ELT Join
- Anand Vedam
- Mohammed Iqbal
- Gouri Bhagchandani (Deactivated)
In this article
Overview
Use this Snap to add a JOIN clause to join tables in separate queries coming from the upstream Snaps. This Snap also allows you to preview the result of the output query. You can validate the modified query using this preview functionality.
ELT Join Snap requires an account configuration
Starting from 4.24 GA, ensure to configure an account for this Snap.
Prerequisites
None.
Limitation
Known Issues
Snap Input and Output
| Input/Output | Type of View | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
| Input | Document |
|
| The SQL queries referencing separate tables in which you want to add the JOIN clause. |
| Output | Document |
|
| The incoming SQL queries joined with a JOIN clause. The output from executing this Snap varies based on which table is connected to which input view. |
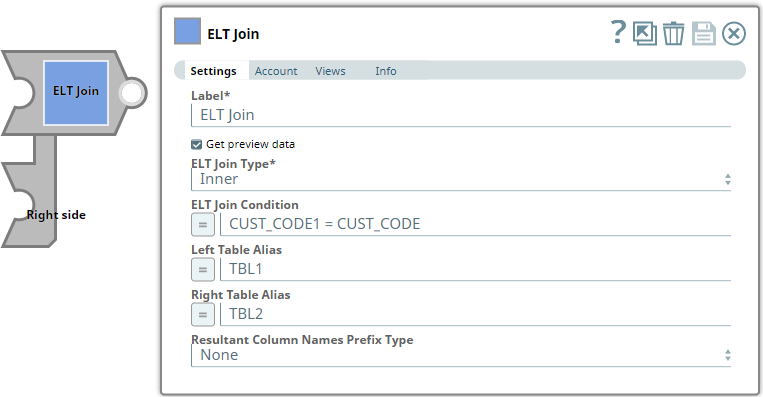
Snap Settings
SQL Functions and Expressions for ELT
You can use the SQL Expressions and Functions supported for ELT to define your Snap or Account settings with the Expression symbol = enabled, where available. This list is common to all target CDWs supported. You can also use other expressions/functions that your target CDW supports.
| Parameter Name | Data Type | Description | Default Value | Example |
|---|---|---|---|---|
| Label | String | Specify a name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | ELT Join | Combined Dataset |
| Get preview data | Check box | Loading | Not selected | Selected |
| ELT Join Type | String/Drop-down list | Choose the join type to use in the SQL. Available options are:
See Snowflake Join Types for more information. See Redshift Join Types for more information. See Azure Synapse Join Types for more information. See Join Types for Databricks on AWS for more information. See Join operation in BigQuery Standard SQL for more information. Natural Joins for Azure Synapse, Databricks Lakehouse Platform and BigQuery Natural Joins are not natively supported by Azure Synapse, Databricks Lakehouse Platform (DLP), and BigQuery databases. But, this Snap uses a series of query rewrite mechanisms to support these Join Types. You can apply these Natural Joins to your data sets in Azure Synapse, Databricks Lakehouse Platform (DLP), and BigQuery, accordingly. More Joins for BigQuery BigQuery does not have the native support for Left Anti and Left Semi join types. But, this Snap uses a series of query rewrite mechanisms to support these Join Types in BigQuery. | Inner | Left outer |
| ELT Join Condition | String/Expression | Specify the condition to initiate the JOIN operation. If you do not specify any condition here, the Snap uses You can specify any SQL expression that has a boolean output (true or false). The ELT Join Condition is ignored if the join type is:
| N/A | CUST_CODE1 = CUST_CODE |
| Left Table Alias | String/Expression | Specify the alias to use for the table in the first input view. This enables you to qualify the columns to join with an alias name and resolve any ambiguity due to identical column names. | N/A | TBL1 |
| Right Table Alias | String/Expression | Specify the alias to use for the table in the second input view. This enables you to qualify the columns to join with an alias name and resolve any ambiguity due to identical column names. | N/A | TBL2 |
| Resultant Column Names Prefix Type | Drop-down list | Not applicable if target database is Databricks Lakehouse Platform (DLP). Choose an option from the list to prefix the resultant columns names with a table alias; this enables the Snap to prevent collision of identical column names in resultant table. Available options are:
For existing Pipelines For Pipelines created prior to 4.24 GA, if you choose the All Columns or the Only Duplicate Columns option in this field, ensure that you also configure an account for the Snap. | None | RT.D_DATE_SK |
Preventing SQL Injection
You can pass Pipeline parameters as values in an SQL expression; however, if you do not phrase the expression properly it can lead to the parameter's name being bound as a value in the database. This potentially incorrect information being inserted into the database is known as SQL injection. It is thus necessary to take precautions when including Pipeline parameters in your SQL expression to prevent SQL injection. Based upon the intended use of the Pipeline parameter, use one or both the following methods to prevent accidental SQL injection:
Method-1: Simple Substitutions
You can reference the Pipeline parameter directly with a JSON-path without enabling expressions.
For example, if you want to use the Pipeline parameter, name, which contains the value of a column in the ELT Join Condition field:
colname = _name
Method-2: Dynamic Substitutions
You must enable expressions when using Pipeline parameters for dynamic substitutions. Format the SQL expression, except the Pipeline parameter's reference, as a string.
For example, if you want to use the Pipeline parameter, name, which contains the value of a column in the ELT Join Condition field:
_columnname + “= _name”
The Snap evaluates the expression and also carries out path substitutions.
Here is how it works
The Snap pre-processes the query to extract any JSON-Paths and converts them to bound parameters. For example, consider the following query:
_columnname + “= _name”
The Snap converts this query into the following before turning it into a prepared statement for the database:
colname = ?
The Snap evaluates the JSON-Path to get the value to bind the Pipeline parameter in the prepared statement.
Using escape characters
When expressions are disabled, use \ as an escape character to treat underscore (_) as a string.
For example:
colname = \_name
Troubleshooting
| Error | Reason | Resolution |
|---|---|---|
Syntax error when database/schema/table name contains a hyphen (-) such as in (CDW: Azure Synapse) | Azure Synapse expects any object name containing hyphens to be enclosed between double quotes as in "<object-name>". | Ensure that you use double quotes for every object name that contains a hyphen when your target database is Azure Synapse. For example: default."schema-1"."order-details". |
Examples
Performing Inner Join
We need a query that contains a JOIN clause. This example demonstrates how we can use the ELT Join Snap to build a query with the JOIN clause.
