In this article
...
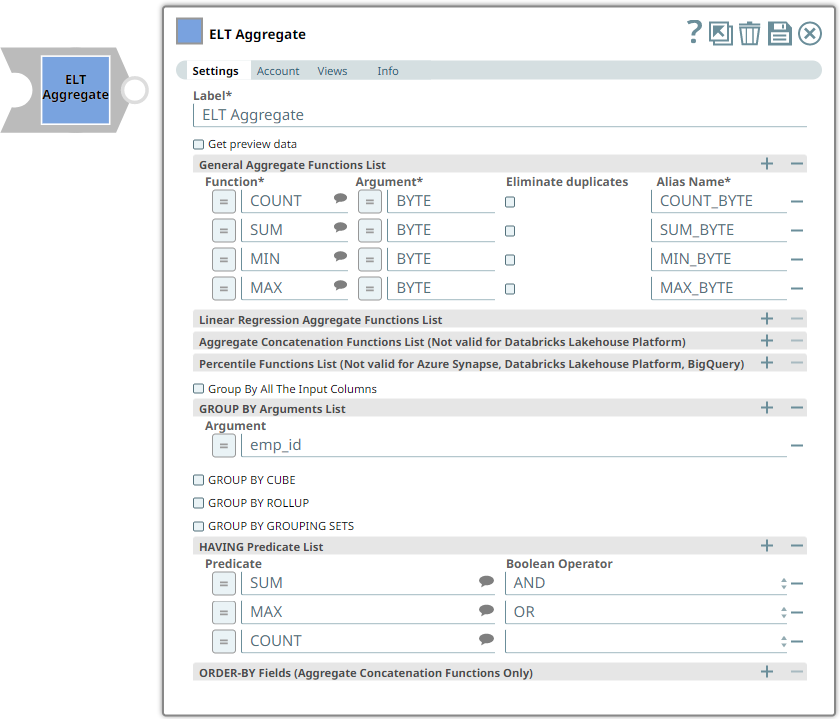
Use this Snap to add aggregate functions such as COUNT, SUM, MIN, and MAX along with the GROUP BY clause in the incoming SQL query. GROUP BY clauses are used to group table records based on columns that contain classifying data and are optional in this Snap. This Snap also allows you to preview the result of the output query. You can validate the modified query using this preview functionality. The supported aggregate functions vary based on the account configuration. See the description of the Aggregate Function field in the Snap Settings section for details.
Prerequisites
None.
Limitations
...
| Parameter Name | Data Type | Description | Default Value | Example | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Label | String |
| ELT Aggregate | Aggregate Revenue | ||||||||||||
| Get preview data | Checkbox |
| Not selected | Selected | ||||||||||||
| General Aggregate Functions List | This field set enables you to specify the columns for which to add the aggregate functions. Each aggregate function must be specified as a new row. Click This field set contains the following fields:
| |||||||||||||||
| Aggregate Function | String/Expression/Suggestion | Required. Select the aggregate function to use. Click Alternatively, you can also enter the name of the aggregate function to use; you must, however, ensure that it is spelled correctly. Otherwise, the Snap displays an error. You can use the following aggregate functions:
Additionally, the following aggregate functions are available based on the database type:
See Snowflake Aggregate Functions, Redshift SQL Functions Reference, Aggregate Functions (Transact-SQL), Databricks Built-in Functions Reference, or BigQuery Aggregate Functions in Standard SQL for more information on the respective aggregate function. | N/A | AVG | ||||||||||||
| Field Name | String/Expression | Required. Select the column on which to apply the aggregate function. | N/A | REVENUE | ||||||||||||
| Eliminate duplicates | Check box | Select to apply DISTINCT to the column specified in the Field field. This means that the aggregate function is applied only to the unique values in the column.
| Not selected | Selected | ||||||||||||
| Alias Name | String | Required. Specify the column in which to display the result of the aggregate function. You can also reference this name in downstream Snaps to process the data further. | N/A | TOTAL_REVENUE | ||||||||||||
| Linear Regression Aggregate Functions List | This field set enables you to specify the columns for which to apply the linear regression aggregate functions. Each function must be specified as a new row. Click This field set contains the following fields:
| |||||||||||||||
| Aggregate Function | String/Expression/Suggestion | Required. Select the aggregate function to use. Click Alternatively, you can also enter the name of an aggregate function; you must, however, ensure that it is spelled correctly. Otherwise, the Snap displays an error. You can use the following aggregate functions:
See Snowflake Aggregate Functions, Databricks Built-in Functions Reference, or BigQuery Aggregate Functions in Standard SQL for more information on the respective aggregate function.
