ELT Aggregate
- Anand Vedam
- Mohammed Iqbal
- Gouri Bhagchandani (Deactivated)
In this article
An account for the Snap
You must define an account for this Snap to communicate with your target CDW. Click the account specific to your target CDW below for more information:
Overview
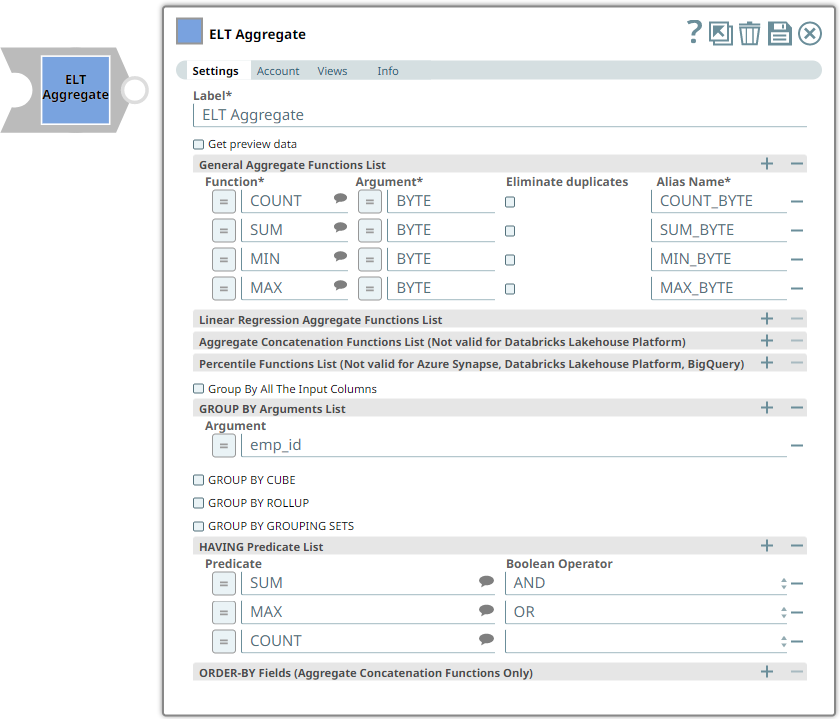
Use this Snap to add aggregate functions such as COUNT, SUM, MIN, and MAX along with the GROUP BY clause in the incoming SQL query. GROUP BY clauses are used to group table records based on columns that contain classifying data and are optional in this Snap. This Snap also allows you to preview the result of the output query. You can validate the modified query using this preview functionality. The supported aggregate functions vary based on the account configuration. See the description of the Aggregate Function field in the Snap Settings section for details.
Prerequisites
None.
Limitations
- Only those columns that are referenced in this Snap are passed to the output. The rest are dropped.
- ELT Snap Pack does not support Legacy SQL dialect of Google BigQuery. We recommend that you use only the BigQuery's Standard SQL dialect in this Snap.
Known Issues
- If you define a HAVING predicate in the HAVING Predicate List field set of the ELT Aggregate Snap (to apply on the Snap’s output data), the Snap connected downstream of this ELT Aggregate Snap returns an error corresponding to this predicate during the Pipeline execution.
In any of the supported target databases, this Snap does not appropriately identify nor render column references beginning with an _ (underscore) inside SQL queries/statements that use the following constructs and contexts (the Snap works as expected in all other scenarios):
WHEREclause (ELT Filter Snap)WHENclauseONcondition (ELT Join, ELT Merge Into Snaps)HAVINGclauseQUALIFYclause- Insert expressions (column names and values in ELT Insert Select, ELT Load, and ELT Merge Into Snaps)
- Update expressions list (column names and values in ELT Merge Into Snap)
- Secondary
ANDcondition Inside SQL query editor (ELT Select and ELT Execute Snaps)
Workaround
As a workaround while using these SQL query constructs, you can:
- Precede this Snap with an ELT Transform Snap to re-map the '_' column references to suitable column names (that do not begin with an _ ) and reference the new column names in the next Snap, as needed.
