On this Page
...
- Profiling: Use Profile Snap from ML Analytics Snap Pack to get statistics of this dataset.
- Data Preparation: Perform data preparation on this dataset using Snaps in ML Data Preparation Snap Pack.
- AutoML: Use AutoML Snap from ML Core Snap Pack to build models and pick the one with the best performance.
- Cross Validation: Use Cross Validator (Classification) Snap from ML Core Snap Pack to perform 10-fold cross validation on various Machine Learning algorithms. The result will let us know the accuracy of each algorithm in the success rate prediction.
We are going to build 5 Pipelines: Profiling, Data Preparation, Data Modelling and 2 Pipelines for Cross Validation with various algorithms. Each of these Pipelines is described in the Pipelines section below.
Pipelines
Profiling
In order to get useful statistics, we need to transform the data a little bit.
...
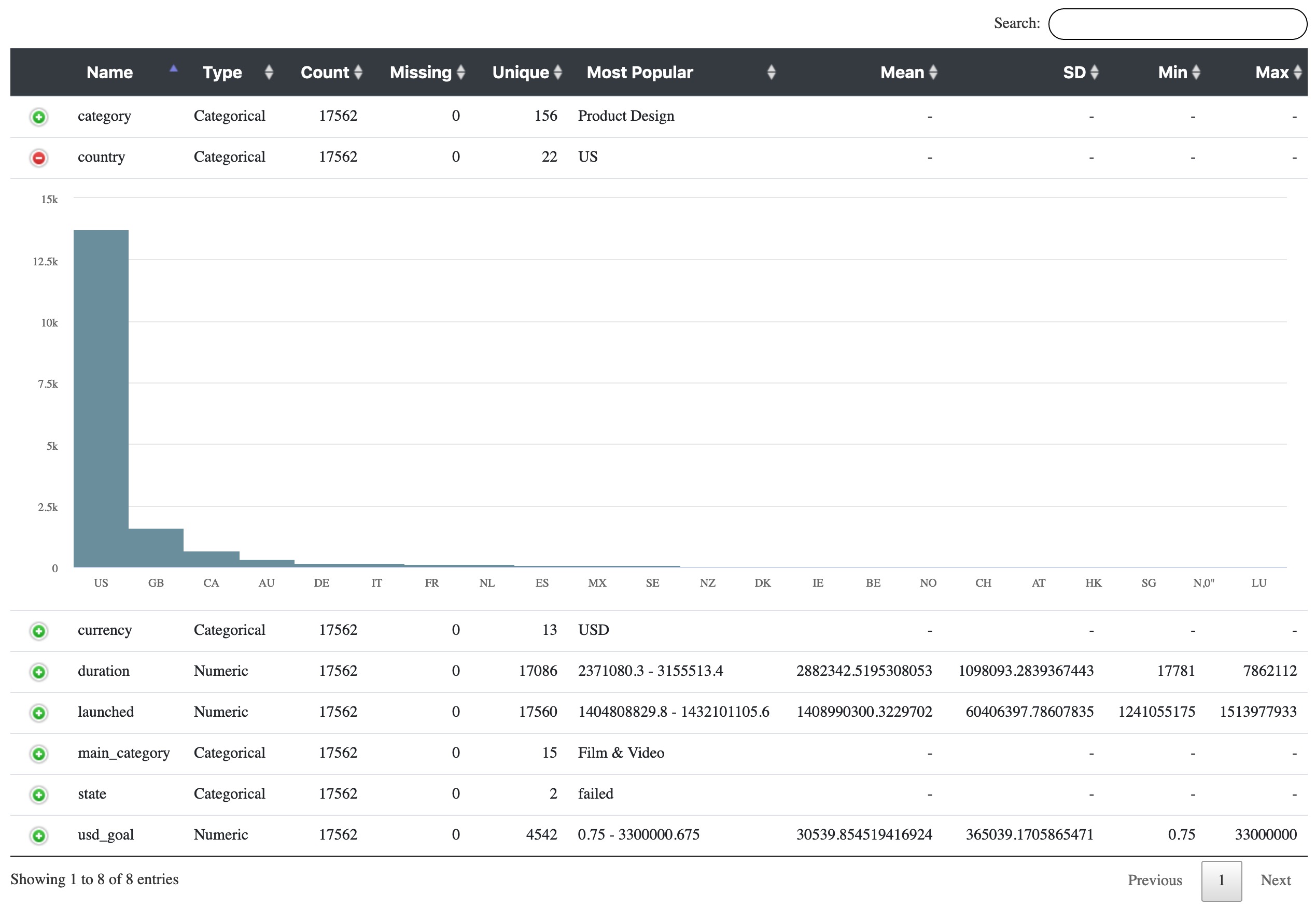
The Profile Snap has 2 output views. The first one is converted into JSON format and saved as a file. The second one is an interactive report which is shown below.
...
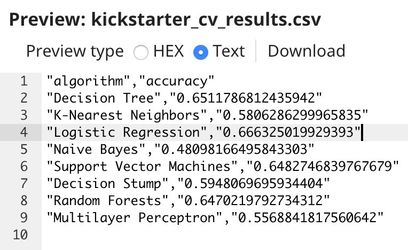
Below is the result. The logistic regression performs the best on this dataset at 66.6% accuracy. This is better than the baseline at 59.5%. However, it may not be practical to use. We may be able to do better than this by gathering more data about the project or improving the algorithm.
Downloads
| Multiexcerpt include macro | ||||
|---|---|---|---|---|
|
| Attachments | ||
|---|---|---|
|
...