Problem Scenario
...
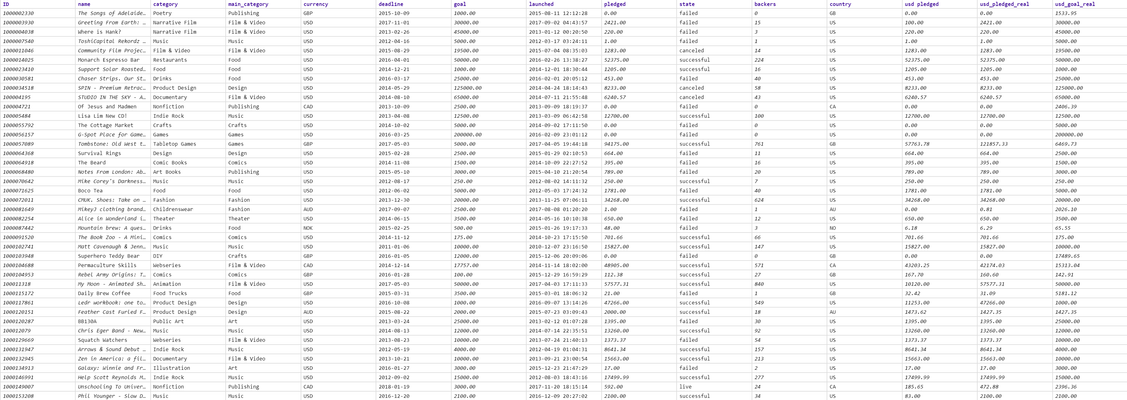
Out of curiosity, we want to try to use Machine Learning algorithms to predict whether the projects are going to succeed or fail. If we succeed in doing this, we should be able to figure out the best way to improve the success rate of future projects. We chose Kickstarter because of the large number of projects spanning over years. There are a lot of open datasets you can find on the internet and we got one from here. This dataset contains over 300,000 projects; however, it only contains general information about projects including title, category, currency, country, goal, pledge, important dates, and state. There is a lot more useful information you can add to improve the accuracy such as description, keywords, activities, competitors, patents, team, and company reputation. For demonstration purpose, we only considered 20,000 projects. The screenshot below shows the preview of this dataset.

Objectives
- Profiling: Use Profile Snap from ML Analytics Snap Pack to get statistics of this dataset.
- Data Preparation: Perform data preparation on this dataset using Snaps in ML Data Preparation Snap Pack.
- Cross Validation: Use Cross Validator (Classification) Snap from ML Core Snap Pack to perform 10-fold cross validation on various Machine Learning algorithms. The result will let us know the accuracy of each algorithm in the success rate prediction.
We are going to build 4 pipelines: Profiling, Data Preparation, and 2 pipelines for Cross Validation with various algorithms. Each of these pipelines is described in the Pipelines section below.
Pipelines
Profiling
In order to get useful statistics, we need to transform the data a little bit.
...