In this article
| Table of Contents | ||||
|---|---|---|---|---|
|
| Multiexcerpt include macro | ||||||||
|---|---|---|---|---|---|---|---|---|
|
Overview
You can use this Snap to load files/data from Amazon S3 buckets or Azure Cloud Storage containers to a Snowflake, Azure Synapse database, or a Databricks Lakehouse Platform (DLP) instance. You can also use this Snap to load or transfer data from:
Amazon S3 buckets to the Amazon Redshift database.
Amazon Redshift or Google Cloud Storage to BigQuery tables.
A DBFS folder to a DLP table.
Refer to ELT Source-Target-Hosting Support Matrix for complete information.
| Note |
|---|
If you want to use the COPY INTO command in ELT Execute Snap for loading data into the target database, you need to pass (expose) these account credentials inside the SQL statement. You can use the ELT Load Snap to prevent this security issue. |
Snap Type
The ELT Load Snap is a Write-type Snap that writes/loads data from a source file/table to a table in the destination/target CDW.
Prerequisites
Valid accounts and access permissions to connect to one source and one target in the following source and target locations (Refer to the ELT Source-Target-Hosting Support Matrix for the supported source-target combinations):
Source: Amazon S3, Azure Cloud Storage, DBFS location, or Google Cloud Storage
Target: Snowflake, Redshift, Azure Synapse, DLP, or BigQuery
Limitations
| Cfm tabs page | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||
|
| Cfm tabs page | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
|
| Cfm tabs page | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
|
Known Issues
| Cfm tabs page | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||
|
| Cfm tabs page | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||
|
| Cfm tabs page | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
However, the ELT Load Snap outputs the correct date and time values when executing the pipeline.
|
| Cfm tabs page | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
However, the ELT Load Snap outputs the correct date and time values when executing the pipeline.
|
| Cfm tabs page | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
|
| Cfm tabs page | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
|
Snap Views
Type | Format | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input | Document |
|
| A document containing the SQL query that you can use from the upstream ELT Snaps. |
Output | Document |
|
| A document containing the status of the load operation and an SQL query that you can use in any downstream ELT Snaps. |
Error | Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter when running the by choosing one of the following options from the When errors occur list under the Views tab:
Learn more about Error handling in pipelines. | |||
Snap Settings
| Info |
|---|
|
| Info |
|---|
SQL Functions and Expressions for ELT You can use the SQL Expressions and Functions supported for ELT to define your Snap or Account settings with the Expression symbol ( |
Field Name | Field Type | Field Dependency | Description | |||||
|---|---|---|---|---|---|---|---|---|
Label* Default Value: ELT Load Example: S3 Load | String | None. | Specify a name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||
Get preview data Default Value: Not selected Example: Selected | Checkbox | None. | Select this checkbox to include a preview of the query's output. The Snap performs limited execution and generates a data preview during pipeline validation.
The number of records displayed in the preview (on validation) is the smaller of the following:
| |||||
Database Name Default Value: N/A Example: TEST_DB | String | None. | Enter the name of the database in which the target table exists. Leave this blank if you want to use the database name specified in the Default Database Name field in the Account settings. | |||||
Schema Name (Not applicable to Databricks Lakehouse Platform)* Default Value: N/A Example: SALES | String | Not applicable to DLP. | Enter the name of the database schema. In case the schema name is not defined, then the suggestions retrieved for the schema name contain all schema names in the specified database.
| |||||
Target Table Name* Default Value: N/A Example: SALES_ORDERS | String | None. | Enter the name of the table or view in which you want to perform the load operation.
| |||||
Target Table Hash Distribution Column (Azure Synapse Only) Default Value: N/A Example: Var_table | String/Expression | Applicable to Azure Synapse only. | Specify the hash distribution column name for the target table in Azure Synapse, if you choose the Load Action as Drop and Create table.
