In this article
| Table of Contents | ||||
|---|---|---|---|---|
|
...
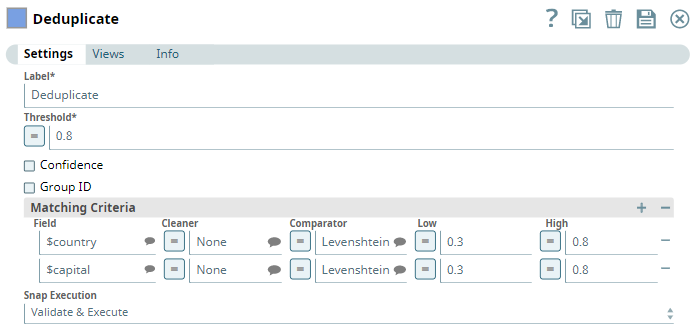
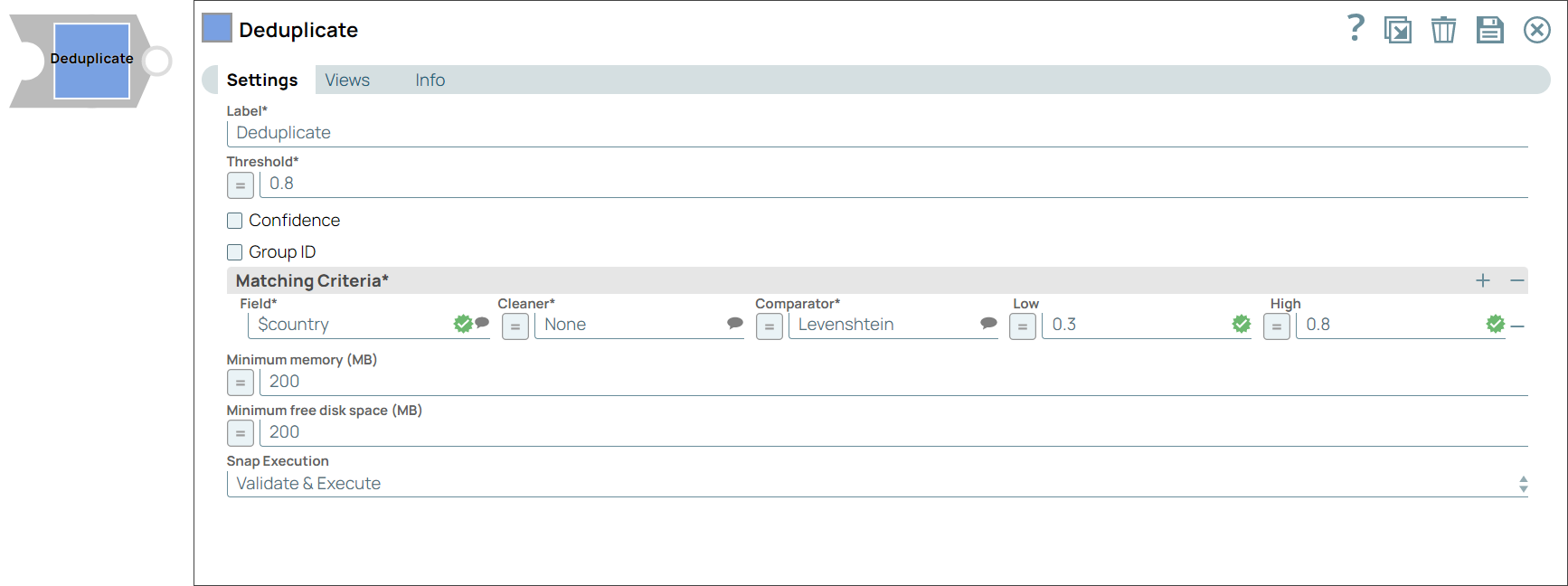
You can use this Snap to remove duplicate records from input documents. When you use multiple matching criteria to deduplicate your data, the Snap evaluates using each criterion separately, and then aggregates to give the final result. This Snap ignores fields with empty strings and whitespaces as no data.
Prerequisites
None.
