On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Write | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap executes a SQL Insert statement using the document's keys as the columns to insert to and the document's values as the values to insert into the columns. Table CreationIf the table does not exist when the Snap tries to do the insert, and the Create table property is set, the table will be created with the columns and data types required to hold the values in the first input document. If you would like the table to be created with the same schema as a source table, you can connect the second output view of a Select Snap to the second input view of this Snap. The extra view in the Select and Bulk Load Snaps are used to pass metadata about the table, effectively allowing you to replicate a table from one database to another. The table metadata document that is read in by the second input view contains a dump of the JDBC DatabaseMetaData class. The document can be manipulated to affect the CREATE TABLE statement that is generated by this Snap. For example, to rename the name column to full_name, you can use a Mapper (Data) Snap that sets the path $.columns.name.COLUMN_NAME to full_name. The document contains the following fields:
Expected Input and Output
| |||||||||||||
| Prerequisites: | [None] | |||||||||||||
| Support and limitations: | Works in Ultra Task Pipelines if batching is disabled. Known Issue: If database metadata from an upstream Snap contains geography column data such as modifiers, those modifiers may not be written to the target table. | |||||||||||||
| Account: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Configuring PostgreSQL Accounts for information on setting up this type of account. | |||||||||||||
| Views: |
| |||||||||||||
Settings | ||||||||||||||
Label* | Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||||||
Schema name | Specify the database schema name. Selecting a schema filters the Table name list to show only those tables within the selected schema.
Example: SYS | |||||||||||||
Table name* | Specify the table that the rows will be inserted into.
| |||||||||||||
Create table if not present |
Default value: Not selected | |||||||||||||
| Preserve case sensitivity | Select this checkbox to preserve the case sensitivity of the column names while performing the insert operation. If you do not select this option, then Snap converts the column names in the input document to match the column names in the target database table before inserting the values. The Snap checks for the following three conditions:
On the contrary, if you select this checkbox, the Snap does not convert the case of the column names and inserts the names as-is in the target database. Therefore, ensure that the column labels in the input document match the column labels in the target database table. Else, the Snap does not insert the values and displays an error. For example, if the column names (ID, Name) in the input document do not match the column names (Id, name) in the database, then the Snap does not insert the values and displays an error. | |||||||||||||
| Number of retries | Specify the maximum number of attempts to be made to receive a response. The request is terminated if the attempts do not result in a response. Default value: 0 | |||||||||||||
| Retry interval (seconds) | Specify the time interval between two successive retry requests. A retry happens only when the previous attempt resulted in an exception. Default value: 1 | |||||||||||||
|
| |||||||||||||
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|
Example
Inserting the Records Into an Existing Table in the Database
This example pipeline demonstrates how to insert the records into an existing table in the database using the PostgreSQL Insert Snap.
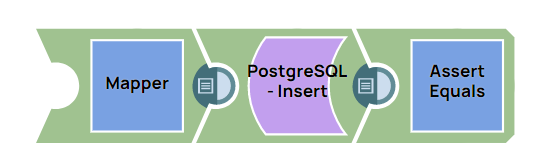
Step 1: Configure the Mapper Snap with the static or dynamic values you want to insert in the database for different variables.
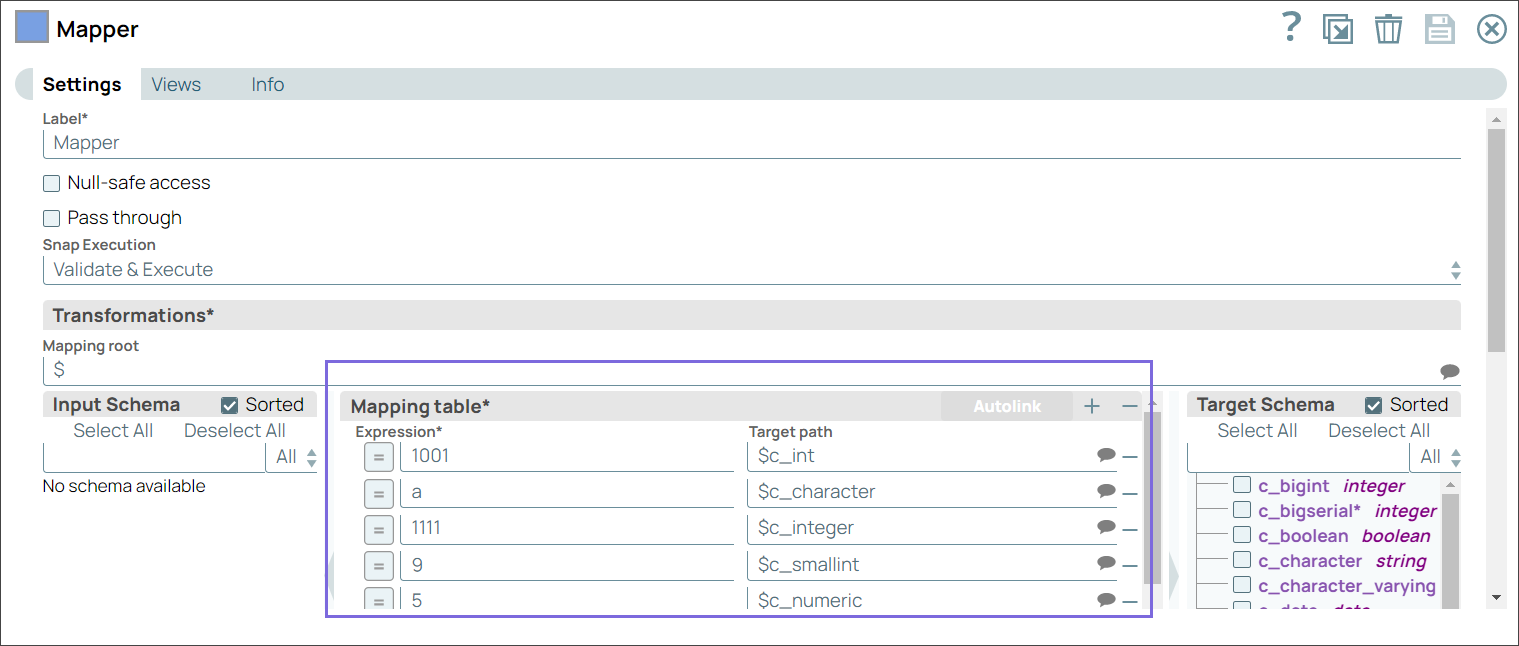
Step 2: Configure the PostgreSQL Insert Snap to insert the values in a table in the database.
Step 3: Validate the pipeline. A success message appears with all the values inserted in the database.