| |||||
Load Action Default Value: Append rows to existing table Example: Alter table | Dropdown list | None. | Select the load action to perform on the target table. Available options are:
| |||||
Table Columns | This field set enables you to configure the schema of the target table. You can use this field set to add/drop columns in the target table if you select the Drop and Create table or Alter table options in the Load Action field. This field set consists of the following fields:
| |||||||
Column Default Value: N/A Example: ID, FNAME | String | Load Action is Drop and Create table or Alter table. | Enter the name of the column that you want to load in the target table. You can also specify the columns to drop if you select the Alter table option in the Load Action field. | |||||
Data Type Default Value: N/A Example: INT, VARCHAR | String | Load Action is Drop and Create table or Alter table. | Enter the data type of the values in the specified column. Use the VARIANT data type for target table columns that correspond to a map (JSON OBJECT) or array (JSON LIST) in your nested Parquet files. | |||||
Modifier Default Value: Add Example: Drop | String | Load Action is Alter table. | Select whether you want to add/drop the specified column. Available options are:
| |||||
Table Option List | This field set enables you to define the table options for creating the target table before performing the load operation. These options vary based on your target CDW. Refer to the Table options for Load action for the complete list of permitted table options. You must specify each table option in a separate row.
| |||||||
Table Option Default Value: N/A Example: OPTIONS(custID=03761) | Expression/Suggestion | Choose a table option that you want to use from the suggested options. Specify the required values for the selected option. | ||||||
Redshift Schema Name (Only when BigQuery with Source Location as Redshift) Default Value: N/A Example: PUBLIC, DEF_SCHEMA | String/Expression | Database Type is BigQuery andSource Location is Amazon Redshift in the Snap Account. | Specify the schema name of the source table in Redshift. | |||||
Redshift Table Name (Only when BigQuery with Source Location as Redshift) Default Value: N/A Example: DataLoad_Source01 | String/Expression | Database Type is BigQuery andSource Location is Amazon Redshift in the Snap Account. | Specify the name of the Redshift source table (from the schema selected above). | |||||
Cloud Storage Path Default Value: N/A Example: s3://bigbucket/app_data | String/Expression | Specify the fully qualified path to the folder in the Cloud storage in this field, if you want to override the default path defined in the Snap's Account settings. For example:
| ||||||
File List | This field set enables you to specify the staged files to load. You must specify each file in a separate row. Click + to add a new row.
This field set consists of the following field:
| |||||||
File Default Value: N/A Example: TestData.csv | String | None. | Enter the name of the staged file to load. | |||||
File Name Pattern Default Value: N/A Example:
| String | None. | Enter the pattern to use to match the file name and/or absolute path. You can specify this as a regular expression pattern string, enclosed into use the key-based search mechanism.
Refer to Loading Using Pattern Matching for details on Snowflake regular expressions, Examples of COPY INTO (Delta Lake on Databricks) for DLP, or Regular Expressions and the Java Programming Language for using regular expressions with Redshift, Azure Synapse, or BigQuery in this field. | |||||
File Format Type Default Value: None Example: AVRO | String/Expression/Suggestion | None. | Select the format for the file. The options vary based on the database type in your account settings. The supported file formats are:
| |||||
File Format Option List | This field set enables you to define the file format options for the load operation. You must specify each file format option in a separate row.
Refer to Snowflake Data Loading Commands, Redshift Data Format Parameters, COPY INTO (Transact-SQL) for Azure Synapse Analytics, COPY INTO Format options for DLP, or the BigQuery’s Batch load data guide specific to your source file format type for the list of options that you can use based on the target database.
| |||||||
Format Option Default Value: N/A Example: SKIP_HEADER = 1 | String/Expression/Suggestion | Based on the combination of Database Type and File Format Type. | Choose a file format option that you want to use during the load operation from the suggested values. Specify the required value for the selected option.
| |||||
Encryption Type Default Value: None Example: Server-Side Encryption | String/Expression/Suggestion | None. | Select the encryption type that you want to use for the loaded data and/or files. Available options are:
| |||||
KMS Key Default Value: N/A Example: WC2YY-2BFMV-KHKB3-FDDGQ-8NRQY | String/Expression | Encryption Type is Server-Side KMS Encryption. | Enter the KMS key to use to encrypt the files.
| |||||
Copy Option List | This field set enables you to define the COPY options for the load operation. You must specify each COPY option in a separate row. Click + to add a new row. This field set comprises the following field:
See COPY Options for Snowflake, COPY Parameter Reference for Redshift, COPY INTO (Transact-SQL) for Azure Synapse Analytics, or COPY_OPTIONS under COPY INTO Parameters for DLP. | |||||||
Copy Option Default Value: N/A Example: ON_ERROR = ABORT_STATEMENT | String/Expression/Suggestion | None. | Choose a COPY option from the suggested values to use if an error occurs during the load operation. Specify the required value for the selected option. | |||||
Validation Mode Default Value: None Example: RETURN_n_ROWS | String/Expression/Suggestion | None. | Select an output preview type for the data validation performed as part of the pipeline validation. The options vary based on the database type (Snowflake/Redshift) in your account settings. Available options for Snowflake are:
Available options for Redshift are:
For more details, refer to Validating Staged Files for Snowflake and Validating Input Data for Redshift.
