| Table of Contents |
|---|
Overview
The Feature Synthesis Snap generates new features for base dataset by joining it with other datasets linked together by common identifiers. Features that are generated include:
- Mean
- Min
- Max
- Mode
- Unique
- Count
Input and Output
Expected input
- First input: The base dataset.
- Subsequent input(s): The reference dataset(s).
Expected output: The base dataset containing all the features generated based on the reference datasets.
Expected upstream Snaps: Snaps that offers a document output. For example, MySQL - Select, or PostgreSQL - Select .
Expected downstream Snaps: A Snap that accepts documents. For example, Mapper, JSON Formatter, or AutoML.
Prerequisites
The base dataset must have one-to-many or one-to-one relationship with the reference dataset. Or the reference datasets must have one-to-one or one-to-many relationship with each other.
Configuring Accounts
Accounts are not used with this Snap.
Configuring Views
Input | This Snap has at least two document input views. |
|---|---|
| Output | This Snap has exactly one document output view. |
| Error | This Snap has at most one document error view. |
Troubleshooting
None.
Limitations and Known Issues
None.
Modes
- Ultra pipelines: Does not work in Ultra pipelines.
- Spark mode: Does not work in Spark mode.
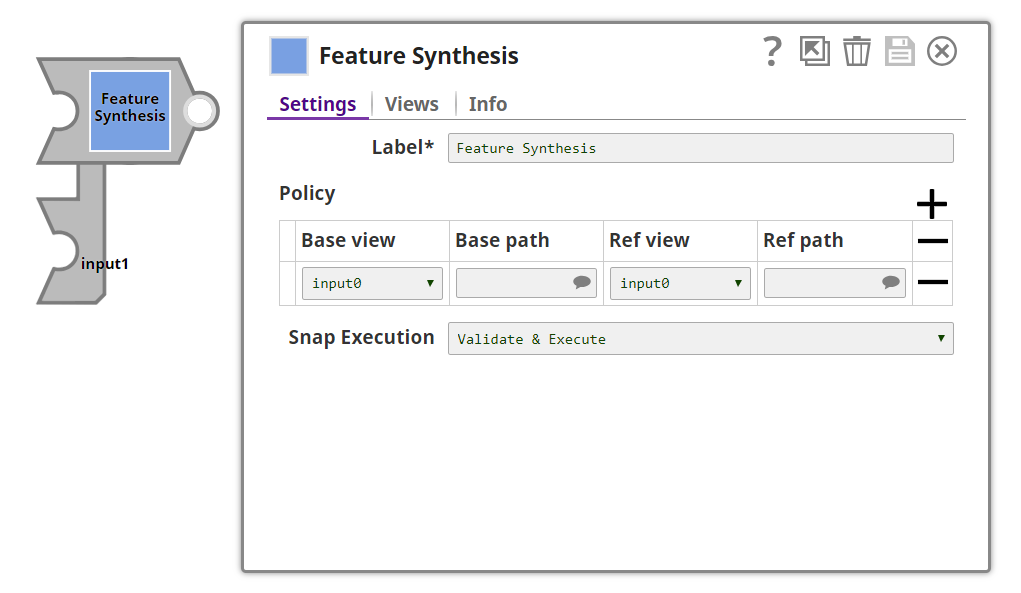
Snap Settings
| Label | Required. The name for the Snap. You can modify this to be specific, especially if you have more than one of the same Snap in your pipeline. |
|---|---|
| Policy | Specify the base and reference datasets and fields. |
| Base view | View where the base dataset is the input. Default value: input0 (name of the input view) |
| Base path | The field in the base dataset that is to be used as the base field. This has to be the common identifier for joining with the reference dataset(s). Example: $customer_id Default value: [None] |
| Ref view | View where the reference dataset is the input. Default value: input1 (name of the input view) |
| Ref path | The field in the reference dataset that is to be used. This field must have the same values as in the base field. Example: $customer_id Default value: [None] |
| Snap Execution | TBA once this field's functionality is finalized. |
Examples
Calculating Features in Customer Data Using Transaction Data
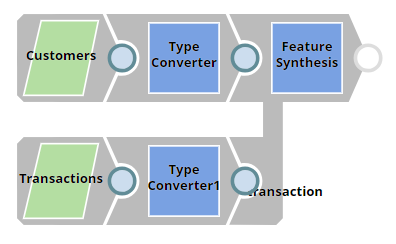
This example shows how the Feature Synthesis Snap is used to generate features using a base dataset and a reference dataset.
Download this Pipeline.
| Expand | ||
|---|---|---|
| ||
The base dataset in this example is collection of customer's records. It has the following fields:
The reference dataset is a collection of transactions made by the customers listed in the base dataset. It has the following fields:
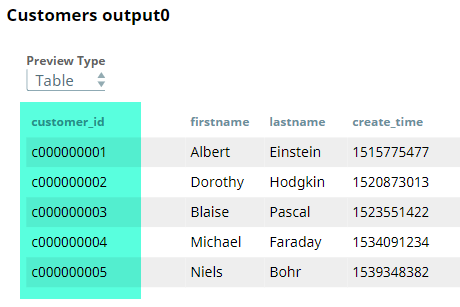
Both of the above datasets are provided as CSV files by the CSV Generator Snaps titled Customers and Transactions. These are passed through a Type Converter Snaps so that all datatypes are mapped correctly. This is required to enable the Feature Synthesis Snap to generate features accurately. A preview of the customer and transaction datasets that are output by the CSV Generator Snaps is as shown below:
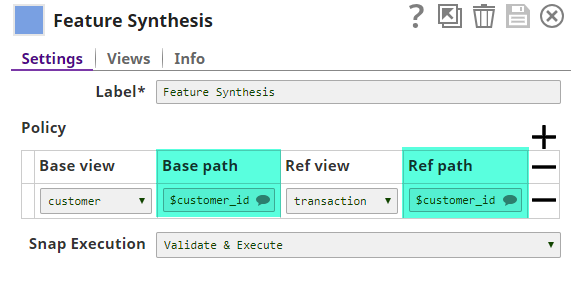
The field $customer_id is common between both datasets. The Feature Synthesis Snap will use this field to generate features and is configured as shown below: The customer dataset is connected to the input view titled customer so this view becomes the Base view. Similarly, the transaction dataset is connected to the input view titled transaction so that becomes the Ref view. Upon successful execution, the Feature Synthesis Snap generates features and adds them to the base dataset as shown below:
The same output is shown in a JSON format to let you see the full list of features:
Download this Pipeline. |


Downloads
| Attachments | ||
|---|---|---|
|