Oracle - Bulk Load
- Kalpana Malladi
- Aparna Tayi (Unlicensed)
- Mohammed Iqbal
In this article
Overview
You can use this Snap to process data in bulk. The Snap uses Oracle SQL*Loader internally to perform the bulk load action. The input data is first written to either a temporary data file (on a Windows JCC) or a named pipe (on a Linux JCC). Then the Oracle SQL*Loader loads the data from the data file/named pipe into the target table.
The Snap uses EZCONNECT to connect to Oracle. It does not use TNSNames or LDAP connections.
Upcoming
Snap type: | Write | |||||||
|---|---|---|---|---|---|---|---|---|
| Known Issues: |
| |||||||
| Support and limitations: | Columns in a table that do not contain actual values but are generated based on a formula are referred as virtual columns. Tables containing virtual columns cannot be bulk loaded using this Snap. The table must only contain actual values to be bulk loaded. A workaround for this issue is to use a view that specifies only the non-virtual columns and use that view for the bulk load. For more information about creating a view in the Oracle database, refer to Creating a view in Oracle database. The BLOB type is not supported by this Snap. | |||||||
| Support for Ultra pipelines | Does not work in Ultra Pipelines. | |||||||
| Account: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Oracle Account for information on setting up this type of account. | |||||||
| Views: |
| |||||||
Settings | ||||||||
Label* | Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. | |||||||
Schema name | Specify the database schema name. The suggestions in the Schema field are populated only when at least a single table exists in the schema. If no tables exist to use that schema, only SYS, SYSTEM, and XDB are populated. The values can be passed using the Pipeline parameters but not the upstream parameter. Default Value: [None] | |||||||
Table name* | Specify the table that the rows will be inserted into. This list is populated based on the tables associated with the selected schema. The values can be passed using the Pipeline parameters but not the upstream parameter. Default Value: [None] | |||||||
Create table if not present | Select this checkbox to automatically create the target table if it does not exist.
Due to implementation details, a newly created table is not visible to subsequent database Snaps during runtime validation. If you want to immediately use the newly updated data you must use a child Pipeline that is invoked through a Pipeline Execute Snap. Default Value: Not selected | |||||||
Sqlldr absolute path | Specify the absolute path of the sqlldr program in the JCC's file system. If empty, the Snap will look for it in the JCC's environment variable PATH. On Windows, a value must be specified and must be entered manually and the path to the sqlldr executable should include the ".exe" extension to ensure the executable is actually referenced. Default Value: [None] Example: /u01/app/oracle/product/11.2.0/xe/bin/sqlldr (For Linux) C:\app\Administrator\product\11.2.0\client_1\bin\sqlldr.exe (For Windows) | |||||||
Insert mode | Available insert modes when loading data into table.
Default Value: APPEND | |||||||
Maximum error count* | Specify the maximum number of rows which can fail before the bulk load operation is stopped. Default Value: 50 | |||||||
Use direct path load | Select this check box to use direct path load mode of SQLLDR program. Typically, used when loading large data sets. This substantially improves the bulk load performance by reducing loading time. Default Value: Selected | |||||||
| Skip virtual columns | Select this checkbox to skip virtual columns to prevent errors while loading data. Default Value: Selected | |||||||
| Additional SQL Loader Parameters | Use this field set to define additional SQL Load parameters if any. This field set contains Param Name and Param Value fields. | |||||||
| Parameter Name | Choose the parameter name for SQL. Available options are:
See SQL* Loader parameters for more information. Default Value: N/A | |||||||
| Parameter Value | Specify the value for the parameter selected above. Default Value: N/A | |||||||
| Column Length Overrides | Use this field set to define values for overriding the column length that includes CLOB (Character Large Object) and NCLOB (National Character Large Object) data types. Add each column in a separate row. The field set contains the following fields:
| |||||||
| Column Name | Specify or select the name of the column in the table that you want to load. Default Value: N/A | |||||||
| Length (in bytes) | Specify a value (in bytes) for the column length. Default Value: N/A | |||||||
Snap execution | Select one of the three modes in which the Snap executes. Available options are:
| |||||||
In a scenario where the Auto commit on the account is set to true, and the downstream Snap does depends on the data processed on an Upstream Database Bulk Load Snap, use the Script Snap to add delay for the data to be available.
For example, when performing a create, insert and a delete function sequentially on a pipeline, using a Script Snap helps in creating a delay between the insert and delete function or otherwise it may turn out that the delete function is triggered even before inserting the records on the table.