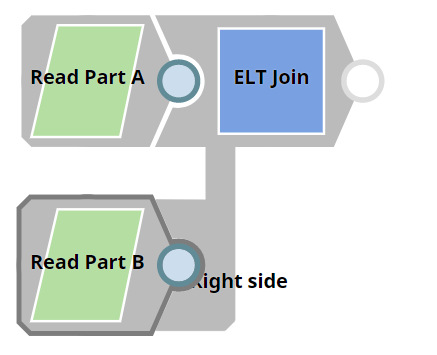
First, we build SELECT queries to read the target tables. To do so, we can use two ELT Select Snaps, in this example: Read Part A and Read Part B. Each of these Snaps is configured to output a SELECT * query to read the target table in the database. Additionally, these Snaps are also configured to show a preview of the SELECT query's execution as shown:
| Read Part A Configuration | Read Part B Configuration |
|---|---|
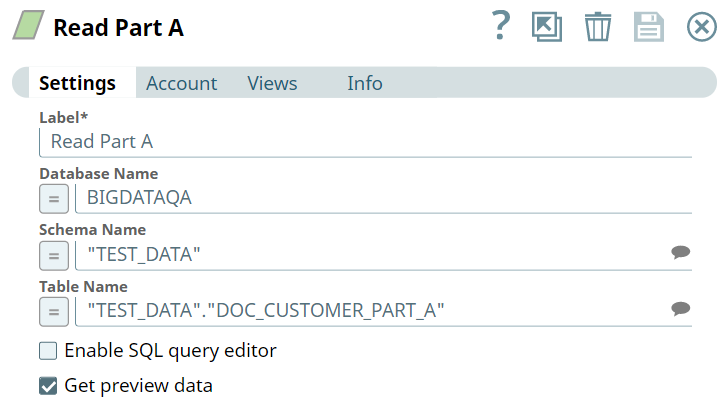 | 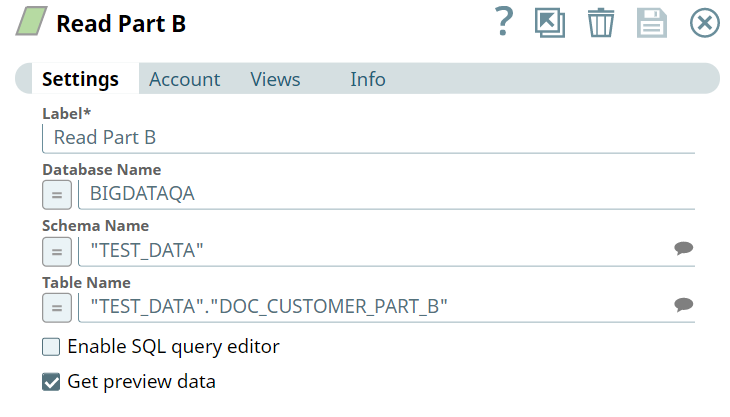 |
A preview of the outputs from the ELT Select Snaps is shown below:
| Read Part A Output | Read Part B Output |
|---|---|
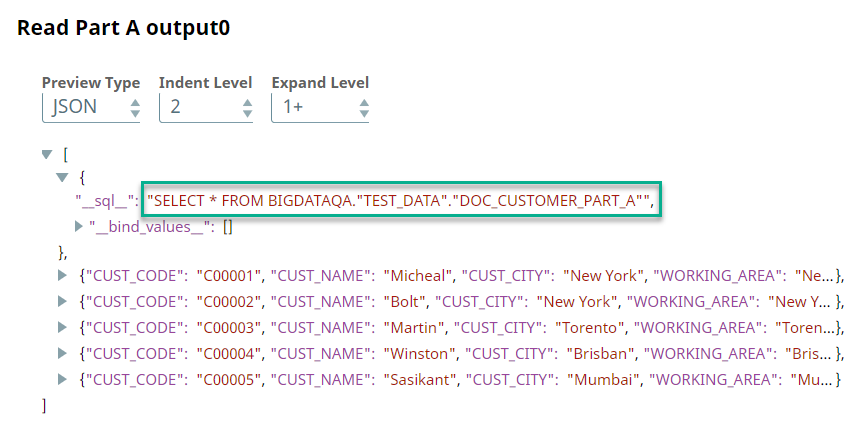 | 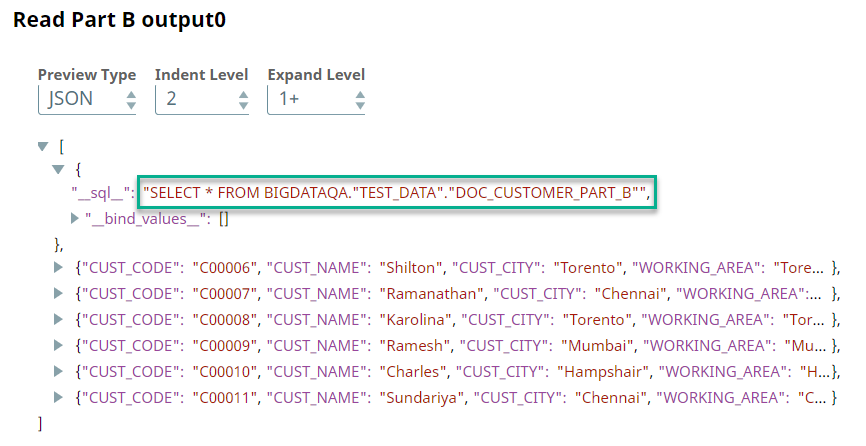 |
The SELECT * queries in both of these Snaps form the inputs for the ELT Join Snap. We want to perform an inner join based on matching values of the CUST_CODE column in the tables. Accordingly, this Snap is configured as shown below:
Upon execution, the ELT Join Snap combines both incoming SELECT * queries and adds the JOIN clause.
A preview of the ELT Join Snap's output is shown below:
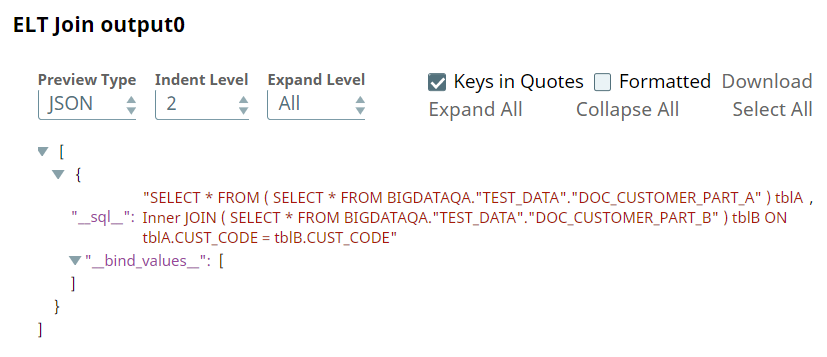
We can also add an ELT Insert-Select Snap downstream and write the result of this query into another table.
