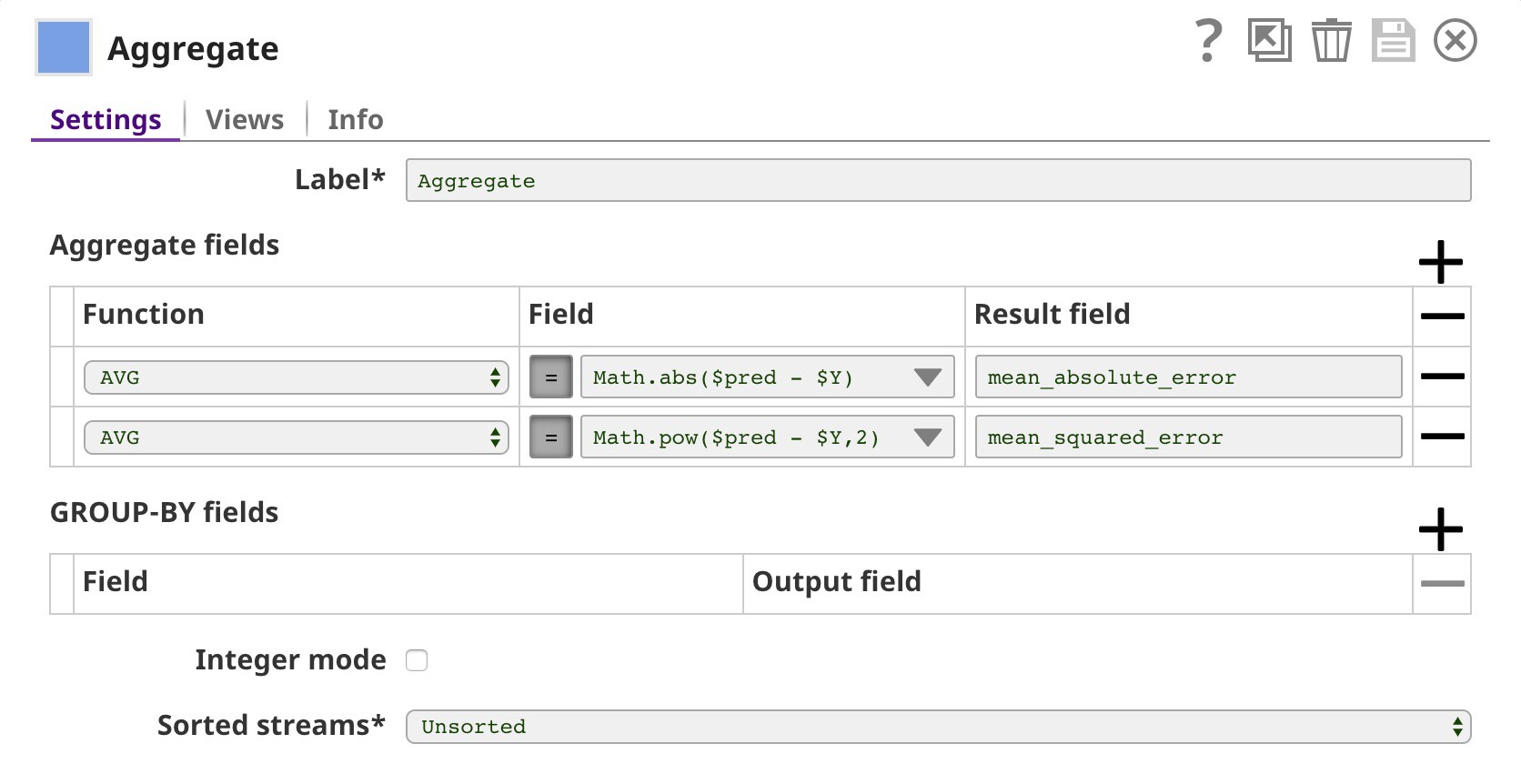
(lower-left corner). After that, we use the Aggregate Snap to compute mean absolute error and mean squared error which is 32.804 and 1793.410 respectively.
...
The result is then saved using CSV Formatter Snap and File Writer Snap.
...
...
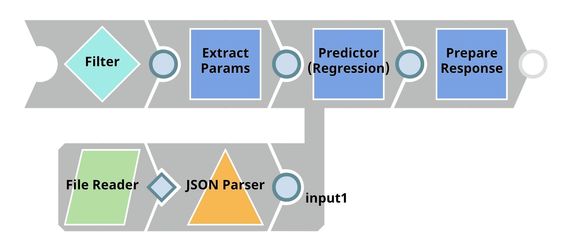
Model Hosting
This pipeline is scheduled as an Ultra Task to provide a REST API that is accessible by external applications. The core components of this pipeline are File Reader, JSON Parser and Predictor (Regression) Snaps that are the same as in the Model Evaluation pipeline. In this pipeline:
...
Instead of taking the data from the test set, the Predictor (Regression) Snap takes the data from API request.
...
The Filter Snap is used to authenticate the request by checking the token that can be changed in pipeline parameters.
...
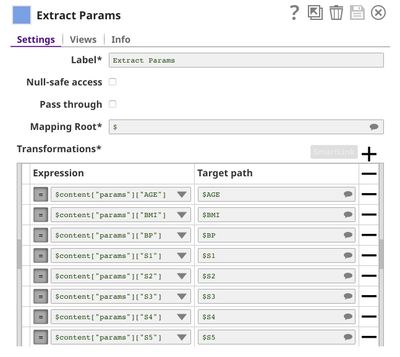
The Extract Params Snap (Mapper) extracts the required fields from the request.
...
The Prepare Response Snap (Mapper) maps from prediction to $content.pred which will be the response body. This Snap also adds headers to allow Cross-Origin Resource Sharing (CORS).




