On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Parse | |||||||
|---|---|---|---|---|---|---|---|---|
Description: | This Snap reads binary data from its input view, extracts field values based on the field configuration, and writes document data to its output view. | |||||||
| Prerequisites: | [None] | |||||||
| Support and limitations: | Ultra pipelines: Works in Ultra Pipelines. | |||||||
| Account: | Accounts are not used with this Snap. | |||||||
| Views: |
| |||||||
Settings | ||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||
Skip lines | Number of lines to skip at beginning of the data Example: 2 Default value: 0 | |||||||
Line separator | The character used to separate lines in the input. Leave empty to separate lines using new line character or specify the character used for separating lines. Default value: \n | |||||||
| Field configuration | Details to be filled for each field that is required from the input. | |||||||
Column names | Required. Column names to be used as headers for the extracted values. Example: First Name Last Name Default value: [None] | |||||||
Start position | Required. Starting position of each column to be used while extracting field values. Example: 1 Default value: [None] | |||||||
End position | Required. Ending position of each column to be used while extracting field values. | |||||||
Trim column data | Required. If removal of leading and trailing spaces is required on the extracted data | |||||||
| Ignore Lines | This is a table property allows user to ignore lines in the input document satisfying the provided condition | |||||||
Function | This is an LOV property having functions to be applied on the data line to be ignored. Values: startsWith: To ignore a line starting with specific value endsWith: To ignore a line ending with specific value contains: To ignore a line containing specific value regex: To ignore a line with data in provided regular expression format Default value: startsWith | |||||||
Value | The value to be used for the function. If this value is empty then that property is ignored. Format: String | |||||||
|
| |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Examples
Fixing a Pipeline Containing Incorrect Field Configurations
In this sample pipeline, information is brought in through a Constant Snap, then sent to the Fixed Width Parser.
In the Constant Snap, supply the following information in the Content field:
81888888888800002ST06/20/2014JOHN SMITH 05-24-2012A
82777777777700003ST06/20/2014MARY SMITH 05-24-2012A
81888888888800002ST06/20/2014JOHN SMITH 05-24-2012A
82777777777700003ST06/20/2014MARY SMITH 05-24-2012A
81888888888800002ST06/20/2014JOHN SMITH 05-24-2012A
82777777777700003ST06/20/2014MARY SMITH 05-24-2012A
81888888888800002ST06/20/2014JOHN SMITH 05-24-2012A
82777777777700003ST06/20/2014MARY SMITH 05-24-2012A
81888888888800002ST06/20/2014JOHN SMITH 05-24-2012A
82777777777700003ST06/20/2014MARY SMITH 05-24-2012A
FIXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX00000010For reference, most of the rows are 70 characters long. Note that the last row of data intentionally does not follow the same format.
In the Fixed Width Parser add the following Field configurations, containing incorrect field positions to demonstrate error handling.
| Column Names | Start position | End Position | Trim Column Data |
|---|---|---|---|
| COLA | 1 | 12 | |
| COLB | 13 | 20 | |
| DATECOL | 21 | 30 | |
| NAME | 31 | 60 | Selected |
| DATE2 | 61 | 70 | |
| A | 71 | 72 |
When you save the pipeline, you will see the error: Failure: The input data format is not supported.
To help determine the error, set the error view on the Fixed Width Parser to route error data to error view. Now when you save the pipeline, data is written to the error view. If you look at the schema preview, you'll see the following.
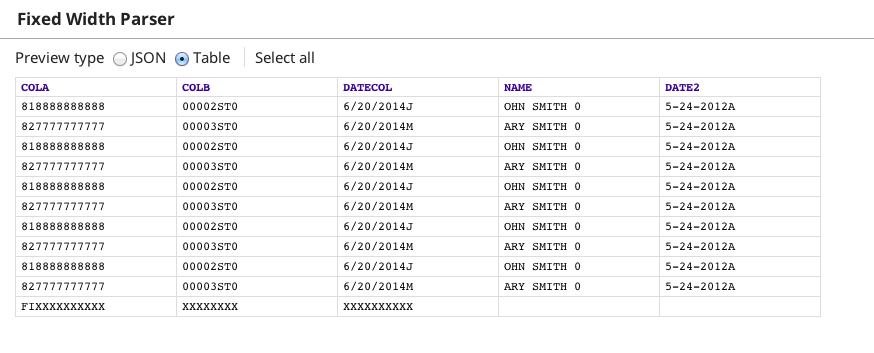
Note that:
- DATECOL contains the first character of NAME
- NAME contains the first character of DATE2
- DATE2 contains the character for A, which does not exist as a column.
- The last row of data only fills the first three columns (expected because its data format).
Now, update the Field configurations as follows:
- Set DATECOL end at 29.
- Set NAME to start at 30 and end at 59.
- Set DATE2 to start at 60 and end at 69.
- Set A to start and end at 70.
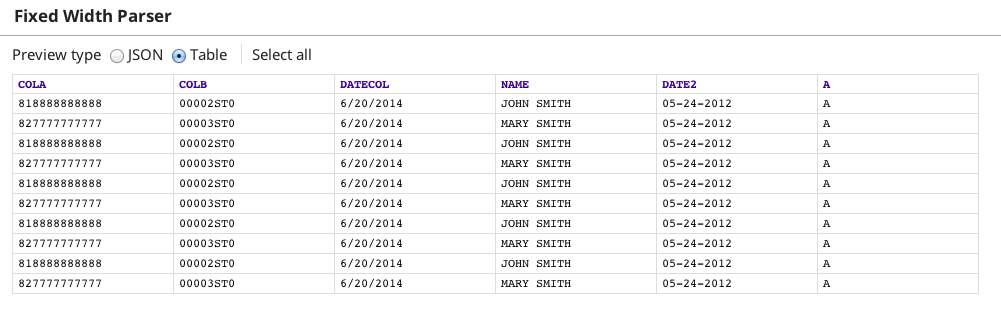
Now when you save the pipeline, data preview is available at both the output view and error view.
The output view contains the first 10 rows of data correctly formatted.
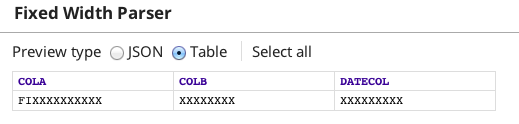
The error view now conatins only the last row of data that does not match the Field configuration settings.
Using the regex Function
To use regex to ignore lines with the digits "17" in the 16 & 17th positions in the lines, select regex in the function, and apply a value of:
\w{15}17.* (including the starting \ and ending *)
To Ignore all those except those with 17 in that position, we use:
^\w{15}17.*
To ignore all which had 17 or 99:
\w{15}(17|99).*
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|