...
| Parameter Name | Data Type | Description | Default Value | Example | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Label | String |
| N/A | Deduplicate Office Names | ||||||||
Threshold | Decimal | Required. The minimum confidence required for documents to be considered matched as duplicates using the matching criteria. Minimum Value: 0 Maximum Value: 1 | 0.8 | 0.95 | ||||||||
| Confidence | Checkbox | Select this check box to include each match's confidence levels in the output. | Deselected | N/A | ||||||||
| Group ID | Checkbox | Select this check box to include the group ID for each record in the output. | Deselected | N/A | ||||||||
| Matching Criteria | Fieldset | Enables you to specify the settings that you want to use to match input documents with the matching criteria. | N/A | N/A | ||||||||
Field | JSONPath | The field in the input dataset that you want to use for matching and identifying duplicates. | N/A | $name | ||||||||
Cleaner | String |
| None | Text | ||||||||
Comparator | String |
| Levenshtein | Numeric | ||||||||
Low | Decimal | A decimal value representing the level of probability of the input documents to be matched if the specified fields are completely unlike.
| N/A | 0.1 | ||||||||
High | Decimal | A decimal value representing the level of probability of the input documents to be matched if the specified fields are a complete match.
| NA | 0.8 | ||||||||
Minimum memory (MB) | Integer/Expression | Specify a minimum cut-off value for the memory the Snap must use when processing the documents. If the available memory is less than the specified value, the Snap stops execution and displays an exception to prevent the system from running out of memory.
| 200 | 1000 | ||||||||
Minimum free disk space (MB) | Integer/Expression | Specify the minimum free disk space required for the Snap to execute. If the free disk space is less the than the specified value, the Snap stops execution and displaysan exception to prevent the system from running out of disk space.
| 200 | 1000 | ||||||||
Snap Execution | String |
| Validate & Execute | N/A |
Multiexcerpt include macro name Temporary Files page Join
Examples
Deduplicating the List of Childhood Centers in Chicago
...
- You add a File Reader Snap to the Pipeline and configure it to read the source CSV file stored online:
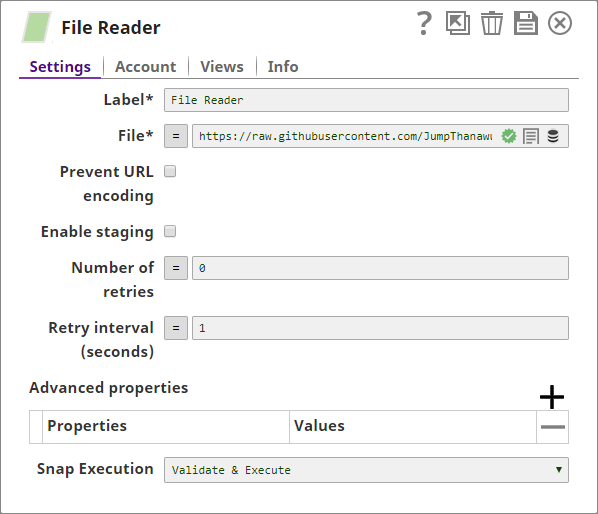
The File Reader Snap displays the contents of the file, which contains many duplicate entries:
- You add a CSV Parser Snap to the Pipeline to interpret the input data as a CSV document.
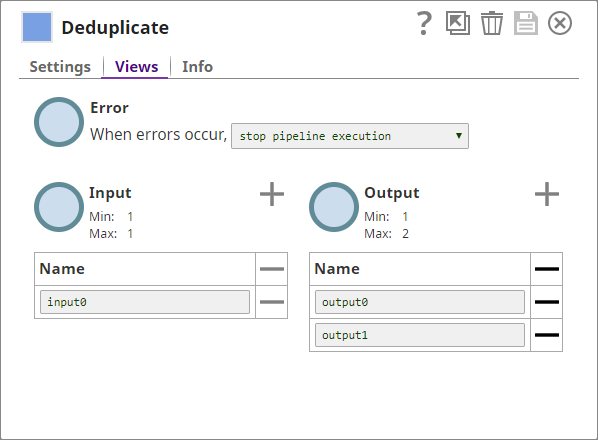
- You add a Deduplicate Snap to the Pipeline and configure it to use the name, address, ZIP, and phone details in the input document as fields for deduplication:
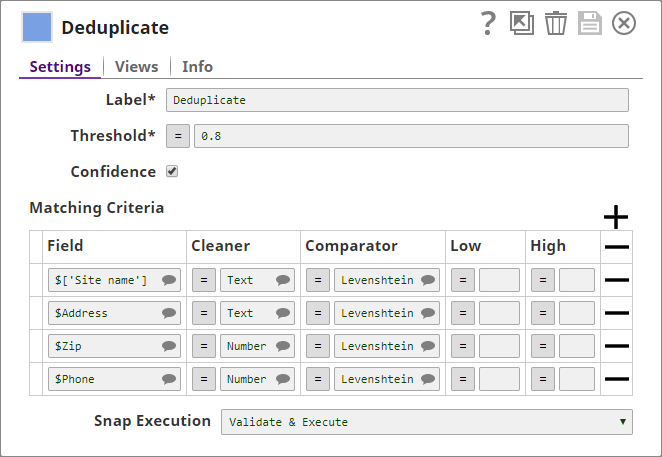
- You also add an additional output view to the Snap, where the Snap can display the duplicate data. Now, the Snap has two output views, one for the cleaned (deduplicated) data, and another for the duplicated records that the Snap filtered out.