Preventing Collision of Identical Columns in Resultant Column Names
In this example, we retrieve data from two tables which are in Snowflake database. We filter the records based on certain clauses and join the queries using a JOIN clause to get the resultant identical columns without any collision. We use the the ELT Join Snap to achieve this.
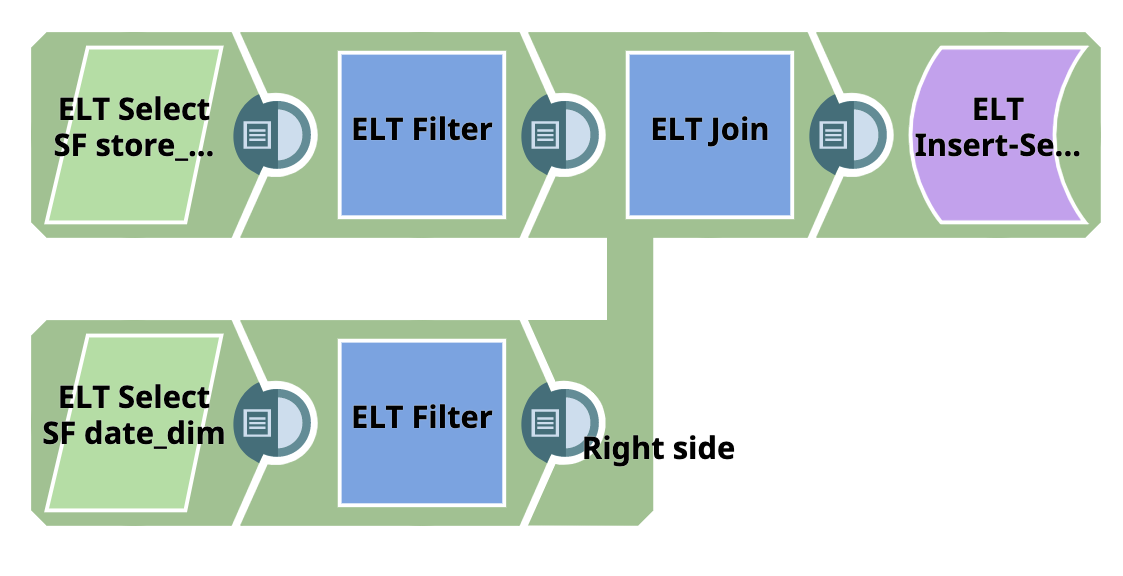
First we use two ELT Select Snaps to retrieve data from the SF store and SF date_dim tables respectively. We configure the ELT Select Snaps as shown below; the respective output views are as shown below.
| ELT Select Snaps | Output |
|---|---|
|
|
|
|
