In this article
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
You can use the Kafka Producer Snap to send messages to a Kafka topic.
Prerequisites
- Valid client ID.
- A Kafka server with a valid account and the required permissions.
Support for Ultra Pipelines
Works in Ultra Pipelines.
Limitations and Known Issues
None.
Snap Input and Output
| Input/Output | Type of View | Number of views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
| Input | Document |
|
| A key/value pair for the Kafka message. |
| Output | Document |
|
| Kafka message records. Example,
|
Snap Settings
| Parameter Name | Data Type | Description | Default Value | Example | ||||
|---|---|---|---|---|---|---|---|---|
| Label | String | Required. The name for the Snap. You can modify the default name to be specific and meaningful, especially if you have more than one of the same Snaps in your pipeline. | Kafka Producer | Producer | ||||
| Client ID | String/Expression | Specify the Client ID to be used in the Kafka message. If you do not specify a Client ID, a random string is used. This Client ID is used for correlating the requests sent to the brokers with each client. | N/A | testclient001 | ||||
| Topic | String/Expression/Suggestion | Specify the topic to publish the message. | N/A | t1 | ||||
| Partition Number | String/Expression/Suggestion | Specify the partition number in which the messages should be published. | N/A | 0 | ||||
| Message Key | String/Expression | Enter the key for the message to be sent out. | N/A | customerID | ||||
| Message Value | String/Expression | Required. Provide the value for the corresponding message key. | N/A |
| ||||
| Timestamp | String/Expression | Specify a timestamp for the message in number, string, or date format.
| CreateTime | Date.parse($timestamp, "yyyy-MM-dd'T'HH:mm:ss.SSS'Z'") | ||||
| Key Serializer | Drop-down list | Select the target data type for the Key Serializer of each record. The available options are:
| String | JSON | ||||
| Value Serializer | Drop-down list | Choose the target data type for the Value Serializer of each record. The available options are:
| String | ByteArray | ||||
Headers | Use this field set to define an optional set of headers for each record. Click
| |||||||
| Key | String/Expression | Specify a name to use for the Header. You can add multiple headers with the same key in either of the following ways:
| N/A | City | ||||
| Value | String/Expression | Specify a value for the header. | N/A | SFO | ||||
| Serializer | Drop-down list | Select a Serializer for the header to convert the value from a specific data type such as string or Int32. | String | ByteArray | ||||
| Acknowledgements | Drop-down list | Select the type of acknowledgment for the message, which determines the number of acknowledgments that the Producer requires the server to have received before considering a request to be complete.
| 1 - Send with leader acknowledgment | all - Send with full acknowledgement | ||||
| Batch Size (bytes) | Integer/Expression | Specify the number of bytes that are received before messages are sent to the server. | 16384 | 15000 | ||||
| Linger Time (milliseconds) | Integer/Expression | Specify the linger time for the messages to be sent. Linger time is the time in milliseconds, the Producer Snap should wait before it sends | 0 | 1 | ||||
| Retries | Integer/Expression | Set the total number of times to attempt a message delivery in case of failure.
| 0 | 3 | ||||
| Preserve Message Order With Retry | Check box | Select this check box to resend the messages in the same order each time.
| Not selected | Selected | ||||
| Compression Type | Drop-down list | Choose the compression type before sending the messages. The available options are:
| None | GZIP | ||||
| Send Synchronously | Check box | Select this check box to send each message synchronously. The consumer blocks the message until metadata from the broker is received. | Not Selected | Selected | ||||
| Output Records | Check box | Select this check box to include the record’s data and metadata in each output document, that is, key, value, headers, and timestamp. | Not Selected | Selected | ||||
| Message Publish Timeout (milliseconds) | Integer/Expression | Specify the timeout value in milliseconds to publish a message. If the Snap fails to publish the message until the specified time, a timeout error appears. | 60000 | 60000 | ||||
| Snap Execution | Drop-down list | Select one of the three modes in which the Snap executes. Available options are:
| Execute only | Validate & Execute | ||||
Example
Sending Documents to a Kafka Topic Using Kafka Producer Snap
This example Pipeline demonstrates how we can send documents to a Kafka topic using the Kafka Producer Snap. We use the Sequence Snap to enable the Pipeline to send documents in large numbers.