| |||||
Rows To Return Default Value: N/A Example: 20 | String (Number) | Validation Mode is RETURN_n_ROWS. | Enter the number of records to retrieve from the target table to validate whether the load operation was successful. | |||||
Enable source column position (Snowflake and Azure Synapse Only) Default Value: Not selected Example: Selected | Checkbox | Database Type is Snowflake or Azure Synapse. | Select this checkbox to specify the source table column’s position in the Target to Source Column Map instead of its name.
| |||||
Target to Source Column Map | This field set enables you to define the mapping between the columns in the target table and the corresponding columns in the source file. You must define each mapping in a separate row. The available options are:
| |||||||
Target Table Column Name Default Value: N/A | String/Expression/Suggestion | None. | Choose a column from the list of target table columns displayed. Ensure that you have defined the Schema Name or the Target Table Name to view the list of columns in this field's suggestions. | |||||
Source File Column Name Default Value: N/A | String/Expression/Suggestion | None. | Choose a column from the list of source file columns displayed. Ensure that you have defined the Schema Name (or source file path) to view the list of columns in this field's suggestions. | |||||
Source Column Position (Valid Only For Snowflake and Azure Synapse) Default Value: N/A | Integer/Expression | Database Type is Snowflake or Azure Synapse. | Specify the column’s position in the source file. | |||||
Table options for Load action
| Cfm tabs page | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||
Refer to CREATE TABLE - Snowflake Documentation for details about these options. |
| Cfm tabs page | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
Refer to CREATE TABLE - Amazon Redshift for details about these options. |
| Cfm tabs page | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
Refer to CREATE TABLE (Azure Synapse Analytics) - SQL Server for details about these options. |
| Cfm tabs page | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
Refer to CREATE TABLE [USING] - Azure Databricks - Databricks SQL for details about these options. |
| Cfm tabs page | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
Refer to Data definition language (DDL) statements in GoogleSQL | BigQuery | Google Cloud for details about these options. |
Using file format options with ELT Load
Here are a few common file format options that can be used for the corresponding CDW when loading data from CSV files in a storage location to a table in that CDW.
Target CDW | Exclude header row from the input data stream | Specify row delimiters |
|---|---|---|
Azure Synapse | FIRSTROW = 2 | ROWTERMINATOR = ' ROWTERMINATOR = ' |
DLP | 'header' = 'true' | lineSep=None ( |
Google BigQuery | skip_leading_rows = 1 | N/A (allow_quoted_newlines = true if there are quoted data sections in a CSV file, that contain newline characters.) |
Redshift | IGNOREHEADER 1 | N/A |
Snowflake | SKIP_HEADER = 1 | RECORD_DELIMITER = '<character>' | NONE |
Load data from Parquet files
Data in your Parquet files can exist as any combination of the following structures: Flat data, nested lists, and nested maps.
Flat Parquet fields contain data in a simple two-dimensional spreadsheet-like format (Level 0). Such fields can be read and loaded using the standard mapping and loading methods.
Parquet file fields in nested lists or maps contain structured and hierarchical data where values for each field can be:
A series of repeated fields (Level 1) or
A series of values (Level 1)
Another set of key-value pairs (Level 2), or
A set of keys with each or some of them containing a nested set of key-value pairs (Level 3), and so on.
Lists vs. Maps in nested Parquet files
The lists are very similar to the JSON arrays in their notation and are characterized by square brackets [ and ] in the Parquet files.
The maps are very similar to the JSON objects in their notation and are characterized by curly braces { and } in the Parquet files.
However, we recommend that you reference the actual Parquet file to create your source-to-target field mappings and not its JSON-converted version.
Different Parquet file structures
The table below depicts the possible schema variations within a Parquet file with examples of source table data. It also indicates how to reference the fields (keys in the source Parquet files) and map them with the corresponding target table columns to load your data.
