In this article
Overview
You can use this Snap to retrieve the first non-NULL expression among a set of arguments. The Snap returns NULL if all its arguments are NULL. If you expect a query to return null values for certain functions or columns, you can use this Snap to replace the NULLs with some other value—typically in the case of certain aggregate functions that return null values instead of zero when they have no rows to evaluate.
COALESCE Arguments | Result |
|---|---|
coalesce(NULL, 2, NULL) | 2 |
coalesce(1, NULL, NULL) | 1 |
coalesce(NULL, NULL, 3) | 3 |
coalesce(NULL, NULL, NULL) | NULL |

Snap Type
ELT Coalesce Snap is a TRANSFORM-type Snap that extracts non-NULL values from datasets containing NULL values.
Prerequisites
A valid SnapLogic account to connect to the database in which you want to perform the COALESCE operation.
Limitations
None.
Known Issues
None.
Snap Input and Output
Input/Output | Type of View | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input | Document |
|
| The SQL query that resolves to a document containing the list of arguments for the COALESCE operation. |
Output | Document |
|
| The modified SQL query with the COALESCE operation included. |
Snap Settings
Click the = (Expression) button in the Snap's configuration, if available, to define the corresponding field value using expression language and Pipeline parameters.
You can use the SQL Expressions and Functions supported for ELT for this purpose. This list is common to all target CDWs supported. You can also use other expressions/functions that your target CDW supports.
Field names marked with an asterisk ( * ) in the table below are mandatory.
Field Name | Type | Description |
|---|---|---|
Label* | String | Specify a unique label for the Snap. Default Value: ELT Coalesce |
Get preview data | Checkbox | Select this checkbox to include a preview of the query's output. The Snap performs limited execution and generates a data preview during Pipeline validation. In case of ELT Pipelines, only the SQL query flows through the Snaps but not the actual source data. Hence, the preview data for a Snap is the result of executing the SQL query that the Snap has generated in the Pipeline. The number of records displayed in the preview (upon validation) is the smaller of the following:
Rendering Complex Data Types in Databricks Lakehouse Platform Based on the data types of the fields in the input schema, the Snap renders the complex data types like map and struct as object data type and array as an array data type. It renders all other incoming data types as-is except for the values in binary fields are displayed as a base64 encoded string and as string data type. Default Value: Not selected |
Pass through | Checkbox | Select this checkbox to include the original input data in the output document along with the results of the COALESCE operation. Default Value: Not selected |
Coalesce Alias | String | Enter the column alias name for storing the results of the COALESCE operation. Leave this field blank to allow the Snap to automatically define an alias name for the column. Default Value: None |
Coalesce Arguments | Specify the list of arguments based on the input data schema for performing the COALESCE operation. Each function must be specified as a new row. Click This field set consists of the following fields:
| |
Coalesce Argument | String/Expression | Enter an argument for performing the COALESCE operation. Define only one argument in this field. Default Value: None |
Troubleshooting
Error | Reason | Resolution |
|---|---|---|
None. |
Examples
Applying COALESCE Operation on a Dataset
In this Pipeline example, we apply the COALESCE operation on a dataset using the ELT Coalesce Snap.

To begin with, we use an ELT Select Snap to read the dataset from COALESCE_SRC table in a source database (Redshift in this example). The Snap retrieves the data from the table. You can see this dataset in JSON format in this Snap’s preview shown below.
ELT Select Snap | Output |
|---|---|
 |  |
We connect the ELT Coalesce Snap to the ELT Select Snap to apply the COALESCE operation on this dataset.
ELT Coalesce Snap | Output |
|---|---|
 | 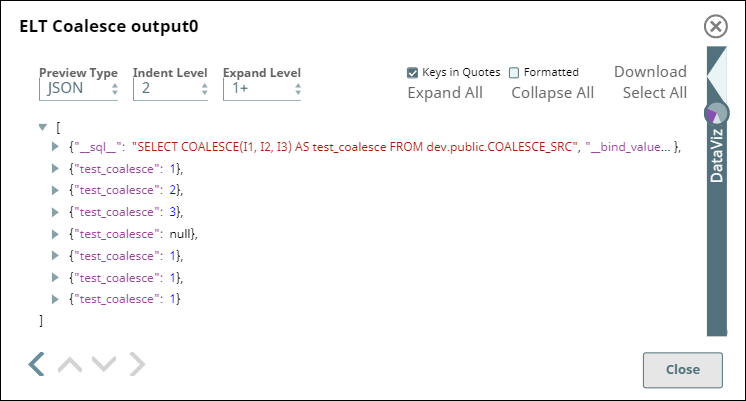 |
In this Snap, we provide an alias name for the COALESCE operation - test_coalesce and define the arguments—columns in the dataset to be considered for the operation—from the Coalesce Arguments fieldset. In the adjacent Snap Output (preview) image, we can see the results of the COALESCE operation on the selected arguments (I1, I2, and I3, in this case). The values returned are the first non-null values from each row in the data set.
We write these values to a different table - COALESCE_TC2 in the Redshift database using an ELT Insert Select Snap. Here we select the Overwrite checkbox to make sure that the data is written to a fresh(empty) table.

Downloads
Important Steps to Successfully Reuse Pipelines
Download and import the Pipeline into SnapLogic.
Configure Snap accounts as applicable.
Provide Pipeline parameters as applicable.