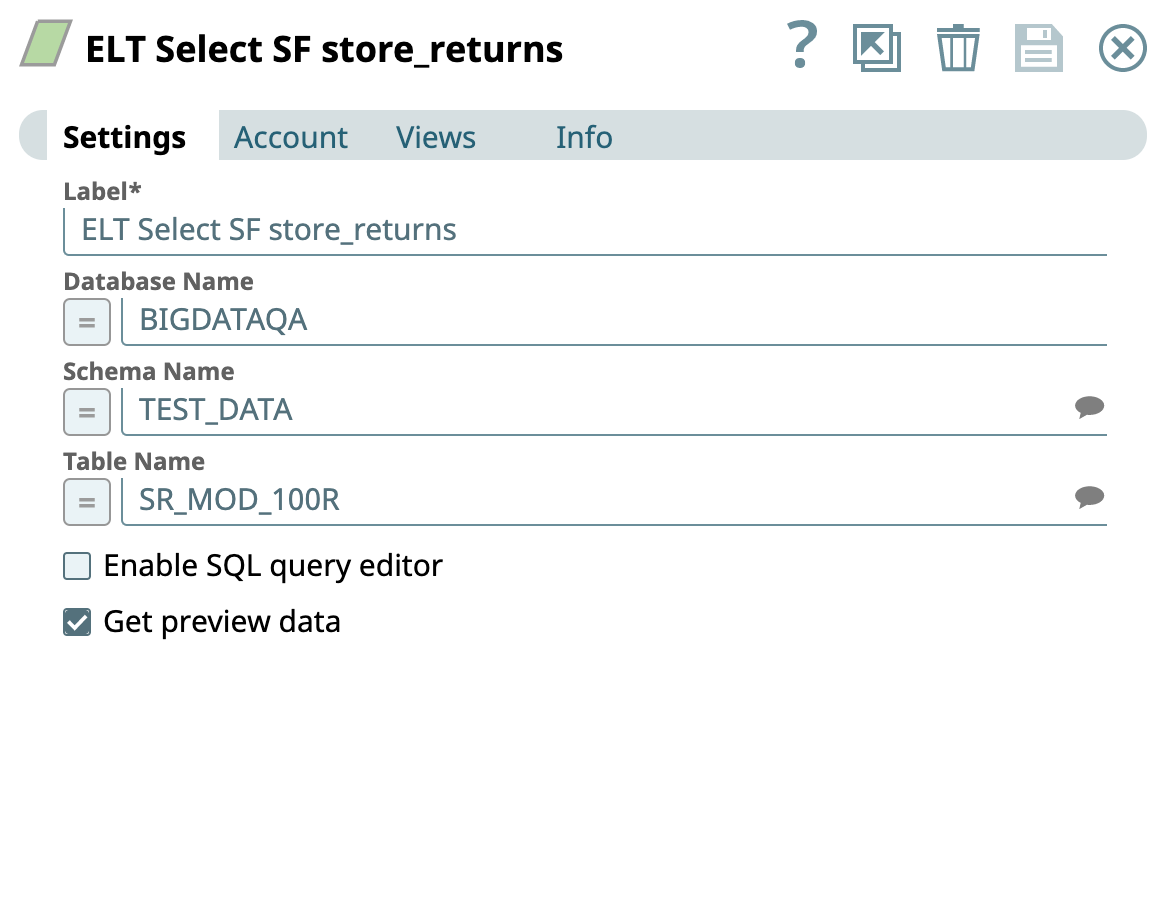
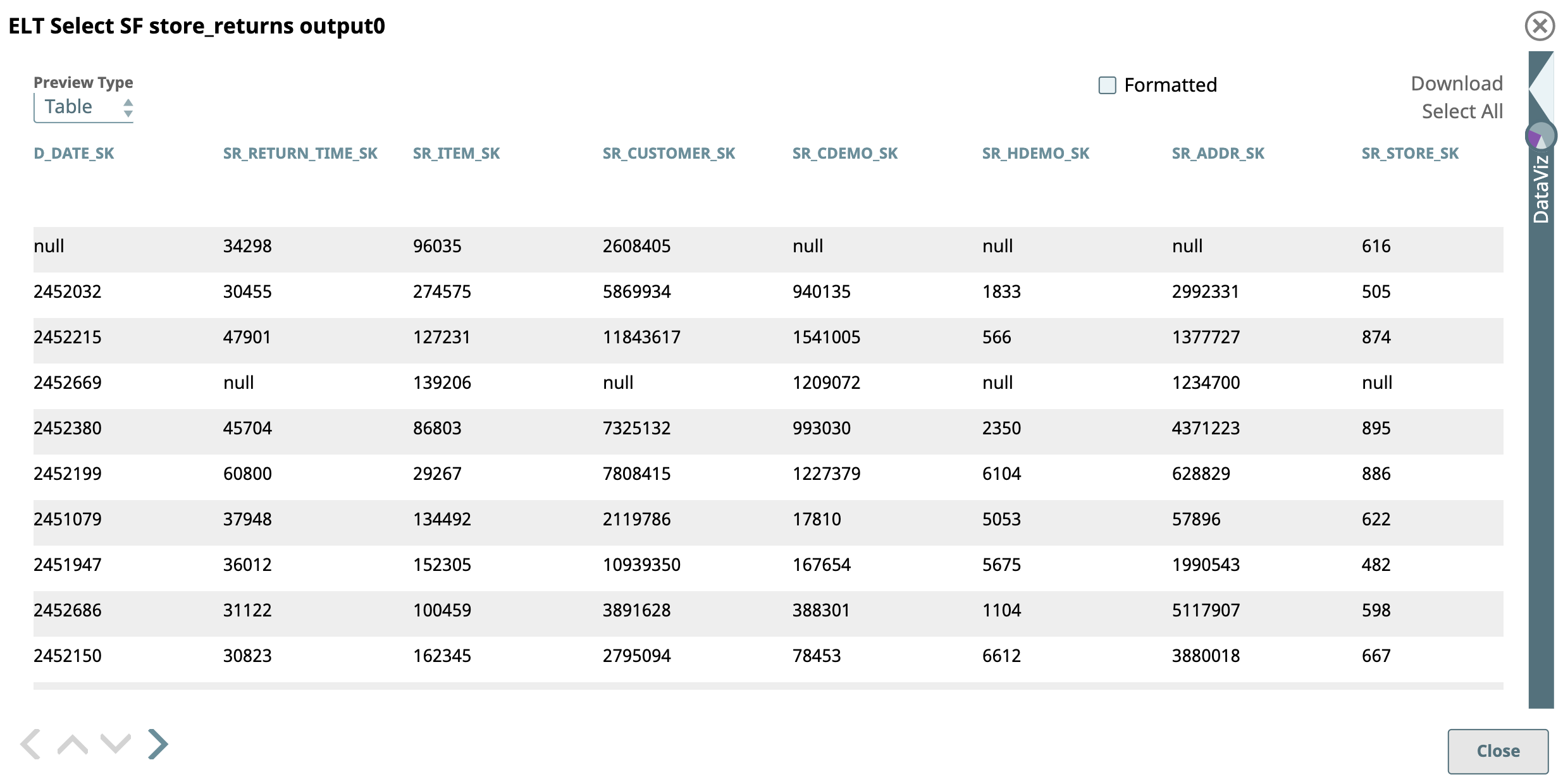
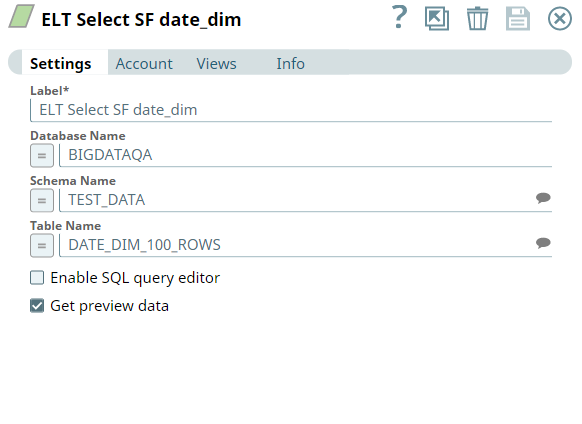
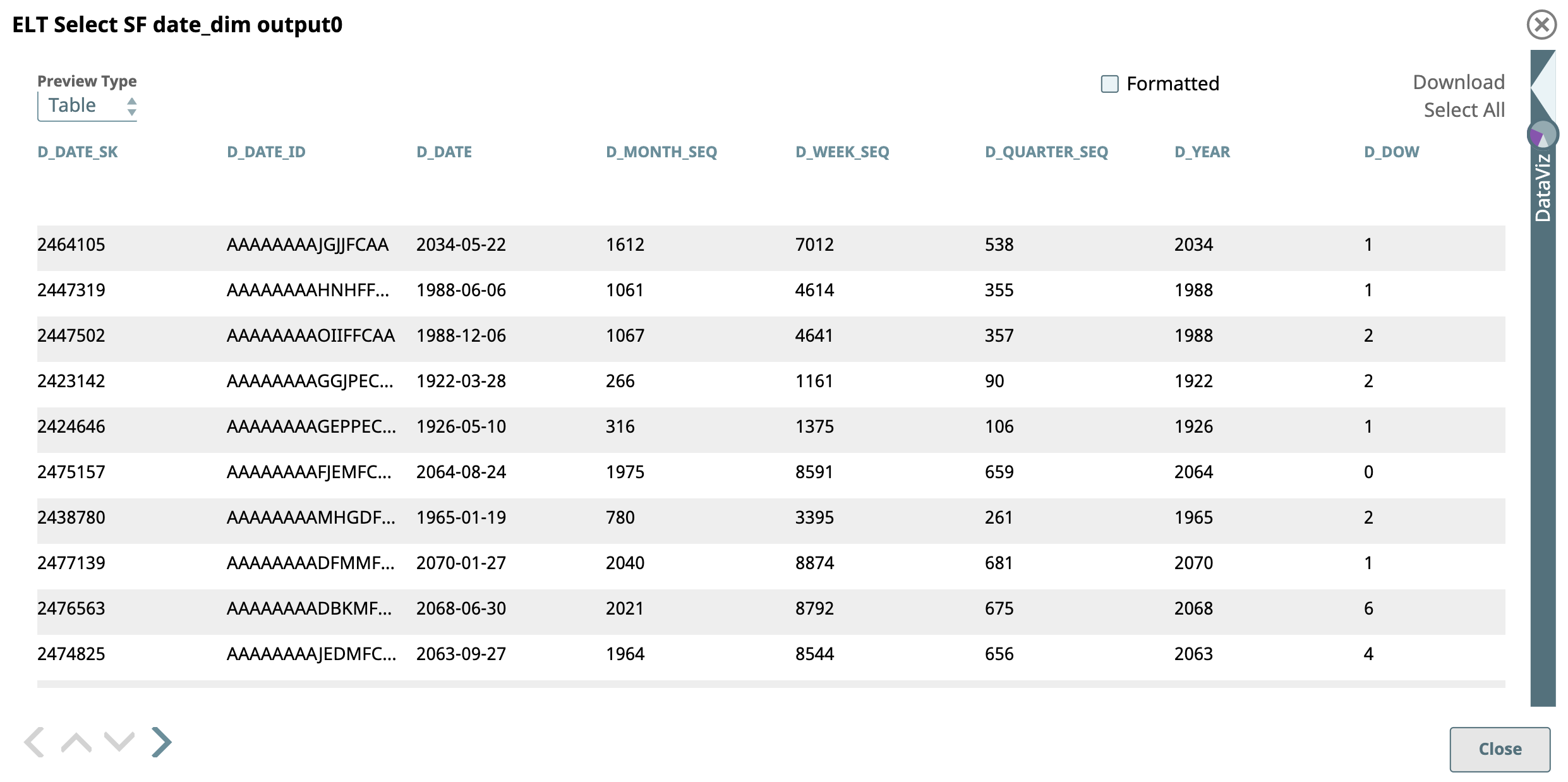
Then, we configure the ELT Filter Snaps with the following filter conditions.
| ELT Filter Snaps | Output |
|---|---|
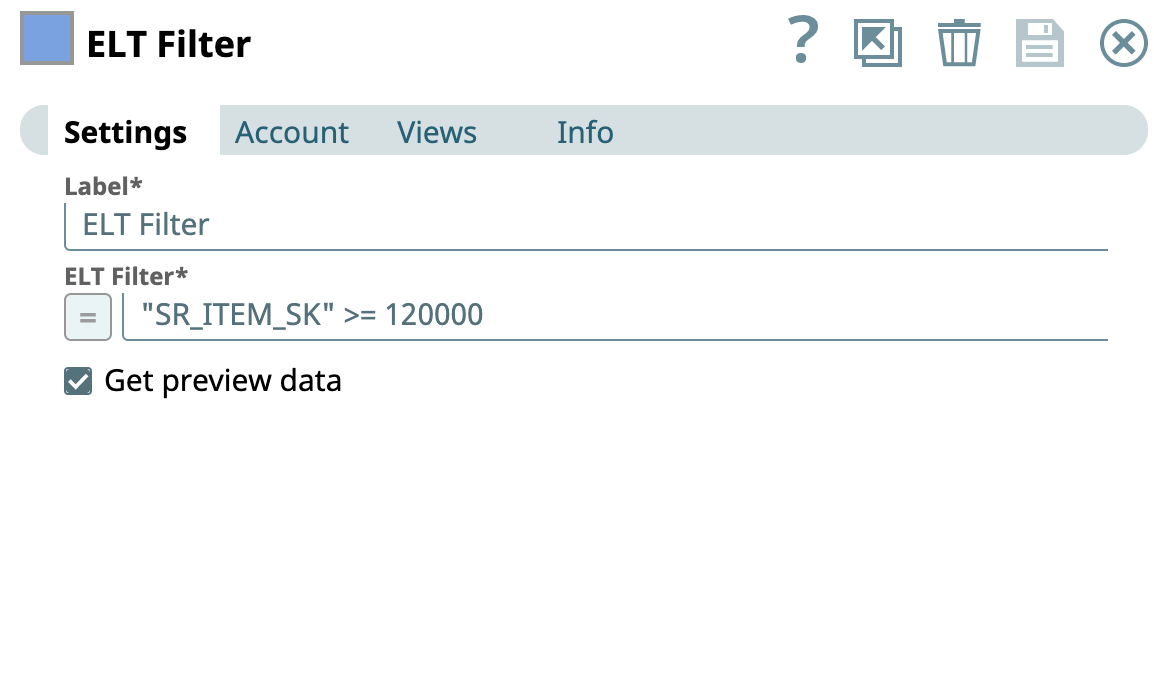
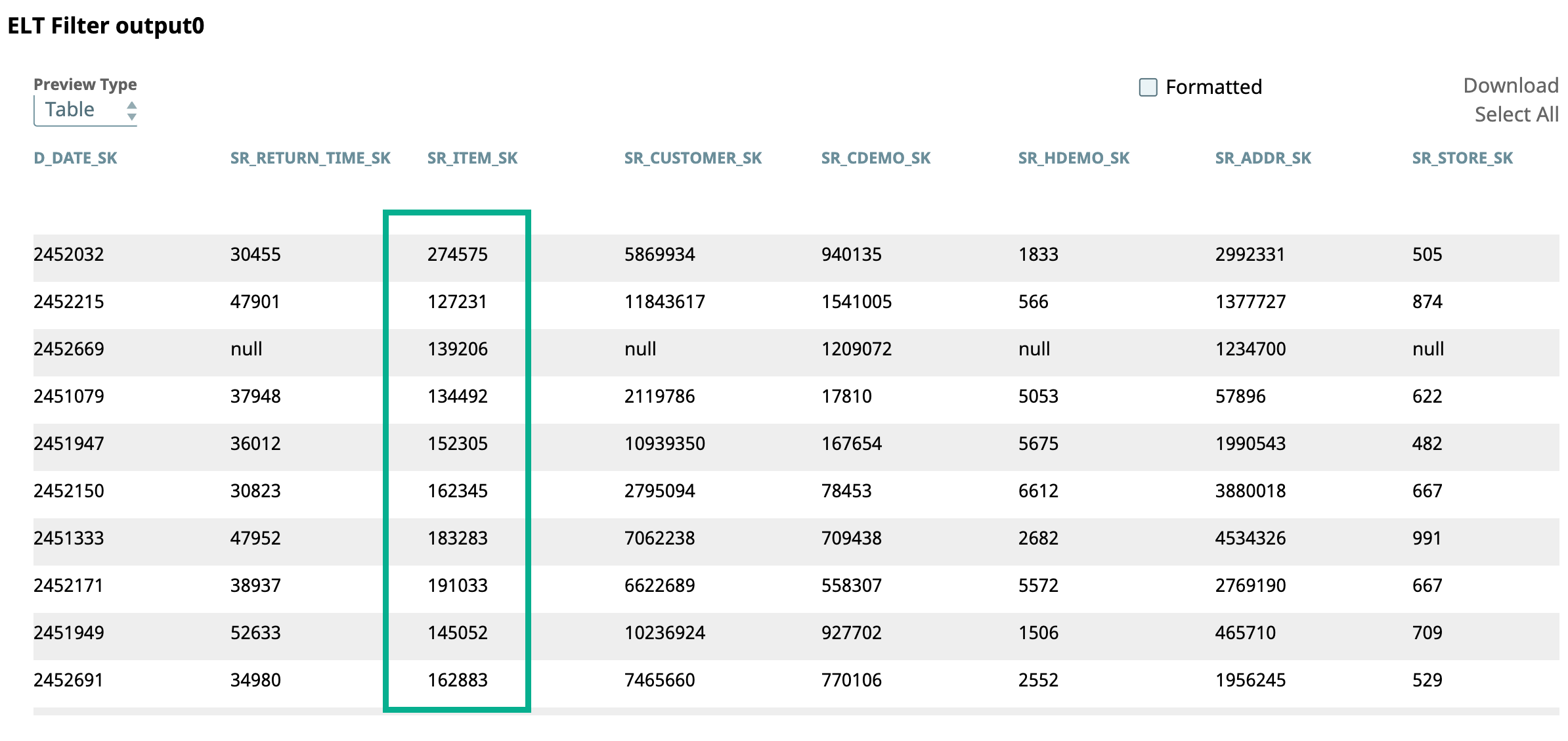