Parquet Files | Canonical format | Non-canonical format | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Flat data | Nested List | Nested Map | Nested Map | |||||||||||||||||||||
Sample schema (column definitions) |
|
|
|
| ||||||||||||||||||||
Example Data |
|
|
|
| ||||||||||||||||||||
Referencing columns from source table schema in the Snap |
|
|
|
| ||||||||||||||||||||
|
|
| ||||||||||||||||||||||
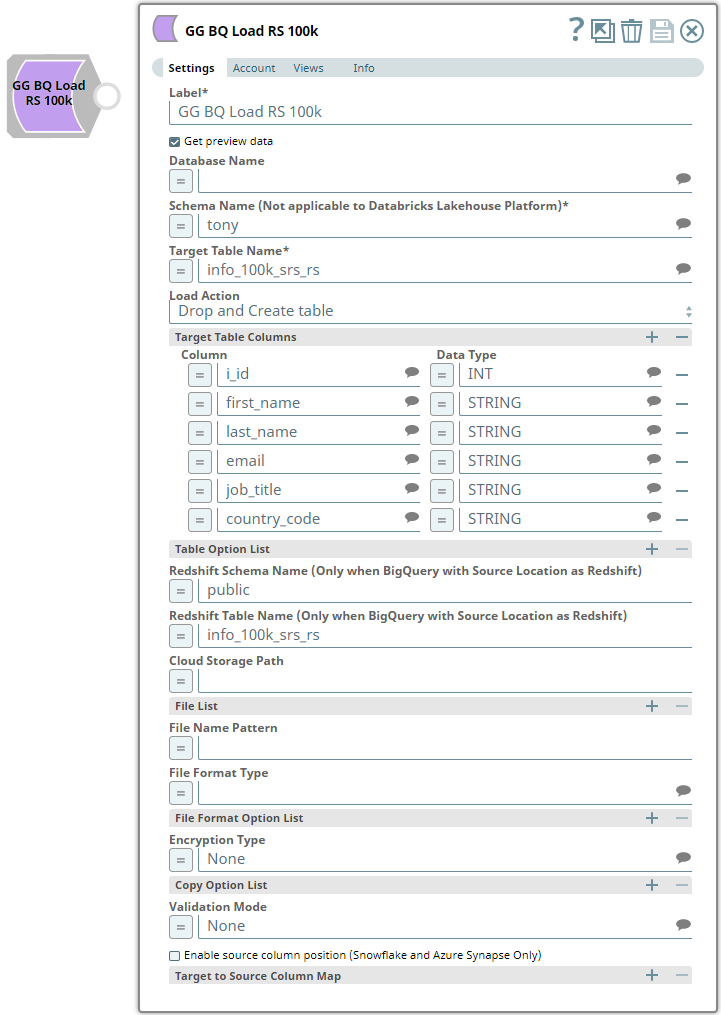
Consider the following ELT Load Snap configuration:
 | Besides the standard and mandatory settings in this Snap, the following settings are unique and pivotal to reading and loading data from Parquet files:
You must decipher the structure (canonical or non-canonical) and schema of your Parquet files (mentioned above) and fill the details - Column names, data types, and source-to-target column mapping. Learn more at <Load Load data from a canonical format Parquet file (link to the following section under Examples)> in the Examples section. |
Snap Behavior During Pipeline Validation
This Snap's behavior during pipeline validation varies for each Load Action selected.