- In case of Databricks Lakehouse Platform where CSV files do not have a header (column names), a simple query like
SELECT * FROM CSV.`/mnt/csv1.csv`returns default names such as _c0, _c1, _c2 for the columns which this Snap cannot interpret. To avoid this scenario, you can:- Write the data in the CSV file to a DLP table beforehand, as in:
CREATE TABLE csvdatatable (a1 int, b1 int,…) USING CSV `/mnt/csv1.csv`where a1, b1, and so on are the new column names. - Then, read the data from this new table (with column names a1, b1, and so on) using a simple SELECT statement.
- Write the data in the CSV file to a DLP table beforehand, as in:
- In case of Databricks Lakehouse Platform, all ELT Snaps' preview data (during validation) contains a value with precision higher than that of the actual floating point value (float data type) stored in the Delta. For example, 24.123404659344 instead of 24.1234. However, the Snap reflects the exact values during Pipeline executions.
Due to an issue with Databricks Runtime Version 11 and above, the Snap fails to calculate the value for the linear regression aggregate function REGR_R2 for the target DLP instance and returns a cast exception. As a workaround, you can revert your Databricks Runtime Version to 10.5 or below.
When running without Sub-Query Pushdown Optimization (SPDO), ELT Pipelines that contain an ELT Aggregate Snap and configured with one or more GROUP BY ROLLUP fields, do not verify the column data types while inserting the Snap output values in the target table. This may lead to incorrect data written to the target table. However, as long as SPDO is on, the same Pipeline runs without this issue.
Snap Input and Output
| Input/Output | Type of View | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
| Input | Document |
|
| The SQL query in which to add the aggregate functions and the optional GROUP BY clause. |
| Output | Document |
|
| The modified SQL query with the aggregate functions and GROUP BY clause. |
Snap Settings
SQL Functions and Expressions for ELT
You can use the SQL Expressions and Functions supported for ELT to define your Snap or Account settings with the Expression symbol = enabled, where available. This list is common to all target CDWs supported. You can also use other expressions/functions that your target CDW supports.
| Parameter Name | Data Type | Description | Default Value | Example | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Label | String | Specify a name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | ELT Aggregate | Aggregate Revenue | ||||||||||||
| Get preview data | Checkbox | Select this checkbox to include a preview of the query's output. The Snap performs limited execution and generates a data preview during Pipeline validation. In the case of ELT Pipelines, only the SQL query flows through the Snaps but not the actual source data. Hence, the preview data for a Snap is the result of executing the SQL query that the Snap has generated in the Pipeline. The number of records displayed in the preview (upon validation) is the smaller of the following:
Rendering Complex Data Types in Databricks Lakehouse Platform Based on the data types of the fields in the input schema, the Snap renders the complex data types like map and struct as object data type and array as an array data type. It renders all other incoming data types as-is except for the values in binary fields are displayed as a base64 encoded string and as string data type. | Not selected | Selected | ||||||||||||
| General Aggregate Functions List | This field set enables you to specify the columns for which to add the aggregate functions. Each aggregate function must be specified as a new row. Click This field set contains the following fields:
| |||||||||||||||
| Function* | String/Expression/Suggestion | Required. Select the aggregate function to use. Click Alternatively, you can also enter the name of the aggregate function to use; you must, however, ensure that it is spelled correctly. Otherwise, the Snap displays an error. You can use the following aggregate functions:
Additionally, the following aggregate functions are available based on the database type:
See Snowflake Aggregate Functions, Redshift SQL Functions Reference, Aggregate Functions (Transact-SQL), Databricks Built-in Functions Reference, or BigQuery Aggregate Functions in Standard SQL for more information on the respective aggregate function. | N/A | AVG | ||||||||||||
| Argument* | String/Expression | Required. Enter the field name or expression on which you want to apply the general aggregate function. | N/A | REVENUE | ||||||||||||
| Eliminate duplicates | Check box | Select to apply DISTINCT to the column specified in the Field field. This means that the aggregate function is applied only to the unique values in the column. Behavior with COUNT_IF aggregate function Selecting this checkbox while using COUNT_IF aggregate function does not eliminate duplicate records in case of Snowflake and BigQuery databases, as there is no native support. However, it eliminates the duplicates from the list of records when used with a Redshift, Azure Synapse, or Databricks Lakehouse Platform (DLP) instance. | Not selected | Selected | ||||||||||||
