On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Read | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap enables you to fetch data from a database by providing a table name and configuring the Snowflake connection. The Snap produces the records from the database on its output view which can then be processed by a downstream Snap. JSON paths can be used in a query and will have values from an incoming document substituted into the query. However, documents missing values for a given JSON path will be written to the Snap's error view. After a query is executed, the query's results are merged into the incoming document overwriting any existing keys' values. The original document is output if there are no results from the query. Queries produced by the Snap have an equivalent format:
If more powerful functionality is desired, then the Execute Snap should be used.
| |||||||||||||
| Prerequisites: |
Security Prerequisites: You should have the following permissions in your Snowflake account to execute this Snap: Usage (DB and Schema): Privilege to use database, role, and schema. The following commands enable minimum privileges in the Snowflake Console:
For more information on Snowflake privileges, refer to Access Control Privileges. | |||||||||||||
| Internal SQL Commands | This Snap uses the SELECT command internally. It enables you to query the database and retrieve a set of rows. | |||||||||||||
| Support and limitations: | Works in Ultra Pipelines. | |||||||||||||
| Account: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Snowflake Account for information on setting up this type of account. | |||||||||||||
| Views: |
| |||||||||||||
Settings | ||||||||||||||
Label* | Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. | |||||||||||||
Schema name | The database schema name. In case it is not defined, then the suggestion for the Table Name will retrieve all table names of all schemas. The property is suggestible and will retrieve available database schemas during suggest values. | |||||||||||||
| Table name* | Specify the table to execute the select query on. | |||||||||||||
| Where clause | Specify the where clause of the SELECT statement. This supports document value substitution (such as $person.firstname will be substituted with the value found in the incoming document at the path). | |||||||||||||
| Order by | Specify the columns in the order in which you want to sort the database. The default database sort order will be used. Examples:
| |||||||||||||
| Limit offset | Specify the offset for the limit clause. This is where the result set should start. | |||||||||||||
| Limit rows | Specify the number of rows to return from the query. | |||||||||||||
| Output fields* | Enter or select output fields for Snowflake SQL SELECT statement. To select all fields, leave it at default. | |||||||||||||
| Fetch Output Fields In Schema |
Default value: Not selected | |||||||||||||
Pass-through | If selected, the input document will be passed through to the output view under the key 'original'. Default value: Selected | |||||||||||||
| Ignore empty result | If selected, no document will be written to the output view when a SELECT operation does not produce any result. If this property is not selected and the Pass-through property is selected, the input document will be passed through to the output view. Default value: Not selected | |||||||||||||
| Match data types | Conditional. This field applies only when the Output fields field is provided with any values. If this checkbox is selected, the Snap tries to match the output data types the same as when the Output fields property is empty (SELECT * FROM ...). The output preview would be in the same format as the one when SELECT * FROM is implied and all the contents of the table are displayed. Default value: Not selected | |||||||||||||
| Number of Retries | Specify the maximum number of attempts to be made to receive a response. The request is terminated if the attempts do not result in a response. Default value: 0
| |||||||||||||
| Retry Interval (seconds) | Specify the time interval between two successive retry requests. A retry happens only when the previous attempt resulted in an exception. Default value: 1 | |||||||||||||
| Staging mode | Specify the location where you want the Snap to store in-flight records when using Retry. Valid options are:
Default value: In memory
| |||||||||||||
| Handle Timestamp and Date Time Data | Specify how the Snap must handle timestamp and date time data. The available options are:
Default value: Default Date Time format in UTC Time Zone
| |||||||||||||
| Manage Queued Queries | Select this checkbox to decide whether the Snap should continue or cancel the execution of the queued Snowflake Execute SQL queries when you stop the pipeline.
Default value: Continue to execute queued queries when the pipeline is stopped or if it fails | |||||||||||||
|
| |||||||||||||
| Note |
|---|
| For the 'Suggest' in the Order by columns and the Output fields properties, the value of the Table name property should be an actual table name instead of an expression. If it is an expression, it will display an error message "Could not evaluate accessor: ..." when the 'Suggest' button is clicked. This is because, at the time the "Suggest" button is clicked, the input document is not available for the Snap to evaluate the expression in the Table name property. The input document is available to the Snap only during the preview or execution time. |
Examples
The following example illustrates how to read table data using the Snowflake - Select Snap.
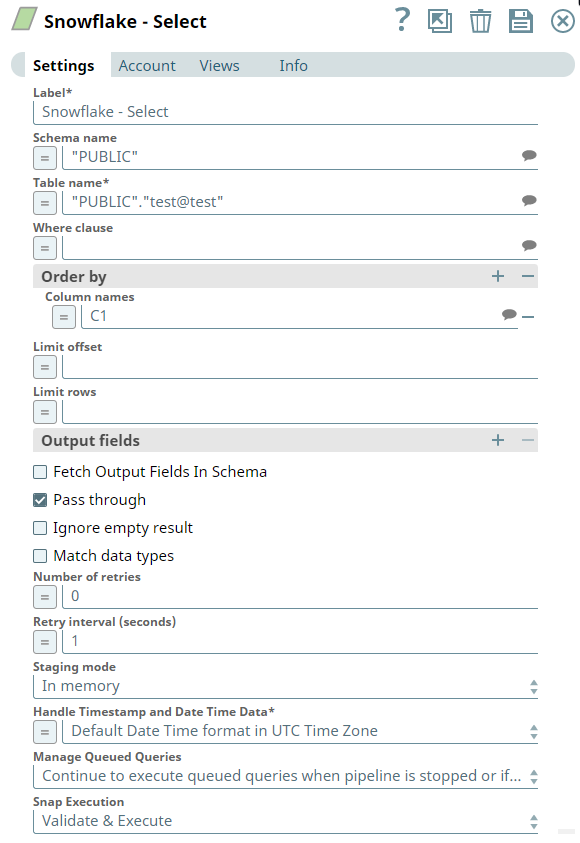
The above Snap reads test@test table data, and orders the results based on the C1 column. Additionally, it limits the results to only 10 rows.
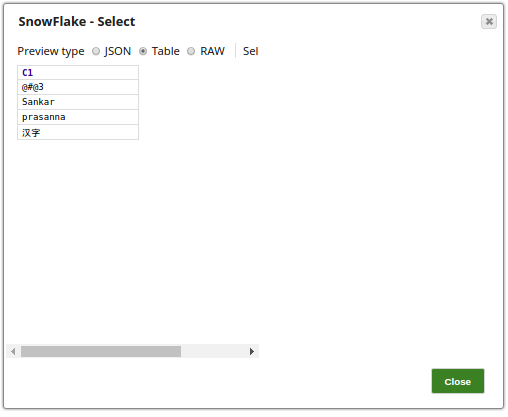
Successful execution of the Pipelines gives the following output in the preview:
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|