Load Action | Target Table exists? | Validation Result | Action on Target Table# |
|---|---|---|---|
Append rows to existing table | No | Success | Creates an empty target table based on the schema information available in the Snap settings. |
Yes | Success | No updates made. | |
Overwrite existing table | No | Success | Creates an empty target table based on the schema information available in the Snap settings. |
Yes | Success | No updates made. | |
Drop and Create table | No | Success | Creates an empty target table based on the schema information available in the Snap settings. |
Yes | Success | No updates made. | |
Alter table | No | Success | Creates an empty target table based on the schema information available in the Snap settings. |
Yes | Success | No updates made. | |
# Bulk load operations are not done during pipeline validation. | |||
| Cfm tabs page | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||
The data is not loaded into the Snowflake table. It is just validated using the RETURN_n_ROWS validation mode. The number of records in the output is determined by the preview count set in the pipeline settings. The Snap creates the target table (if not existing already) in the database when you select Load Action as Drop and Create the table. For all other load actions, the Snap verifies if the specified target table exists in the database. |
| Cfm tabs page | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
The data is not loaded into the Redshift table. The files in S3 are just validated using the NOLOAD validation mode to verify data integrity of the files. The target table is also affected based on your selection in the Load Action field. The Snap creates the target table (if not existing already) in the database when you select Load Action as Drop and Create table. For all other load actions, the Snap verifies if the specified target table exists in the database. |
| Cfm tabs page | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
The data is not loaded into the Azure Synapse table. The Snap creates the target table (if not existing already) in the database when you select Load Action as Drop and Create table. For all other load actions, the Snap verifies if the specified target table exists in the database. |
| Cfm tabs page | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
The data is not loaded into the DLP table. The Snap creates the target table (if not existing already) in the database when you select Load Action as Drop and Create table. For all other load actions, the Snap verifies if the specified target table exists in the database. |
| Cfm tabs page | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
The data is not loaded into the BigQuery table. The Snap creates the target table (if not existing already) in the database when you select Load Action as Drop and Create table. For all other load actions, the Snap verifies if the specified target table exists in the database. |
Troubleshooting
| Cfm tabs page | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||
|
| Cfm tabs page | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||
|
| Cfm tabs page | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||
|
| Cfm tabs page | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||
|
| Cfm tabs page | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||
|
| Cfm tabs page | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||
|
Examples
Loading Files from S3 Bucket to Snowflake
We need to perform Snowflake ELT transformations upon a file present in an S3 bucket. Therefore, we must first load the file into the Snowflake database from the source location. This pipeline shows how we can use the ELT Load Snap to accomplish this task.
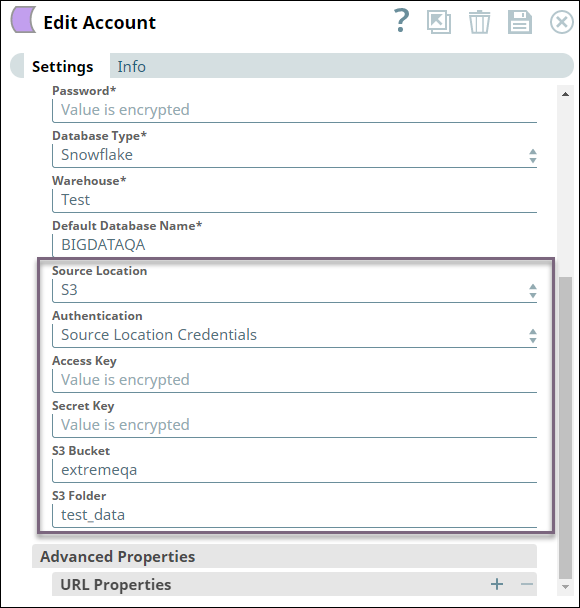
Before we can load the file, we must configure the ELT account to read from the source S3 bucket by configuring the Source Location, Authentication, Access Key, Secret Key, S3 Bucket, and S3 Folder fields. The fields vary based on the source location and authentication. See Configuring ELT Database Accounts for details.
We configure the ELT Load Snap as shown below:
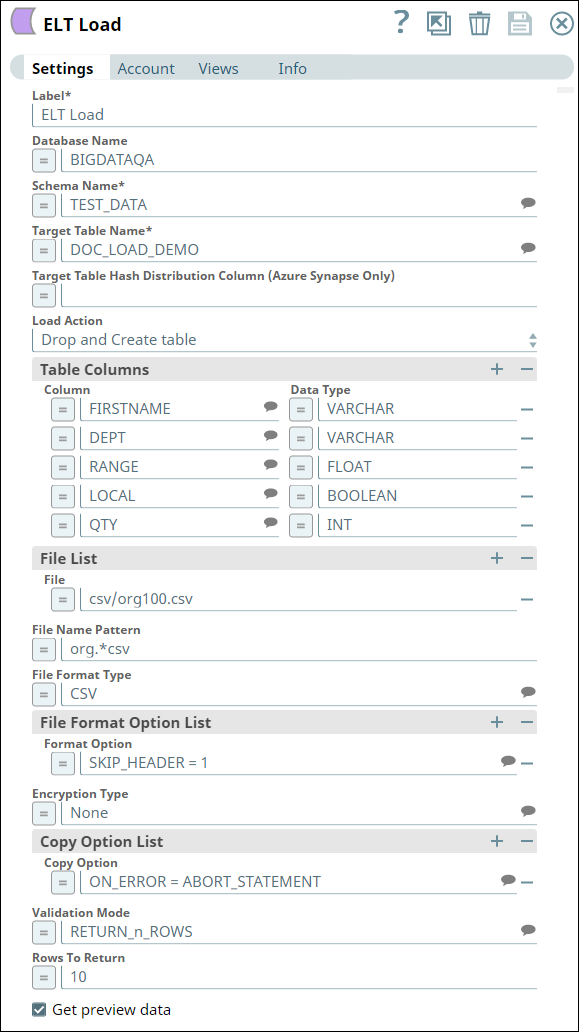
Let us understand this Snap's configuration:
The Database Name, Schema Name, and Target Table Name specify the target database, schema, and table into which we want to write the file's data.