| Alias Name* | String | Required. Specify the column in which to display the result of the aggregate function. You can also reference this name in downstream Snaps to process the data further. | N/A | TOTAL_REVENUE | ||||||||||||
| Linear Regression Aggregate Functions List | This field set enables you to specify the columns for which to apply the linear regression aggregate functions. Each function must be specified as a new row. Click This field set contains the following fields:
| |||||||||||||||
| Function* | String/Expression/Suggestion | Required. Select the aggregate function to use. Click Alternatively, you can also enter the name of an aggregate function; you must, however, ensure that it is spelled correctly. Otherwise, the Snap displays an error. You can use the following aggregate functions:
See Snowflake Aggregate Functions, Databricks Built-in Functions Reference, or BigQuery Aggregate Functions in Standard SQL for more information on the respective aggregate function. Though not supported natively BigQuery does not natively support the above list of Linear Regression Aggregate Functions. However, SnapLogic provides you with the ability to use these functions with BigQuery through a series of internal query rewrites. | N/A | CORR | ||||||||||||
Argument 1* | String/Expression | Required. Enter the first field name or expression on which you want to apply the Aggregate function. | N/A | REVENUE_LOC1 | ||||||||||||
Argument 2* | String/Expression | Required. Enter the second field name or expression on which you want to apply the Aggregate function. | N/A | REVENUE_LOC2 | ||||||||||||
| Alias Name* | String | Required. Specify the column in which to display the result of the aggregate function. You can also reference this name in downstream Snaps to process the data further. | N/A | LINREGAGG_REVENUE | ||||||||||||
| Aggregate Concatenation Functions List (Not valid for Databricks Lakehouse Platform) | This field set enables you to specify the list of aggregate concatenation functions for aggregation. The list displays the functions supported by the database that you select in the Account settings. Each function must be specified as a new row. Click This field set contains the following fields:
| |||||||||||||||
Function* | String/Expression/Suggestion | Required. Select the aggregate concatenation function to use. Click Alternatively, you can also enter the name of the aggregate concatenation function to use; you must, however, ensure that it is spelled correctly. Otherwise, the Snap displays an error. You can use the following aggregate functions:
See Snowflake Aggregate Functions, Redshift SQL Functions Reference, Aggregate Functions (Transact-SQL), or BigQuery Aggregate Functions in Standard SQL for more information on the respective aggregate function. | N/A | LISTAGG | ||||||||||||
Argument* | String/Expression | Required. Enter the field name or expression on which you want to apply the Aggregate Concatenation function. | N/A | NEW_LOCATIONS | ||||||||||||
Alias Name* | String | Required. Specify the column in which to display the result of the concatenation function. You can also reference this name in downstream Snaps to process the data further. | N/A | UNIQUE_LOCS_LIST | ||||||||||||
Delimiter | String/Expression | Specify the delimiting character (string constant) to be used to separate the concatenated values. | , (comma) | ; (semi-colon) | ||||||||||||
| Percentile Distribution Functions List (Not valid for Azure Synapse, Databricks Lakehouse Platform, BigQuery) | This field set enables you to specify the list of percentile distribution functions to be used for aggregation. The list displays the functions supported by the database that you select in the Account settings. Each function must be specified as a new row. Click This field set contains the following fields:
| |||||||||||||||
Function* | String/Expression/Suggestion | Required. Select the percentile distribution function to use. Click Alternatively, you can also enter the name of the percentile distribution function to use; you must, however, ensure that it is spelled correctly. Otherwise, the Snap displays an error. You can use the following aggregate functions:
See Snowflake Aggregate Functions or Redshift SQL Functions Reference for more information on the respective aggregate function. | N/A | PERCENTILE_DISC | ||||||||||||
| Percentile* | String/Expression | Required. Specify the percentile value to be considered for applying the percentile distribution function. | N/A | 0.8 (80th percentile) | ||||||||||||
| Alias Name* | String | Required. Specify the column in which to display the result of the percentile distribution function. You can also reference this name in downstream Snaps to process the data further. | N/A | REVENUE_CPERCENTILE | ||||||||||||