Example
This example loads 6 records to table TECTONIC.TERENCE_BULK_TEST2 with Oracle Bulk Load Snap, and three of them are invalid records which cannot be inserted and will be routed to the error view.
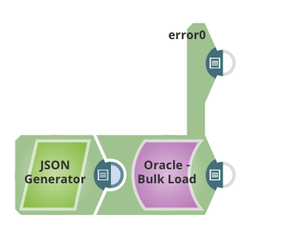
The definition of Table TECTONIC.TERENCE_BULK_TEST2 :
CREATE TABLE "TECTONIC"."TERENCE_BULK_TEST2" ( "id" NUMBER, "first_name" VARCHAR2(4000), "last_name" VARCHAR2(4000) )
The input data defined in JSON Generator Snap:
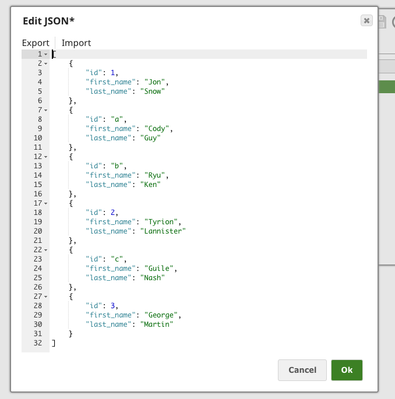
There are 3 rows of data whose ID column are strings, which is invalid when inserting into table TECTONIC.TERENCE_BULK_TEST2.
The settings of the Oracle Bulk Load Snap: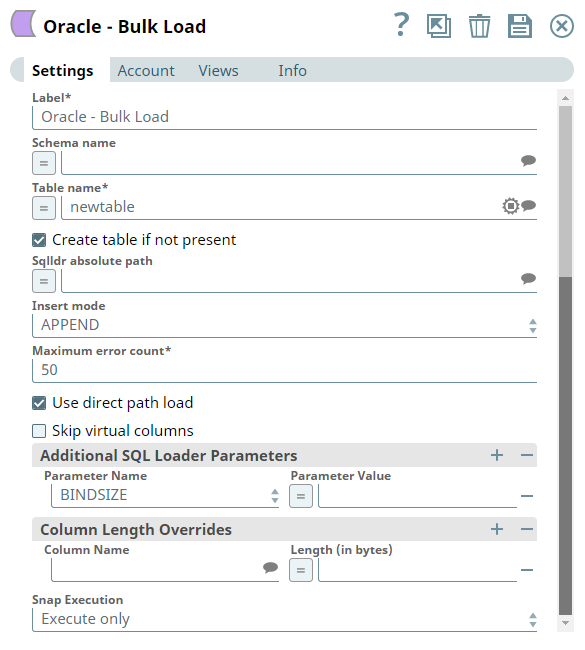
The output of output view:

The output of the error view, the three invalid rows are routed here:

Snap Pack History
| Release | Snap Pack Version | Date | Type | Updates |
|---|---|---|---|---|
| February 2025 | 440patches30071 | Latest | Fixed the Null Pointer Exception (NPE) issue in the Oracle Snaps. Now, these Snaps display an exception error instead of NPE when the URL properties (key and value) and either key or value are empty. | |
| February 2025 | main29887 | Stable | Updated and certified against the current SnapLogic Platform release. | |
| November 2024 | 439patches29008 | Latest | Fixed an issue with Oracle Execute, Select, and Stored Procedure Snaps where the data was displayed in an unexpected structure and without the actual row address value when querying table columns of | |
| November 2024 | main29029 | Stable | Updated and certified against the current SnapLogic Platform release. | |
| August 2024 | 438patches27870 | Latest | Fixed an issue with the Oracle - Merge Snap that caused a date format error when the merge condition was used with the TO_DATE() function. | |
| August 2024 | main27765 | Stable |
| |
| May 2024 | 437patches26651 | Latest |
| |
| May 2024 | 437patches26346 | Latest | Fixed an issue with the Oracle - Execute Snap that displayed an error when handling | |
| May 2024 | main26341 | Stable | Updated the Delete Condition (Truncates a Table if empty) field in the Oracle - Delete Snap to Delete condition (deletes all records from a table if left blank) to indicate that all entries will be deleted from the table when this field is blank, but no truncate operation is performed. | |
| February 2024 | 436patches26208 | Latest | Fixed an issue with Oracle - Bulk Load Snap that intermittently displayed a | |
| February 2024 | 436patches25696 | Latest |
Behavior Change: As part of | |
| February 2024 | main25112 | Stable | Updated and certified against the current SnapLogic Platform release. | |
| November 2023 | 435patches24769 | Latest | Fixed an issue with the Oracle Snap Pack that required the i18n extensions to be present when the Oracle database instance was in a specific language. | |
| November 2023 | 435patches24445 | Latest |
| |
| November 2023 | 435patches23823 | Latest |
| |
| November 2023 | main23721 |
| Stable | Updated and certified against the current SnapLogic Platform release. |
| August 2023 | 434patches23000 | Latest | The JDBC driver for the Oracle Snap Pack is upgraded from OJDBC6 JAR (v11.2.0.4) to OJDBC10 JAR (v19.20.0.0) in the latest distribution in October 2023 and will be deployed to the stable distribution in the November 2023 release (after the Snaplex upgrade). This upgrade changes specific error codes and status messages. The latest JDBC driver upgrade is backward-compatible. Learn more: Upgrading from Oracle JDBC 11.2.0.4 Driver to 19.20.0.0 Driver. | |
| August 2023 | 434patches22787 | Latest | Fixed an issue with the Oracle-Bulk Load Snap that was not resilient to the errors previously when trying to auto-discover the existing SQLLDR utility paths in the node. The Snap is now robust to those errors. | |
