...
...
...
In this
...
article
| Table of Contents | ||||
|---|---|---|---|---|
|
...
Snap type:
Parse
...
Description:
...
Overview
You can use this Snap to read CSV binary data from its input view,
...
parse it, and then write it to its output view as CSV document data
...
.
Snap Type
CSV Parser is a PARSE-type Snap that reads the binary data from the input view, parses, and writes to the output view.
Prerequisites
...
...
None
...
.
Support
...
for Ultra Pipelines
Works in Ultra
...
...
Accounts are not used with this Snap.
...
Limitations and Known Issues
None.
Snap Views
...
Settings
Label
...
Type | Format | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input | Binary |
|
| This Snap has at most two binary input views, where it gets the CSV binary data to be parsed. If there are two input views, it gets the CSV binary data to be parsed from the first input view and the CSV metadata from the second input view. The metadata should be a CSV format with two lines of CSV data: the first line is the CSV header, the second, data types. Supported data types are 'string', 'integer', 'float' and 'boolean'. If 'string' is a default data type, empty data type fields are considered to be 'string' type. An example of CSV metadata is: Last name,First name,age,commute_km,isDriving string, ,integer,float,boolean |
Output | Document |
| This Snap has exactly one document output view, where it provides the CSV document data stream. | |
Error |
This Snap has at most one document error view.
If the Snap fails during the operation, an error document is sent to the error view containing the fields error, reason, original, resolution, and stacktrace:
{
error: "Error parsing at line 2"
reason: "java.io.IOException: ..."
original: {...}
resolution: "Please provide valid CSV data at line 3 or route it to the error view"
stacktrace: "com.Snaplogic.Snap.api.SnapDataException: ...
}...
Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter while running the Pipeline by choosing one of the following options from the When errors occur list under the Views tab. The available options are:
Learn more about Error handling in Pipelines. |
Snap Settings
| Info |
|---|
|
Field Name | Field Type | Description |
|---|---|---|
Label* Default Value: CSV Parser | String | Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your |
...
Pipeline. |
Quote character |
...
Default Value: “ | Character | Specify the character to be used for a quote. As of 4.3.2, this property can be an expression, which is evaluated with the values from the Pipeline parameters. |
...
| ||
Delimiter Default value: |
...
, |
...
\t, \u001 | Character or Unicode | Specify the character to be used as a delimiter in parsing the CSV data. In case |
...
if you want to use tab as a delimiter, enter "\t" instead of pressing the Tab key. Any Unicode character is also supported. |
...
As of 4.3.2, this property can be an expression, which is evaluated with the values from the pipeline parameters. |
...
Escape character Default value: |
...
\ |
...
Character |
...
Specify the escape character that is to be used when parsing rows. Only single characters are supported. |
...
As of 4.3.2, |
...
this property can be an expression, which is evaluated with the values from the pipeline parameters. Leave this property empty if no escape character is used in the input CSV data. | ||
Snap Execution Default Value: |
...
: Validate & Execute | Dropdown list | Select one of the three modes in which the Snap executes. Available options are:
|
Troubleshooting
Settings | |||
|---|---|---|---|
Required. | |||
Skip lines | Required. The Skip lines property specifies the number of lines in the input data to be skipped before the Snap starts parsing.
Example: 0 | ||
...
Integer | |
Contains header | The Contains header property specifies whether the input data contains the CSV header or not. |
|---|---|
Column names | The Column names property is a composite table property, which contains the Columns property in it. This property is ignored if the second input view is used for the CSV metadata. |
Header | Specifies the list of headers to be used as a CSV header in formatting when the Contains header property is deselected.
Default value: [None] |
Validate headers | This option specifies whether or not the headers from the input data should be validated against the Column names table property. If this option is checked, the Snap throws an exception when they do |
...
not match exactly. | |||||||||||||
Header size error policy | Defines how to handle errors for records that do not match the header columns in the CSV file. This error condition occurs if the input document has fewer or additional columns that do not match with the header columns. The available options are:
Default value: Both Example: Trim record to fit header | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Character set | This setting lets you select the character set in which input CSV data is encoded. The supported selections are:
Default value: Auto BOM detect. | ||||||||||||
Ignore empty data | This property can be set false to produce an empty output document when the input CSV data is empty (both an empty binary stream and a binary stream with CSV headers only). This feature may be useful if the downstream Snaps should be executed whether the input CSV data is empty or not. Default value: True | ||||||||||||
Preserve Surrounding Spaces | Select this checkbox to preserve the surrounding spaces for the values that are non-quoted.
For example, if you are using data with a delimiter as follows:
If you deselect this checkbox, then surrounding spaces are removed before 12, 23, F, and M. | ||||||||||||
|
|
| Note |
|---|
You must either select Contains header or specify a Column name in order for validation on the pipeline to work. |
Examples
...
Use Case
Using the CSV Parser Snap Schema Capability
One of the features in the CSV Parser which customers sometimes request is the ability to define the fields (and their data types) for incoming CSV files. This is made easy by adding a second input view to the CSV Parser Snap, and providing the definition of the fields, and their data types in the flow.
For example, if you have input data in
...
the CSV file as follows, with no header line:
...
You can create a definition of the CSV data in another CSV file as follows:
...
...
Note the data types are optional, and defined on the second line of the input file. The parser supports the use of 'string', 'integer', 'float' and 'boolean' types. String is the default data type, any empty data type fields are considered to be strings.
The configuration of the pipeline for this use is as follows:
...
where the Read Snaps are File Readers.
The CSV Parser is configured as follows:
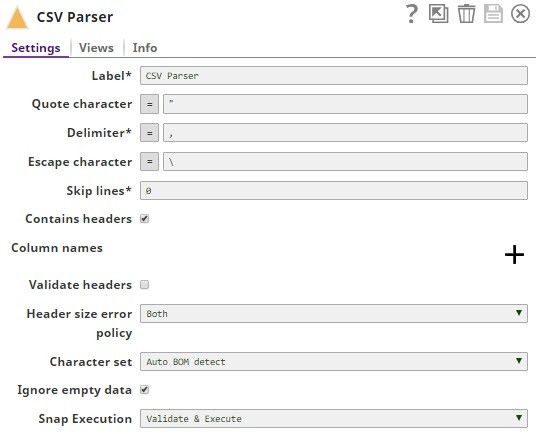
with the View settings as:
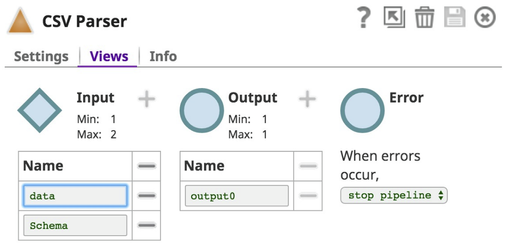
The resulting data in the SnapLogic pipeline data flow looks like this:
...
...
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|