| Group By All The Input Columns | Checkbox | Select this checkbox to group the output data by all columns in the input table. This disables the Group By Arguments List fieldset. | Not Selected | Selected | ||||||||||||
| GROUP BY Arguments List | This fieldset enables you to specify the columns for which to use the GROUP BY clause. Each column must be specified in a new row. Click This fieldset contains the following field:
| |||||||||||||||
| Argument | String/Expression | Specify the column in which to add the GROUP BY clause. | N/A | GRADE GENDER | ||||||||||||
| GROUP BY CUBE | Checkbox | Select this checkbox to group the output data using the GROUP BY CUBE clause. This activates the GROUP BY CUBE Arguments List fieldset. | Not Selected | Selected | ||||||||||||
| GROUP BY CUBE Arguments List | This fieldset enables you to specify the arguments for the GROUP BY CUBE clause. In addition to the GROUP BY ROLLUP, GROUP BY CUBE adds all the “cross-tabulations” rows and is equivalent to a series of grouping sets. Each argument must be specified in a new row. Click This fieldset contains the following field:
| |||||||||||||||
| Argument* | String/Expression | Specify the column in which to add the GROUP BY CUBE clause. | N/A | CUST_ID ORDERS | ||||||||||||
| GROUP BY ROLLUP | Checkbox | Select this checkbox to group the output data using the GROUP BY ROLLUP clause. This activates the GROUP BY ROLLUP Arguments List fieldset. | Not Selected | Selected | ||||||||||||
| GROUP BY ROLLUP Arguments List | This fieldset enables you to specify the arguments for the GROUP BY ROLLUP clause that produces sub-total rows (in addition to the grouped rows). Each argument must be specified in a new row. Click This fieldset contains the following field:
| |||||||||||||||
| Argument* | String/Expression | Specify the column in which to add the GROUP BY ROLLUP clause. | N/A | CATEGORY REGION | ||||||||||||
| GROUP BY GROUPING SETS | Checkbox | Select this checkbox to group the output data using the GROUP BY GROUPING SETS clause. This activates the GROUP BY GROUPING SETS Arguments List fieldset. | Not Selected | Selected | ||||||||||||
| GROUP BY GROUPING SETS Arguments List | This fieldset enables you to specify the arguments for the GROUP BY GROUPING SETS clause that that allows computing multiple GROUP BY clauses in a single statement. The group set is a set of dimension columns. Each argument must be specified in a new row. Click This fieldset contains the following field:
| |||||||||||||||
| Argument* | String/Expression | Specify the column in which to add the GROUP BY GROUPING SETS clause. | N/A | CATEGORY REGION | ||||||||||||
| HAVING Predicate List | This fieldset enables you to specify the arguments for the HAVING predicates (conditions) over the result of applying a GROUP BY clause. Each predicate must be specified in a new row. Click This fieldset contains the following field:
| |||||||||||||||
| Predicate | String/Expression | Specify the predicate (condition) to filter the results of a GROUP BY (CUBE/ROLLUP/GROUPING SETS) operation. | N/A | ORD_COUNT(*) >100 | ||||||||||||
| Boolean Operator | Drop-down list | Select one boolean operator to apply another HAVING predicate in combination with the predicate selected. | N/A | AND | ||||||||||||
| ORDER-BY Fields (Aggregate Concatenation Functions Only) | This field set enables you to specify the columns by which to sort the output data set. Each column must be specified in a new row. Click + to add a row. This field set contains the following fields:
| |||||||||||||||
| ORDER BY Field | String/Expression | Specify the column by which to sort the output data set. | N/A | GRADE GENDER | ||||||||||||
| Sort Order | Drop-down list | Choose one of the possible sort orders - ASC (ascending) or DESC (descending) for the output data set. | ASC | DESC | ||||||||||||
| Null Value Sort Preference | Drop-down list | Choose where in the sort order do the null values, if any, in the ORDER BY Field be placed - NULLS FIRST (at the beginning) or NULLS LAST (at the end) | NULLS FIRST | NULLS LAST | ||||||||||||

Troubleshooting
| Error Message | Reason | Resolution |
|---|---|---|
| Account is required, please set in Accounts tab | Account configuration is mandatory in the ELT Aggregate Snap. An account has not been selected/configured in the Snap. | Select or configure an account for the Snap. See Configuring the ELT Snap Pack Accounts for details. |
| Failure: Invalid Function Specified : <field value> | The specified aggregate function is incorrect/not supported. This is likely to occur if you have entered the aggregate function's name in the Aggregate Function field manually. | Check whether the aggregate function specified in the error message is spelled correctly. You can avoid this error by selecting from the Snap's suggested aggregate functions. Click |
Examples
Performing Aggregate Calculations
We need a query with the appropriate aggregate functions along with a GROUP BY clause. This example shows how we can use the ELT Aggregate Snap to achieve this result.