Table Action indicates that if a table with the same name exists, we configure the Snap to drop the table and create a new one in its place.
Since this is a new table, the Table Columns field set specifies the table's schema.
The File List field set specifies the source file's path in the S3 bucket and the file's format.
The Format Option field set specifies that the Snap must ignore the file's header. Otherwise, the header is also loaded into the target table.
The Copy Option field set specifies that the Snap must abort the loading operation if it encounters an error.
The Validation Mode and Rows to Return fields specify that 10 rows from the target table be retrieved upon successful completion.
To validate a successful execution, the ELT Load Snap executes a SELECT * command on the target table and returns 10 rows:
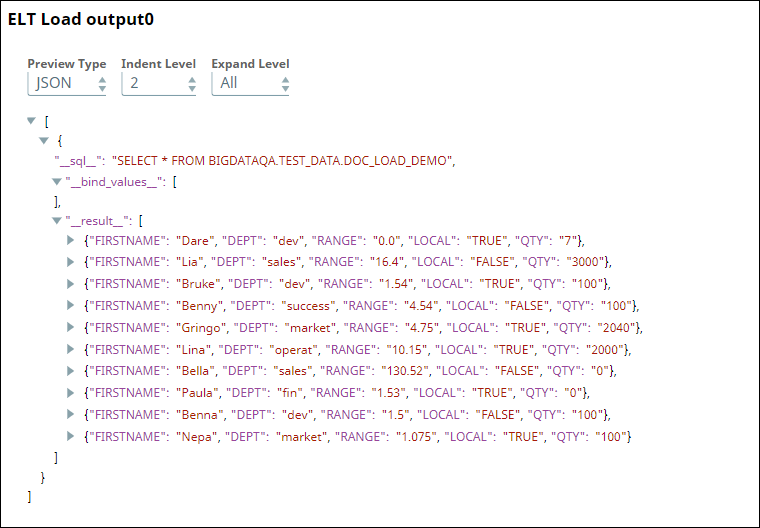
We can either create a separate pipeline to perform ELT operations on the table or add appropriate Snaps downstream of the ELT Load Snap in the same pipeline.