Filter condition: "SR_ITEM_SK">=120000
| Filters the records by SR_ITEM_SK column whose values are greater than or equal to 120000.
|
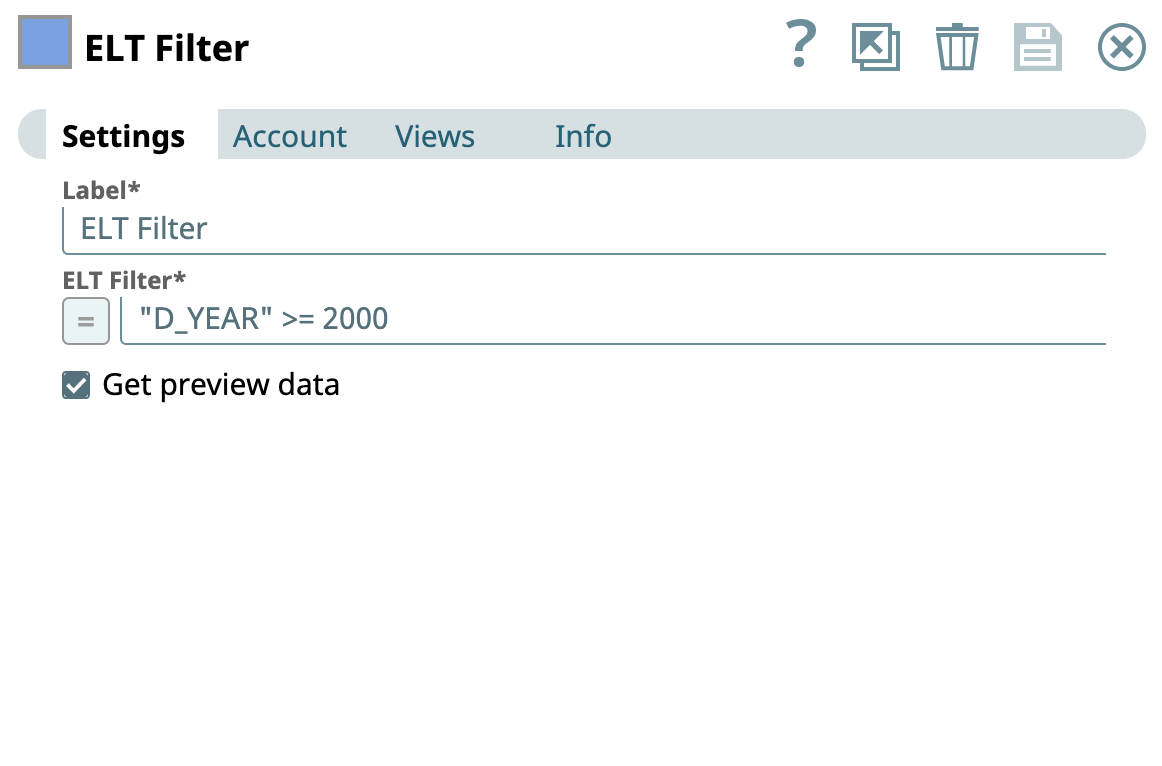
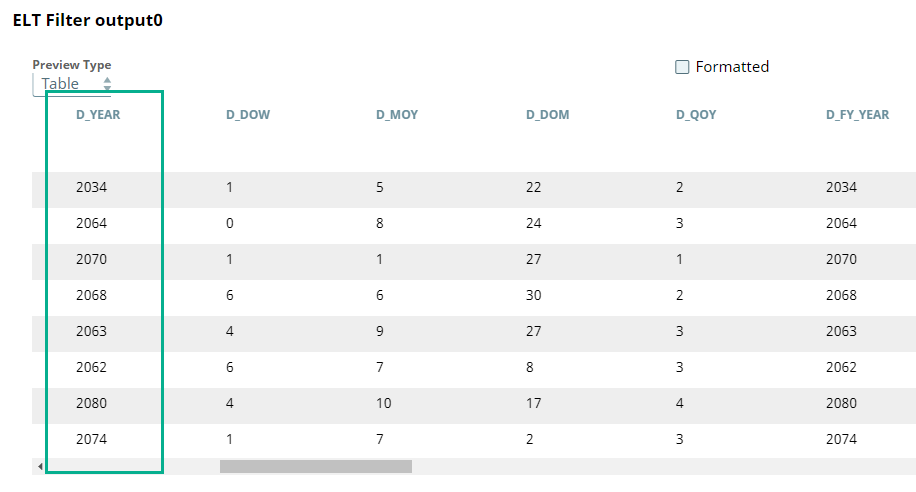
Filter condition: "D_YEAR">=2000
| Filters the records by year greater than or equal to 2000.
