In this article
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
You can use this Snap to process data in bulk. The Snap uses Oracle SQL*Loader internally to perform the bulk load action. The input data is first written to either a temporary data file (on a Windows JCC) or a named pipe (on a Linux JCC). Then the Oracle SQL*Loader loads the data from the data file/named pipe into the target table.
| Note |
|---|
The Snap uses EZCONNECT to connect to Oracle. It does not use TNSNames or LDAP connections. |
Upcoming
| Multiexcerpt include macro | ||||||||
|---|---|---|---|---|---|---|---|---|
|
Snap type: | Write | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Known Issues: |
| |||||||||||||
| Support and limitations: | Columns in a table that do not contain actual values but are generated based on a formula are referred as virtual columns. Tables containing virtual columns cannot be bulk loaded using this Snap. The table must only contain actual values to be bulk loaded. A workaround for this issue is to use a view that specifies only the non-virtual columns and use that view for the bulk load. For more information about creating a view in the Oracle database, refer to Creating a view in Oracle database. The BLOB type is not supported by this Snap. | |||||||||||||
| Support for Ultra pipelines | Does not work in Ultra Pipelines. | |||||||||||||
| Account: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Oracle Account for information on setting up this type of account. | |||||||||||||
| Views: |
| |||||||||||||
Settings | ||||||||||||||
Label* | Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. | |||||||||||||
Schema name | Specify the database schema name. Selecting a schema, filters the Table name list to show only those tables within the selected schema. The The suggestions in the Schema field are populated only when at least a single table exists in the schema. If no tables exist to use that schema, only SYS, SYSTEM, and XDB are populated. The values can be passed using the Pipeline parameters but not the upstream parameter. Default Value: [None] | |||||||||||||
Table name* | Specify the table on which to execute the bulk load operation.
Default Value: [None] | |||||||||||||
Create table if not present |
Default Value: Not selected | |||||||||||||
Sqlldr absolute path | Specify the absolute path of the sqlldr program in the JCC's file system. If empty, the Snap will look for it in the JCC's environment variable PATH.
Default Value: [None] Example: /u01/app/oracle/product/11.2.0/xe/bin/sqlldr (For Linux) C:\app\Administrator\product\11.2.0\client_1\bin\sqlldr.exe (For Windows) | |||||||||||||
Insert mode | Available insert modes when loading data into table.
Default Value: APPEND | |||||||||||||
Maximum error count* | Specify the maximum number of rows which can fail before the bulk load operation is stopped. Default Value: 50 | |||||||||||||
Use direct path load | Select this check box to use direct path load mode of SQLLDR program. Typically, used when loading large data sets. This substantially improves the bulk load performance by reducing loading time. Default Value: Selected | |||||||||||||
| Skip virtual columns | Select this checkbox to skip virtual columns to prevent errors while loading data. Default Value: Selected | |||||||||||||
| Additional SQL Loader Parameters | Use this field set to define additional SQL Load parameters if any. This field set contains Param Name and Param Value fields. | |||||||||||||
| Parameter Name | Choose the parameter name for SQL. Available options are:
See SQL* Loader parameters for more information. Default Value: N/A | |||||||||||||
| Parameter Value | Specify the value for the parameter selected above. Default Value: N/A | |||||||||||||
| Column Length Overrides | Use this field set to define values for overriding the column length that includes CLOB (Character Large Object) and NCLOB (National Character Large Object) data types. Add each column in a separate row. The field set contains the following fields:
| |||||||||||||
| Column Name | Specify or select the name of the column in the table that you want to load. Default Value: N/A | |||||||||||||
| Length (in bytes) | Specify a value (in bytes) for the column length. Default Value: N/A | |||||||||||||
|
| |||||||||||||
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|
Example
This example loads 6 records to table TECTONIC.TERENCE_BULK_TEST2 with Oracle Bulk Load Snap, and three of them are invalid records which cannot be inserted and will be routed to the error view.
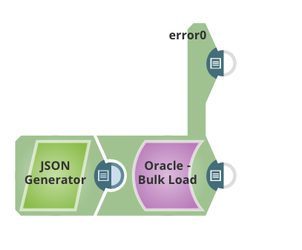
The definition of Table TECTONIC.TERENCE_BULK_TEST2 :
| Code Block |
|---|
CREATE TABLE "TECTONIC"."TERENCE_BULK_TEST2" ( "id" NUMBER, "first_name" VARCHAR2(4000), "last_name" VARCHAR2(4000) ) |
The input data defined in JSON Generator Snap:
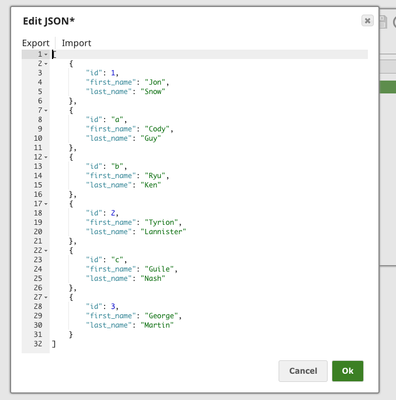
There are 3 rows of data whose ID column are strings, which is invalid when inserting into table TECTONIC.TERENCE_BULK_TEST2.
The settings of the Oracle Bulk Load Snap: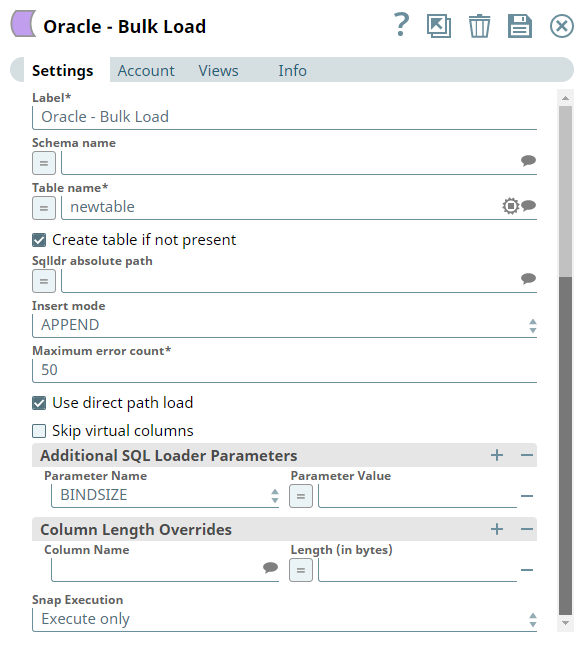
The output of output view:

The output of the error view, the three invalid rows are routed here:

Snap Pack History
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|