The Snap, when executed, offers the following two output documents (Output0 and Output1). Output0 contains the deduplicated data, while Output1 contains the duplicate data: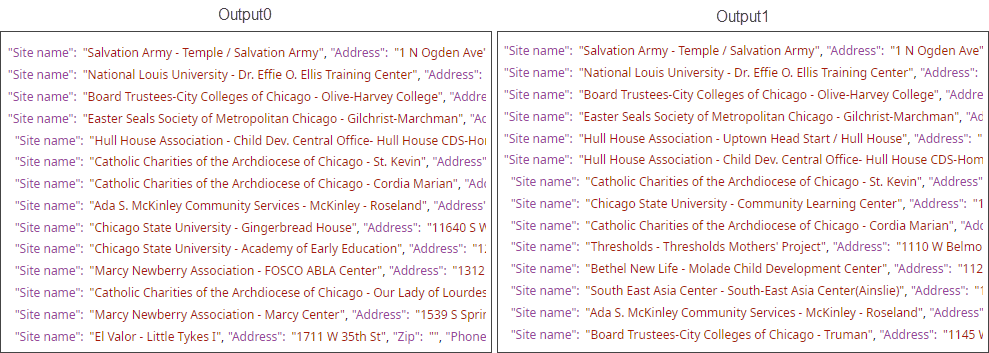
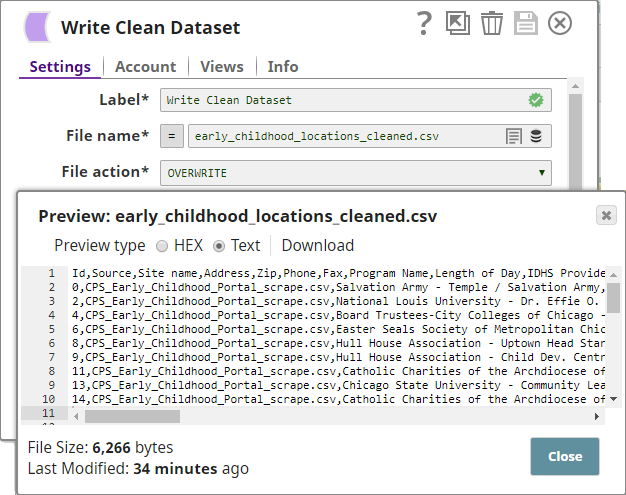
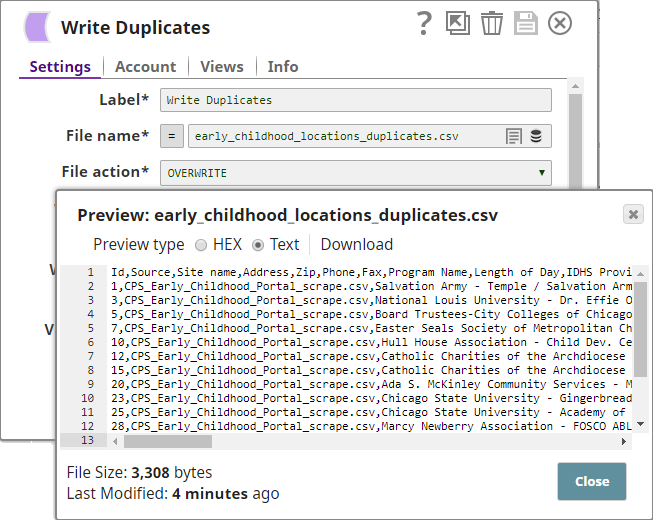
- You attach a CSV Formatter Snap to each output view of the Deduplicate Snap to structure the outputs as CSV documents. You then connect a File Writer Snap to each CSV Formatter Snap to write the input data as files.
- The Pipeline, when run, generates two output documents: one containing deduplicated data, and the other containing the duplicate data:
Downloads
...