|
Then, we configure the ELT Join Snap to perform a left outer join based on the matching values of the D_DATE_SK column in both the tables by applying a Join condition. Note that we select Only Duplicate Columns for Resultant Column Names Prefix Type to avoid collision of identical columns in the resultant output.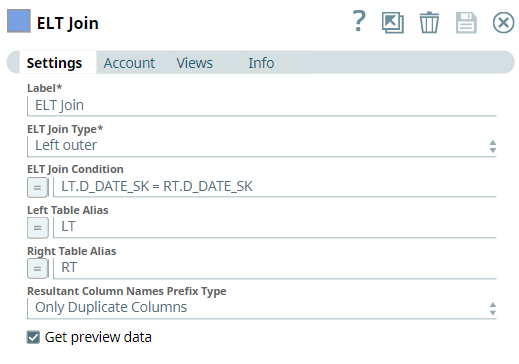
Upon execution, the ELT Join Snap combines both the incoming SELECT queries and adds the JOIN clause. The Snap prefixes the alias names to identical columns. A preview of the output is as shown below: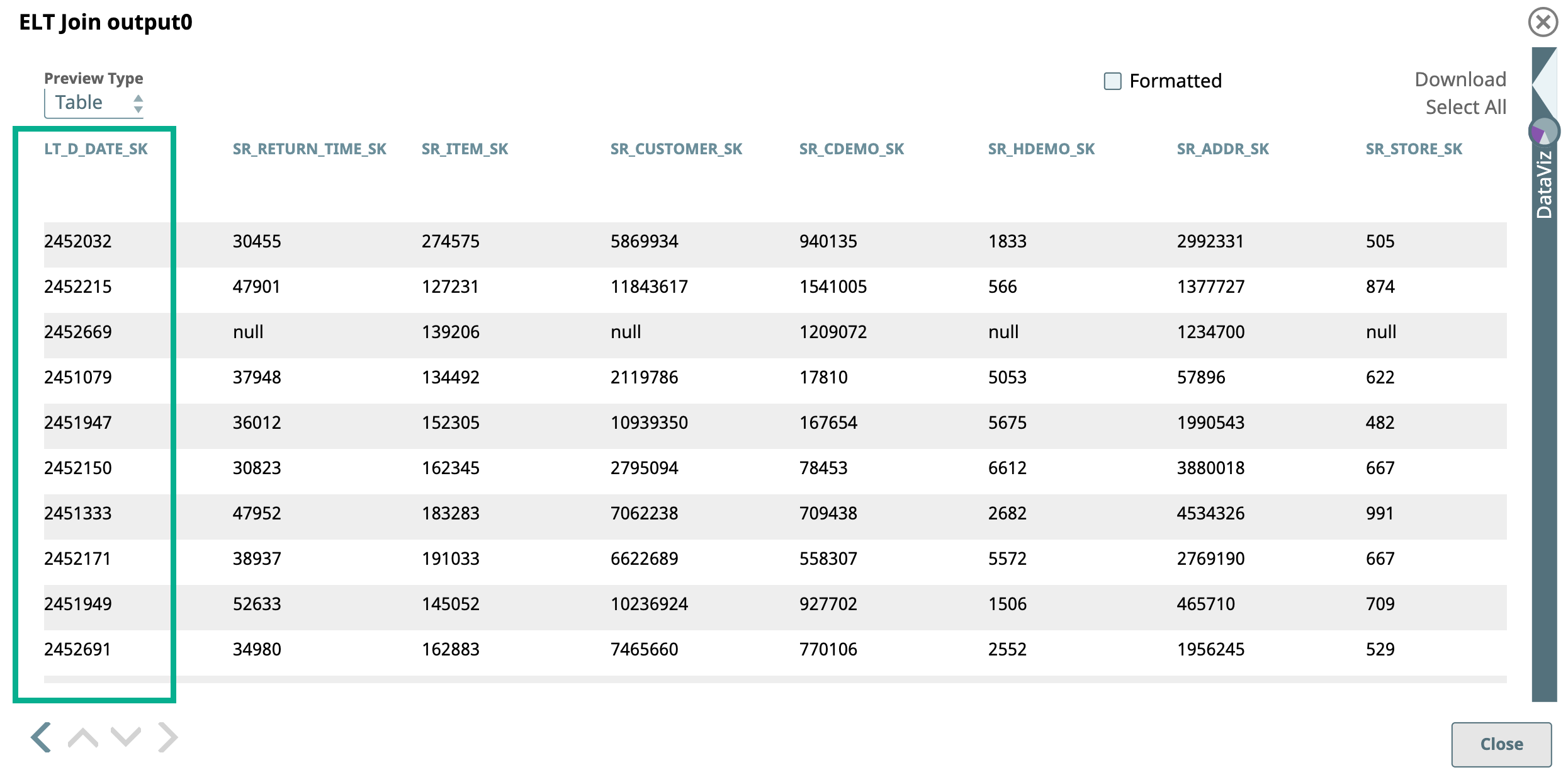
We can also add an ELT Insert-Select Snap downstream and write the result of this query into another table.
Downloads
Important Steps to Successfully Reuse Pipelines
- Download and import the Pipeline into SnapLogic.
- Configure Snap accounts as applicable.
- Provide Pipeline parameters as applicable.