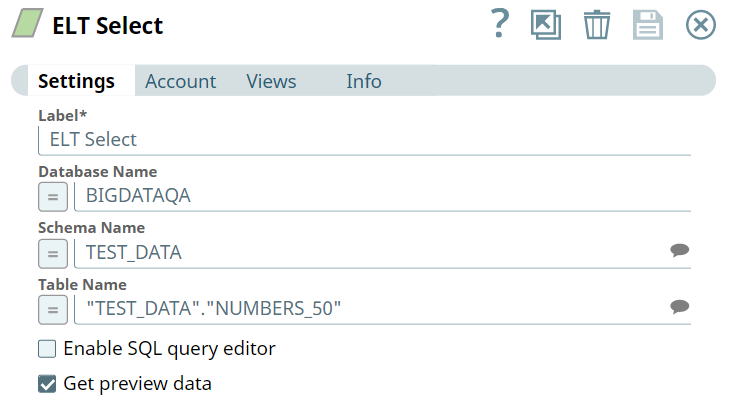
First, we use the ELT Select Snap to build a query to retrieve all records from the target table.
Upon execution, this Snap builds the query as shown below:

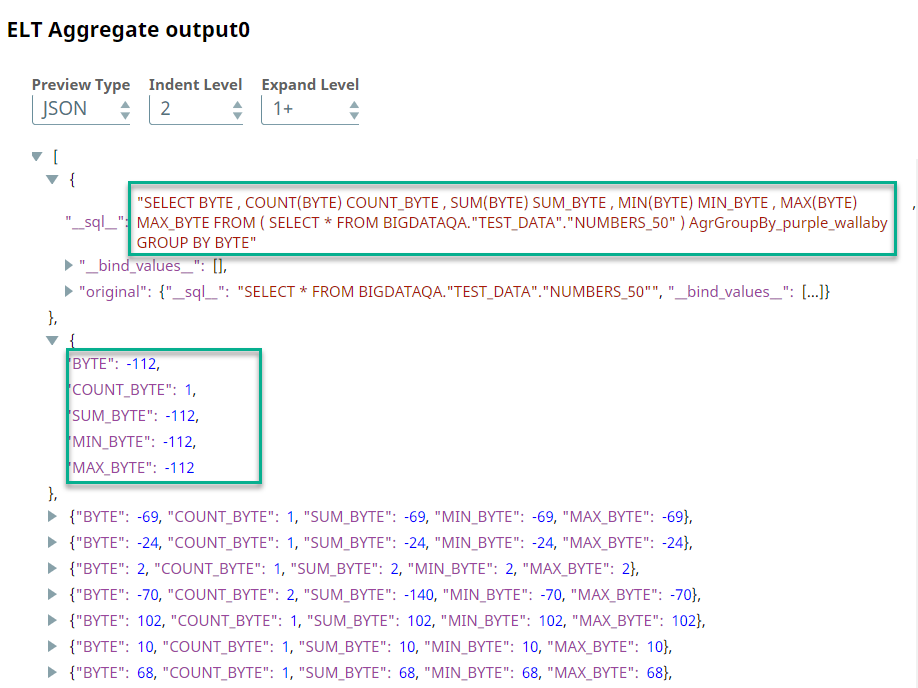
We want to perform aggregate functions for the values in the BYTE column. Accordingly, we add the ELT Aggregate Snap and configure it as required. In this example, we want to calculate the COUNT, SUM, MIN, and MAX. So, we configure the ELT Aggregate Snap as shown below:
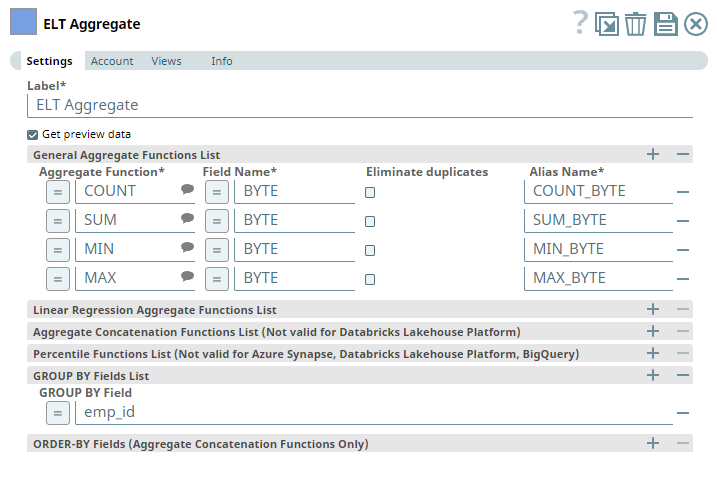
Based on this configuration, the ELT Aggregate Snap builds a query as shown below:
Downloads
Important steps to successfully reuse pipelines
- Download and import the Pipeline into SnapLogic.
- Configure Snap accounts as applicable.
- Provide Pipeline parameters as applicable.
Snap Pack History
Release | Snap Pack Version | Date | Type | Updates |
|---|---|---|---|---|
| February 2025 | 440patches30341 | Latest | Fixed an issue with the ELT Merge Into Snap where the Snap fails to perform the MERGE INTO operation on the RedShift target tables with the error - Failed to set search_path when the specified target Database schema is not one of the default schemas ("$user”, public). | |
| February 2025 | main29887 | Stable | Updated and certified against the current SnapLogic Platform release. | |
| November 2024 | 439patches29443 | Latest | Fixed an issue with the ELT Merge Into Snap where the Snap fails to perform the MERGE INTO operation on the RedShift target tables with the error - There were no target table columns found. when the specified target Database schema is not one of the default schemas ("$user”, public). This issue did not exist before the May 2024 release. | |