August 2023 | main22460 | | Stable | The Oracle - Execute Snap now includes a new Query type field. When Auto is selected, the Snap tries to determine the query type automatically. |
May 2023 | main21015 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| February 2023 | main19844 | Stable | Upgraded with the latest SnapLogic Platform release. | |
November 2022 | 431patches19781 | Latest | The Oracle-Stored Procedure Snap works as expected and does not fail with the error | |
November 2022 | 431patches19275 | Latest | The Oracle - Stored Procedure Snap now supports stored functions with OUT and INOUT parameters and displays these parameter values in the output along with the | |
| November 2022 | main18944 | Stable | The Oracle Insert Snap now creates the target table only from the table metadata of the second input view when the following conditions are met:
| |
| September 2022 | 430patches17894 | Latest | The Oracle Select Snap now work as expected when the table name is dependent on an upstream input. | |
| August 2022 | 430patches17658 | Latest | The Oracle - Stored Procedure Snap now takes lesser time to execute when calling a stored procedure, because the Snap queries the metadata as required, thereby optimizing the Snap's performance. | |
| August 2022 | main17386 | Stable |
| |
| 4.29 Patch | 429patches16603 | Latest |
| |
4.29 | main15993 |
| Stable | Upgraded with the latest SnapLogic Platform release. |
| 4.28 | main14627 | Stable |
| |
| 4.27 | main12833 | Stable |
| |
| 4.26 | main11181 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.25 | 425patches11008 | Latest |
| |
| 4.25 | main9554 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.24 | main8556 | Stable |
| |
| 4.23 | main7430 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.22 | main6403 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.21 Patch | 421patches6272 | Latest | Fixes the issue where Snowflake SCD2 Snap generates two output documents despite no changes to Cause-historization fields with DATE, TIME and TIMESTAMP Snowflake data types, and with Ignore unchanged rows field selected. | |
| 4.21 Patch | 421patches6144 | Latest | Fixes the following issues with DB Snaps:
| |
| 4.21 Patch | MULTIPLE8841 | Latest | Fixes the connection issue in Database Snaps by detecting and closing open connections after the Snap execution ends. | |
| 4.21 | snapsmrc542 |
| Stable | Updated the Oracle Thin Account and Oracle Thin Dynamic Account, enabling them to connect via Oracle Active Data Guard (ADG). |
4.20 Patch | db/oracle8812 | Latest | Enhances the Oracle Snap Pack to support connections to the Oracle ADG (Active Data Guard) URL. | |
4.20 Patch | db/oracle8803 | Latest | Support for Oracle Database 19c. | |
| 4.20 | snapsmrc535 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.19 Patch | db/oracle8408 | Latest | Fixes an issue with the Oracle - Update Snap wherein the Snap is unable to perform operations when:
| |
| 4.19 | snaprsmrc528 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.18 Patch | oracle7786 | Latest | Fixes an issue using the NVARCHAR2 datatype in Oracle databases when the character set is not AL32UTF8. However, a known issue is that special characters display as | |
| 4.18 | snapsmrc523 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.17 Patch | db/oracle7459 | Latest | Fixed an issue with the Oracle Stored Procedure Snap wherein the Pipeline execution fails with an error when the input data type is CLOB. | |
| 4.17 | ALL7402 | Latest | Pushed automatic rebuild of the latest version of each Snap Pack to SnapLogic UAT and Elastic servers. | |
| 4.17 | snapsmrc515 | Latest |
| |
4.16 Patch | db/oracle6919 | Latest | Added a new property, Session parameters, in the Oracle Insert Snap to enable the use of National Language Support (NLS) parameters. | |
