In this article
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
Use You can use this Snap to notify the Kafka Consumer Snap to commit an offset at specified metadata in each input document.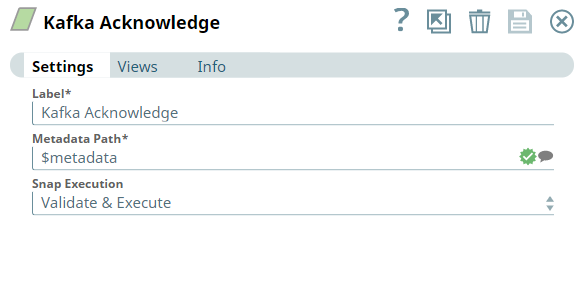
| Note |
|---|
|
Prerequisites
- A Confluent Kafka server with a valid account.
- The Kafka Acknowledge Snap in a pipeline must receive the metadata from an upstream Snap, for example, a Kafka Consumer Snap.
Support for Ultra Pipelines
Works in Ultra Pipelines.
...
Prerequisites
None.
Limitations
None.
Known Issues
None.
Snap Input and Output
| Input/Output | Type of View | Number of Views | Examples of Upstream and Downstream Snaps | Description | ||||
|---|---|---|---|---|---|---|---|---|
| Input | Document |
|
| Metadata from an upstream Kafka Consumer Snap. The input data schema is as shown below:
| ||||
| Output | Document |
|
| Processed and acknowledged Kafka messages.
If the Auto commit field is set to true in the input document, the output schema looks as shown below:
|
Snap Settings
| Parameter Name | Data Type | Description | Default Value | Example | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Label | String |
| Kafka Acknowledge | Kafka_Acknowledge | ||||||||
| Metadata path | String | Required. Specify the JSON path of the metadata within each input document. | metadata | $metadata | ||||||||
| Snap Execution | Drop-down list | Select one of the three following modes in which the Snap executes:
| Validate & Execute | Validate & Execute |
Troubleshooting
None.
Example
Acknowledging Messages
In this Pipeline, This example Pipeline demonstrates how we use the:
- Kafka Producer Snap to produce and send messages to a Kafka topic,
...
- Kafka Consumer Snap to read messages from
...
- a topic, and
...
- Kafka Acknowledge Snap to acknowledge the number of messages read (message count).
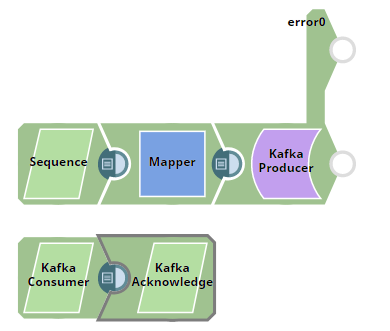
First, we use the Sequence Snap to enable the pipeline to send the documents in large numbers. We configure the Snap to read 2500 documents with the initial value as 1 and hence the Snap numbers all the documents starting from 1 through 2500.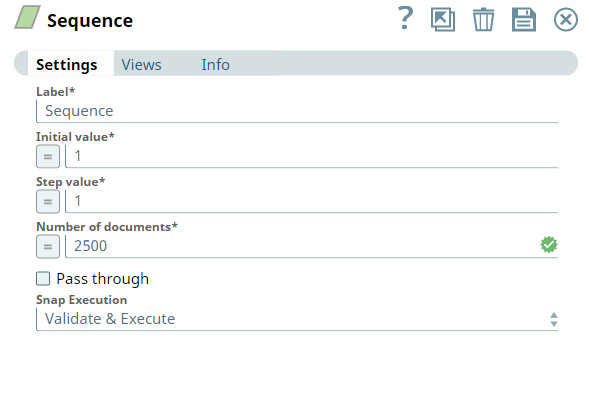
...
| Attachments | ||
|---|---|---|
|
...
See Also
- Apache Kafka
- Confluent - Schema Registry
- Getting Started with SnapLogic
- Snap Support for Ultra Pipelines
- SnapLogic Product Glossary
...