First, we configure the Sequence Snap to send 1000 documents. Hence, we set the Initial value as 1 and Number of documents as 1000.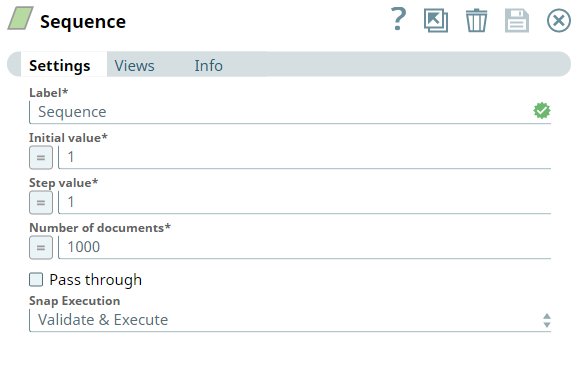
Next, we configure the Kafka Producer Snap to send the documents to the Topic named SampleKafkaTopic. We set the Partition number to 0, to let the broker decide which partition to use.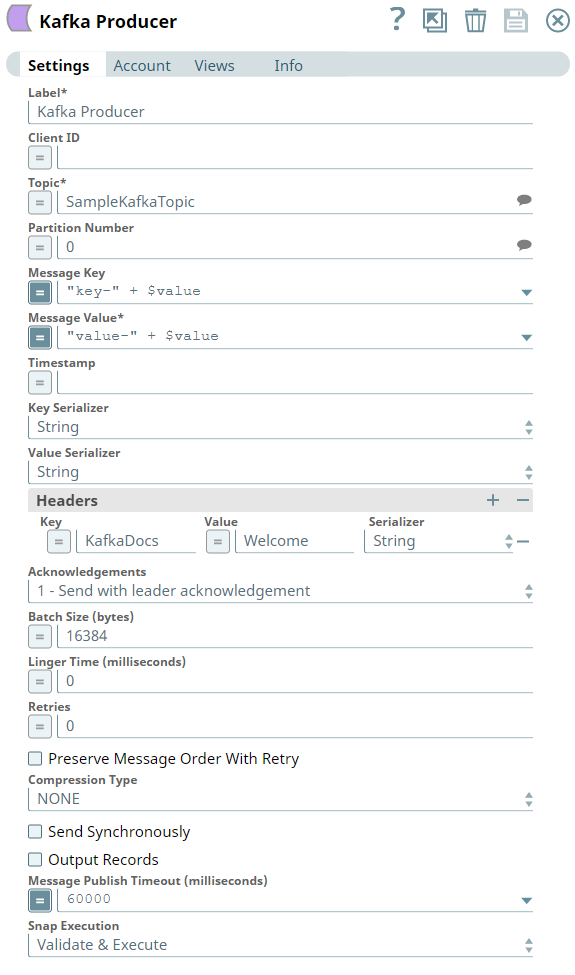
Upon successful validation, the Pipeline displays the output preview as shown below: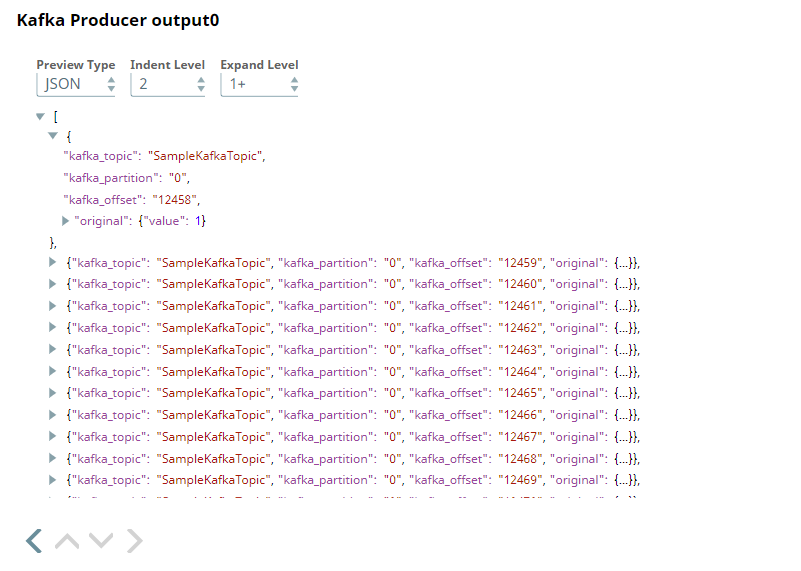
Downloads
| Note | ||
|---|---|---|
| ||
|
| Attachments | ||
|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|