4.16 Patch | db/oracle6824 | Latest | Fixed an issue with the Lookup Snap passing data simultaneously to output and error views when some values contained spaces at the end. | |
| 4.16 | snapsmrc508 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.15 Patch | db/oracle6534 | Latest | Improved performance in Pipelines that contain child Pipelines. | |
| 4.15 Patch | db/oracle6417 | Latest | Fixed an issue with data types conversion. All fields with byte, short, int, or long data types will be converted to BigInteger after fetching. | |
| 4.15 Patch | db/oracle6284 | Latest | Replaced the existing Max idle time and Idle connection test period properties with Max life time and Idle Timeout properties respectively, in the Account configuration. The new properties fix the connection release issues that were occurring due to default/restricted DB Account settings. | |
| 4.15 | snapsmrc500 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.14 | snapsmrc490 | Stable | Upgraded with the latest SnapLogic Platform release. | |
4.13 Patch | db/oracle5192 | Latest |
| |
| 4.13 | snapsmrc486 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.12 Patch | oracle4862 | Latest | Fixed an issue in the Oracle Bulk Load Snap that fails to execute the SQLLDR (SQL Loader) command, while also enhancing the support for the TCPS protocol. | |
| 4.12 Patch | db/oracle4721 | Latest | Added a property, "SSL/TCPS" for Oracle Account. | |
| 4.12 Patch | MULTIPLE4744 | Latest | Enabled expression for Delete Condition in Oracle Delete Snap. | |
| 4.12 | snapsmrc480 | Stable | Upgraded with the latest SnapLogic Platform release. | |
4.11 Patch | db/oracle4369 | Latest | Enhanced the Oracle Bulk Load Snap to accept date-type values in the format "yyyy-mm-dd". | |
| 4.11 | snapsmrc465 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.10 Patch | oracle3633 | Latest | Fixed BULK LOAD so it adds the thread name to the name of the temporary directory. This allows multiple BULK LOAD Snaps within a single pipeline. | |
| 4.10 | snapsmrc414 | Stable | Added Auto commit property to the Select and Execute Snaps at the Snap level to support overriding of the Auto commit property at the Account level. | |
4.9.0 Patch | oracle3188 | Latest | Fixed the issue that "NaN" check was done to unexpected data types like varchar. | |
4.9.0 Patch | oracle3096 | Latest | Fixed a class casting issue for custom data types(BLOB, CLOB, NCLOB, etc) when custom Oracle JDBC driver is used. | |
4.9.0 Patch | oracle3071 | Latest | Fixed an issue regarding connection not closed after login failure; Expose autocommit for "Select into" statement in PostgreSQL Execute Snap and Redshift Execute Snap. | |
| 4.9 | snapsmrc405 | Stable | Upgraded with the latest SnapLogic Platform release. | |
4.8.0 Patch | oracle2905 |
| Latest | Fix for SQL*Loader interpreting white-space only data as null values. |
4.8.0 Patch | oracle2756 | Latest | Potential fix for JDBC deadlock issue. | |
4.8.0 Patch | oracle2711 | Latest | Fixed Oracle Snap Pack rendering dates that are one hour off from the date returned by database query for non-UTC Snaplexes. | |
| 4.8 | snapsmrc398 | Stable | Database accounts now invalidate connection pools if account properties are modified and login attempts fail. | |
4.7.0 Patch | oracle2190 | Latest | Fixed an issue with the Oracle Select Snap regarding Limit rows not supporting an empty string from a pipeline parameter. | |
| 4.7 | snapsmrc382 | Stable |
| |
| 4.6 | snapsmrc362 | Stable |
| |
| 4.5.1 | oracle1583 | Stable |
| |
| 4.4.1 | NA | Stable |
| |
| 4.4 | NA | Stable |
| |
| 4.3.2 | NA | Stable |
| |
| NA | NA | Stable |
| |
| NA | NA | Stable |
| |
| NA | NA | Stable |
|
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.