Snap Pack History
Release | Snap Pack Version | Date | Type | Updates |
|---|---|---|---|---|
| May 2025 | 441patches31159 | Latest | Fixed the intermittent null expression errors with the ELT Snap Pack, where some malformed unique identifier suffixes to the Snaps' SQL statements were hindering the SQL statement execution, thereby causing the pipelines to fail. | |
| May 2025 | main31019 | Stable | Updated and certified against the current SnapLogic Platform release. | |
| February 2025 | 440patches30341 | Latest | Fixed an issue with the ELT Merge Into Snap where the Snap fails to perform the MERGE INTO operation on the RedShift target tables with the error - Failed to set search_path when the specified target Database schema is not one of the default schemas ("$user”, public). | |
| February 2025 | main29887 | Stable | Updated and certified against the current SnapLogic Platform release. | |
| November 2024 | 439patches29443 | Latest | Fixed an issue with the ELT Merge Into Snap where the Snap fails to perform the MERGE INTO operation on the RedShift target tables with the error - There were no target table columns found. when the specified target Database schema is not one of the default schemas ("$user”, public). This issue did not exist before the May 2024 release. | |
| November 2024 | main29029 | Stable | Updated and certified against the current SnapLogic Platform release. | |
| August 2024 | 438patches28010 | Latest | The ELT Insert-Select Snap no longer fails to execute SQL statements that contain multiple multiline comment character pairs (/* and */) and/or multiple quoted substrings. Quoted substrings refer to schema, database, table, or column identifiers, which are delimited to allow special characters.
| |
| August 2024 | main27765 | Stable | Upgraded the jOOQ library for the ELT Snap Pack from v3.9.1 to v3.17.x. | |
| May 2024 | 437patches27372 | Latest | Enhanced the pipeline execution statistics of ELT Insert-Select Snap to be displayed in its output view and to allow downloading detailed stats as a JSON file that includes additional statistics ( | |
| May 2024 | 437patches27246 | Latest | Enhanced the ELT Execute Snap to display SQL execution statistics in the pipeline execution statistics and the output view of the Snap for all SQL statements executed. The Snap also allows you to download detailed stats as a JSON file that includes additional statistics ( | |
| May 2024 | 437patches26846 | Latest | Fixed the issue with the ADLS Gen 2 account connection where some conflicts between internally used Azure libraries prevented the ELT Load Snap from reading files. | |
Fixed an issue with the ELT Merge Into Snap where the Snap’s SELECT SQL statement could not fetch the target tables information from the PG_TABLE_DEF catalog table of the Amazon Redshift instance.
PG_TABLE_DEF is a Redshift system catalog table that contains information about the tables including table names, column names, data types among their other metadata. | ||||
| Enhanced the ELT Load Snap to support loading data from nested AVRO, JSONLines, ORC, or Parquet files in Azure storage to the target tables in a Databricks Lakehouse Platform (DLP) instance. Only two Load actions are supported: Drop and create table and Append table. | ||||
| May 2024 | main26341 | Stable | Fixed an issue where the ELT Merge Into Snap failed to load data into the Google BigQuery target table because of the error: | |
| February 2024 | 436patches25953 | Latest | Enhanced the ELT Load Snap’s capabilities to allow loading flat and nested data sets (from canonical and non-canonical formats) from your Parquet files to the target tables in Snowflake. Learn more about the usage of this feature at Load data from Parquet files and in the following example Pipelines: | |
| February 2024 | main25112 | Stable | Updated and certified against the current SnapLogic Platform release. | |
| November 2023 | 435patches24461 | Latest | Fixed an issue with the ELT Merge Into Snap that caused inaccurate aliases and table identifiers in its generated SQL statement. | |
| November 2023 | 435patches23671 | Latest and Stable |
| |
| November 2023 | main23721 | Stable |
| |
| August 2023 | main22460 | Stable |
| |
| May 2023 | N/A | Stable | Fixed a null pointer exception so no 5XX errors can occur if you download non-existent query details from the Pipeline Execution Statistics of an ELT (write-type) Snap. | |
| May 2023 | main21015 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| February 2023 | 432patches20978 | Latest | Fixed an issue with the ELT SCD2 Snap where the COLLATE column constraint (used in the new target table definition for Snowflake) resulted in an incorrect syntax internally, causing the pipeline to fail. The load operation succeeds with this fix. | |
| February 2023 | main19844 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| November 2022 | 431patches19240 |
| Latest |
|
| November 2022 | main18944 | Stable | ELT Insert-Select, ELT Merge Into, and ELT SCD2 Snaps show the following statistics on execution.
| |
| September 2022 | 430patches18196 | Latest | New SnapThe ELT Create View Snap enables you to create a new view when the view does not exist in the target database and/or schema or if the view already exists in the database and/or schema, and you choose to drop the existing view and re-create it. Enhancements
| |
| August 2022 | main17386 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.29-Patch | 429patches16665 | Latest |
| |
| 4.29-Patch | 4.29patches16287 | Latest | Fixed an issue with the ELT SCD2 Snap where the Snap was rounding off decimal values to the nearest integer—the value 57.601000000000 in the source table was written to the target table as 58.000000000. | |
| 4.29 | main15993 | Stable |
| |
| 4.28-Patch | 428patches15638 | Latest | Fixed the issue with ELT Merge Into Snap where the Snap erroneously modified the target table column name when it contained the target table name, due to a misinterpretation of the target table name aliases. | |
| 4.28-Patch | 428patches15290 | Latest |
| |
| 4.28 | main14627 | Stable |
| |
| 4.27-Patch | 427patches13923 | Latest |
| |
| 4.27-Patch | 427patches13539 | Latest |
| |
| 4.27-Patch | 427patches13030 | Latest |
| |
| 4.27 | main12833 | Stable |
| |
| 4.26-Patch | 426patches12534 | Latest |
| |
| 4.26-Patch | 426patches12021 | Latest |
| |
| 4.26-Patch | 426patches11646 | Latest |
| |
| 4.26-Patch | 426patches11323 | Latest |
| |
| 4.26-Patch | 426patches11262 | Latest |
| |
| 4.26 | main11181 | Stable |
| |
| 4.25-Patch | 425patches10017 | Latest |
| |
| 4.25-Patch | 425patches9725 | Latest |
| |
| 4.25 | main9554 | Stable |
| |
| 4.24-Patch | 424patches8793 | Latest |
No changes are needed to your existing Pipelines.
Behavior Change The behavior of ELT Load Snap for Load Action during Pipeline validation across the supported databases is as follows: Append rows to existing table: Does not append the data from the source files into the target table. Overwrite existing table: Does not overwrite the data. Drop and Create table: Does not drop the target table even if it exists, but the Snap creates a new target table if a table does not exist. Alter table: Does not modify the schema of the target table. | |
| 4.24 | main8556 | Stable |
Updates the Snap Pack with the following features:
| |
| 4.23 | main7430 | Stable | Introduces the following Snaps:
| |
4.22 | main6403 | Stable | Introduces the ELT Snap Pack that provides you with the Extract, Load, and Transform (ELT) capabilities. Use the following Snaps to build SQL queries that are executed in the Snowflake database:
|
See Also
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.