| November 2024 | main29029 | Stable | Updated and certified against the current SnapLogic Platform release. | |
| August 2024 | 438patches28010 | Latest | The ELT Insert-Select Snap no longer fails to execute SQL statements that contain multiple multiline comment character pairs (/* and */) and/or multiple quoted substrings. Quoted substrings refer to schema, database, table, or column identifiers, which are delimited to allow special characters.
| |
| August 2024 | main27765 | Stable | Upgraded the jOOQ library for the ELT Snap Pack from v3.9.1 to v3.17.x. | |
| May 2024 | 437patches27372 | Latest | Enhanced the pipeline execution statistics of ELT Insert-Select Snap to be displayed in its output view and to allow downloading detailed stats as a JSON file that includes additional statistics ( | |
| May 2024 | 437patches27246 | Latest | Enhanced the ELT Execute Snap to display SQL execution statistics in the pipeline execution statistics and the output view of the Snap for all SQL statements executed. The Snap also allows you to download detailed stats as a JSON file that includes additional statistics ( | |
| May 2024 | 437patches26846 | Latest | Fixed the issue with the ADLS Gen 2 account connection where some conflicts between internally used Azure libraries prevented the ELT Load Snap from reading files. | |
Fixed an issue with the ELT Merge Into Snap where the Snap’s SELECT SQL statement could not fetch the target tables information from the PG_TABLE_DEF catalog table of the Amazon Redshift instance.