| N/A | CORR | ||||||||||||
First Field | String/Expression | Required. Specify the first column on which to apply the linear regression aggregate function. | N/A | REVENUE_LOC1 | ||||||||||||
Second Field | String/Expression | Required. Specify the second column on which to apply the linear regression aggregate function. | N/A | REVENUE_LOC2 | ||||||||||||
| Alias Name | String | Required. Specify the column in which to display the result of the aggregate function. You can also reference this name in downstream Snaps to process the data further. | N/A | LINREGAGG_REVENUE | ||||||||||||
| Aggregate Concatenation Functions List (Not valid for Databricks Lakehouse Platform) | This field set enables you to specify the list of aggregate concatenation functions to be used for aggregation. The list displays the functions supported by the database that you select in the Account settings. Each function must be specified as a new row. Click This field set contains the following fields:
| |||||||||||||||
Aggregate Concatenation Function | String/Expression/Suggestion | Required. Select the aggregate concatenation function to use. Click Alternatively, you can also enter the name of the aggregate concatenation function to use; you must, however, ensure that it is spelled correctly. Otherwise, the Snap displays an error. You can use the following aggregate functions:
See Snowflake Aggregate Functions, Redshift SQL Functions Reference, Aggregate Functions (Transact-SQL), or BigQuery Aggregate Functions in Standard SQL for more information on the respective aggregate function. | N/A | LISTAGG | ||||||||||||
Field Name | String/Expression | Required. Specify the column name to apply the concatenation function. | N/A | NEW_LOCATIONS | ||||||||||||
Alias Name | String | Required. Specify the column in which to display the result of the concatenation function. You can also reference this name in downstream Snaps to process the data further. | N/A | UNIQUE_LOCS_LIST | ||||||||||||
Delimiter | String/Expression | Specify the delimiting character (string constant) to be used to separate the concatenated values. | , (comma) | ; (semi-colon) | ||||||||||||
| Percentile Distribution Functions List (Not valid for Azure Synapse, Databricks Lakehouse Platform, BigQuery) | This field set enables you to specify the list of percentile distribution functions to be used for aggregation. The list displays the functions supported by the database that you select in the Account settings. Each function must be specified as a new row. Click This field set contains the following fields:
| |||||||||||||||
Percentile Distribution Function | String/Expression/Suggestion | Required. Select the percentile distribution function to use. Click Alternatively, you can also enter the name of the percentile distribution function to use; you must, however, ensure that it is spelled correctly. Otherwise, the Snap displays an error. You can use the following aggregate functions:
See Snowflake Aggregate Functions or Redshift SQL Functions Reference for more information on the respective aggregate function. | N/A | PERCENTILE_DISC | ||||||||||||
| Percentile | String/Expression | Required. Specify the percentile value to be considered for applying the percentile distribution function. | N/A | 0.8 (80th percentile) | ||||||||||||
| Alias Name | String | Required. Specify the column in which to display the result of the percentile distribution function. You can also reference this name in downstream Snaps to process the data further. | N/A | REVENUE_CPERCENTILE | ||||||||||||
| GROUP BY Fields List | This field set enables you to specify the columns for which to use the GROUP BY clause. Each column must be specified in a new row. Click + to add a row. This field set contains the following field:
| |||||||||||||||
| GROUP BY Field | String/Expression | Specify the column in which to add the GROUP BY clause. | N/A | GRADE GENDER | ||||||||||||
| ORDER-BY Fields (Aggregate Concatenation Functions Only) | This field set enables you to specify the columns by which to sort the output data set. Each column must be specified in a new row. Click + to add a row. This field set contains the following fields:
| |||||||||||||||
| ORDER BY Field | String/Expression | Specify the column by which to sort the output data set. | N/A | GRADE GENDER | ||||||||||||
| Sort Order | Drop-down list | Choose one of the possible sort orders - ASC (ascending) or DESC (descending) for the output data set. | ASC | DESC | ||||||||||||
| Null Value Sort Preference | Drop-down list | Choose where in the sort order do the null values, if any, in the ORDER BY Field be placed - NULLS FIRST (at the beginning) or NULLS LAST (at the end) | NULLS FIRST | NULLS LAST | ||||||||||||
...