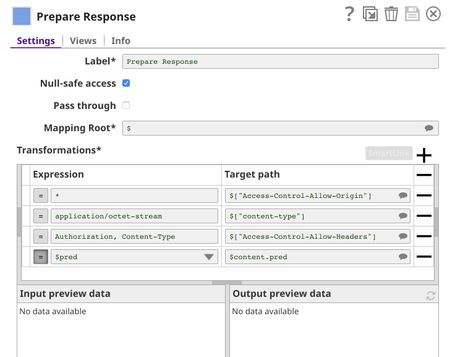
Building API
To deploy this pipeline as a REST API, perform the following:
...
click the calendar icon in the toolbar. You can
...
use either Triggered Task or Ultra Task.
...
Triggered Task is good for batch processing since it starts a new pipeline instance for each request. Ultra Task is good to provide REST API to external applications that require low latency.
...
In this case, the Ultra Task is preferable.
...
Bearer token is not needed here since the Filter Snap
...
will perform authentication inside the pipeline.
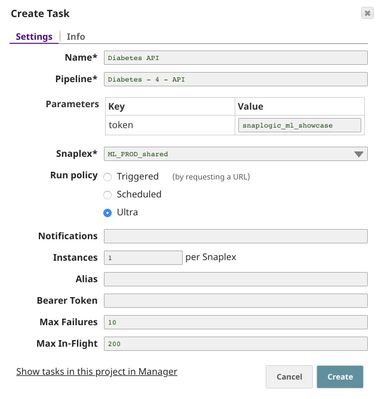
In order to get the URL, click Show tasks in this project in Manager in the Create Task window.
...
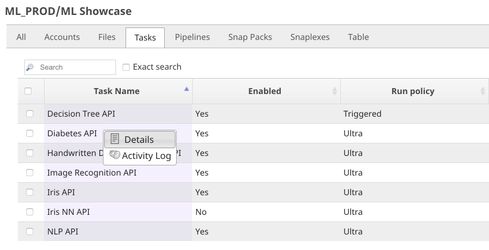
Click the small triangle next to the task, and then click Details.
...
The task detail shows up with the URL
...
:
...
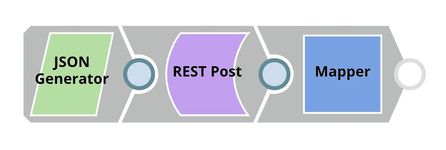
API Testing
In this pipeline:A , a sample request is generated by the JSON Generator. The The request is sent to the Ultra Task by REST Post Snap. The Mapper Snap is used to extract the response which is in $response.entity.
Following Below is the content of the JSON Generator Snap. It contains $token and $params which will be included in the request body sent by REST Post Snap.

The REST Post Snap gets the URL from the pipeline parameters. Your URL can be found in the Manager page. In some cases, it is required to check Trust all certificates in the REST Post Snap.


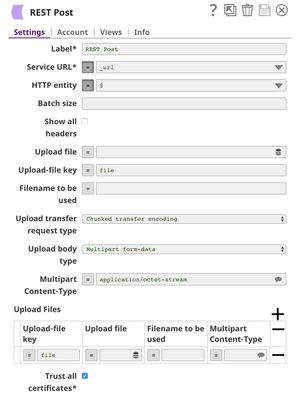
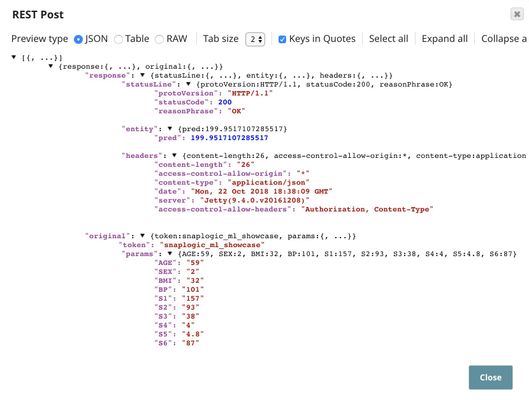
The output of the REST Post Snap is shown below. The last Mapper Snap is used to extract $response.entity from the request. In this case, the predicted diabetes progression is 199.95.
Downloads
| Multiexcerpt include macro | ||||
|---|---|---|---|---|
|
| Attachments | ||
|---|---|---|
|