PG_TABLE_DEF is a Redshift system catalog table that contains information about the tables including table names, column names, data types among their other metadata. | ||||
| Enhanced the ELT Load Snap to support loading data from nested AVRO, JSONLines, ORC, or Parquet files in Azure storage to the target tables in a Databricks Lakehouse Platform (DLP) instance. Only two Load actions are supported: Drop and create table and Append table. | ||||
| May 2024 | main26341 | Stable | Fixed an issue where the ELT Merge Into Snap failed to load data into the Google BigQuery target table because of the error: | |
| February 2024 | 436patches25953 | Latest | Enhanced the ELT Load Snap’s capabilities to allow loading flat and nested data sets (from canonical and non-canonical formats) from your Parquet files to the target tables in Snowflake. Learn more about the usage of this feature at Load data from Parquet files and in the following example Pipelines: | |
| February 2024 | main25112 | Stable | Updated and certified against the current SnapLogic Platform release. | |
| November 2023 | 435patches24461 | Latest | Fixed an issue with the ELT Merge Into Snap that caused inaccurate aliases and table identifiers in its generated SQL statement. | |
| November 2023 | 435patches23671 | Latest and Stable |
| |
| November 2023 | main23721 | Stable |
| |
| August 2023 | main22460 | Stable |
| |
| May 2023 | N/A | Stable | Fixed a null pointer exception so no 5XX errors can occur if you download non-existent query details from the Pipeline Execution Statistics of an ELT (write-type) Snap. | |
| May 2023 | main21015 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| February 2023 | 432patches20978 | Latest | Fixed an issue with the ELT SCD2 Snap where the COLLATE column constraint (used in the new target table definition for Snowflake) resulted in an incorrect syntax internally, causing the pipeline to fail. The load operation succeeds with this fix. | |
| February 2023 | main19844 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| November 2022 | 431patches19240 |
| Latest |
|
| November 2022 | main18944 | Stable | ELT Insert-Select, ELT Merge Into, and ELT SCD2 Snaps show the following statistics on execution.
| |
| September 2022 | 430patches18196 | Latest | New SnapThe ELT Create View Snap enables you to create a new view when the view does not exist in the target database and/or schema or if the view already exists in the database and/or schema, and you choose to drop the existing view and re-create it. Enhancements
| |
| August 2022 | main17386 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.29-Patch | 429patches16665 | Latest |
| |
| 4.29-Patch | 4.29patches16287 | Latest | Fixed an issue with the ELT SCD2 Snap where the Snap was rounding off decimal values to the nearest integer—the value 57.601000000000 in the source table was written to the target table as 58.000000000. | |
| 4.29 | main15993 | Stable |
| |
| 4.28-Patch | 428patches15638 | Latest | Fixed the issue with ELT Merge Into Snap where the Snap erroneously modified the target table column name when it contained the target table name, due to a misinterpretation of the target table name aliases. | |
| 4.28-Patch | 428patches15290 | Latest |
| |
| 4.28 | main14627 | Stable |
| |
| 4.27-Patch | 427patches13923 | Latest |
| |
| 4.27-Patch | 427patches13539 | Latest |
| |
| 4.27-Patch | 427patches13030 | Latest |
| |
| 4.27 | main12833 | Stable |
| |
| 4.26-Patch | 426patches12534 | Latest |
| |
| 4.26-Patch | 426patches12021 | Latest |
| |
| 4.26-Patch | 426patches11646 | Latest |
| |
| 4.26-Patch | 426patches11323 | Latest |
| |
| 4.26-Patch | 426patches11262 | Latest |
| |
| 4.26 | main11181 | Stable |
| |
| 4.25-Patch | 425patches10017 | Latest |
| |
| 4.25-Patch | 425patches9725 | Latest |
| |
| 4.25 | main9554 | Stable |
| |
| 4.24-Patch | 424patches8793 | Latest |
No changes are needed to your existing Pipelines.
Behavior Change The behavior of ELT Load Snap for Load Action during Pipeline validation across the supported databases is as follows: Append rows to existing table: Does not append the data from the source files into the target table. Overwrite existing table: Does not overwrite the data. Drop and Create table: Does not drop the target table even if it exists, but the Snap creates a new target table if a table does not exist. Alter table: Does not modify the schema of the target table. | |
| 4.24 | main8556 | Stable |
Updates the Snap Pack with the following features:
| |
| 4.23 | main7430 | Stable | Introduces the following Snaps:
| |
4.22 | main6403 | Stable | Introduces the ELT Snap Pack that provides you with the Extract, Load, and Transform (ELT) capabilities. Use the following Snaps to build SQL queries that are executed in the Snowflake database:
|
See Also
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.