Uploading data from a CSV File in Azure Data Lake Gen2 Storage to Azure Synapse
The following one-Snap (ELT Load) pipeline connects to an Azure Data Lake Gen2 Storage using an ADLS Gen2 Basic Auth account to upload a CSV file from the storage to an Azure Synapse database. This CSV file is created on MacOS with the default line endings.
Account Configuration | Snap Configuration |
|---|---|
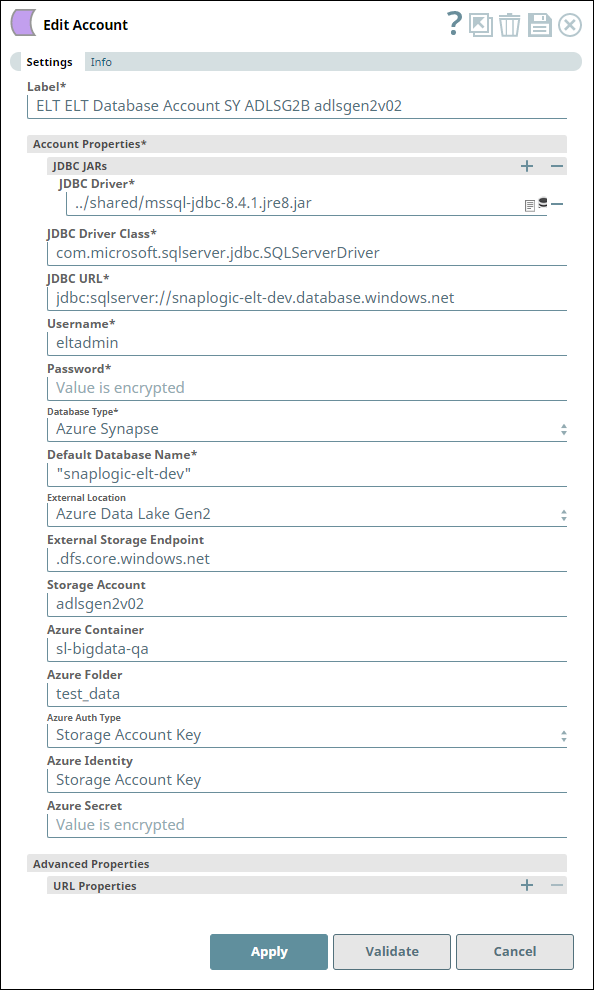 | 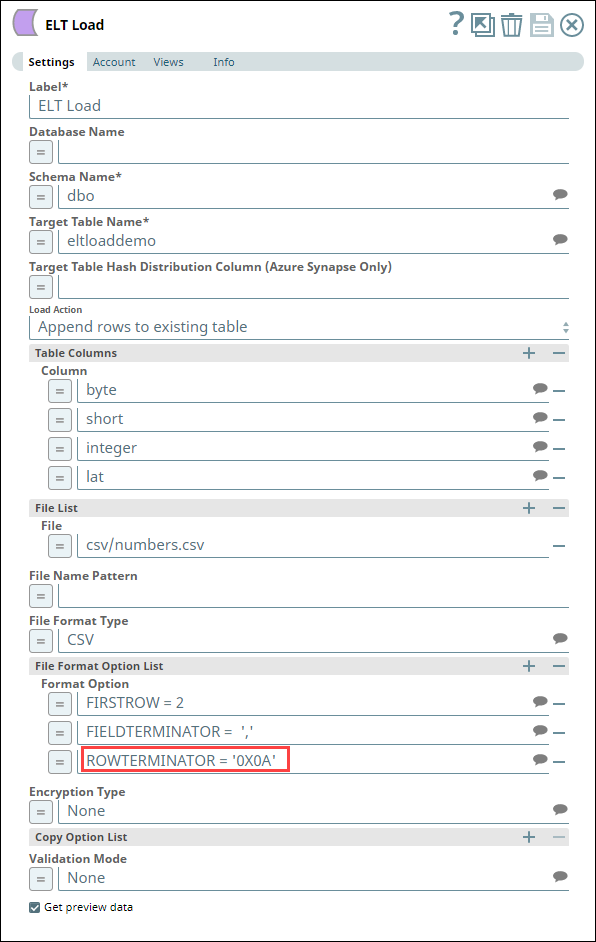 |
For the pipeline to work as expected when the CSV file created on MacOS with the default (MacOS) line endings, define the value for the file format option ROWTERMINATOR as '0X0A' instead of the usual '\n'. With '\n' as ROWTERMINATOR, the pipeline runs successfully, but does not insert the data from the CSV file into the newly-created table in Azure Synapse.
Snap Output with ROWTERMINATOR = '\n' | Snap Output with ROWTERMINATOR = '0X0A' |
|---|---|
 | 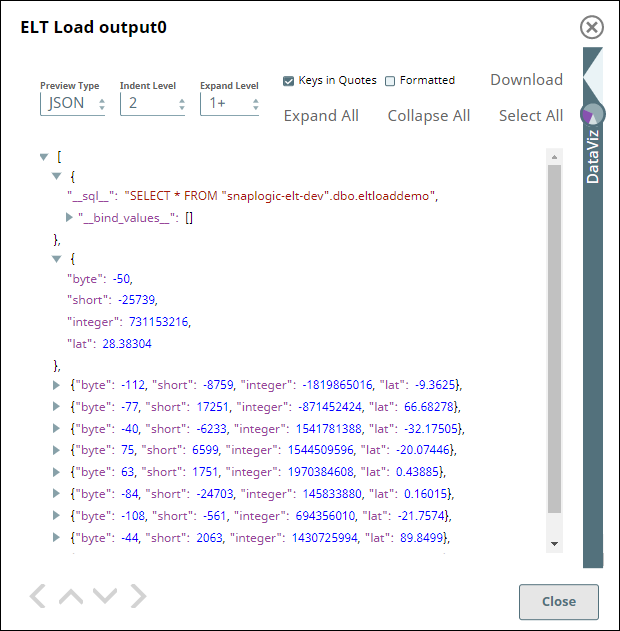 |
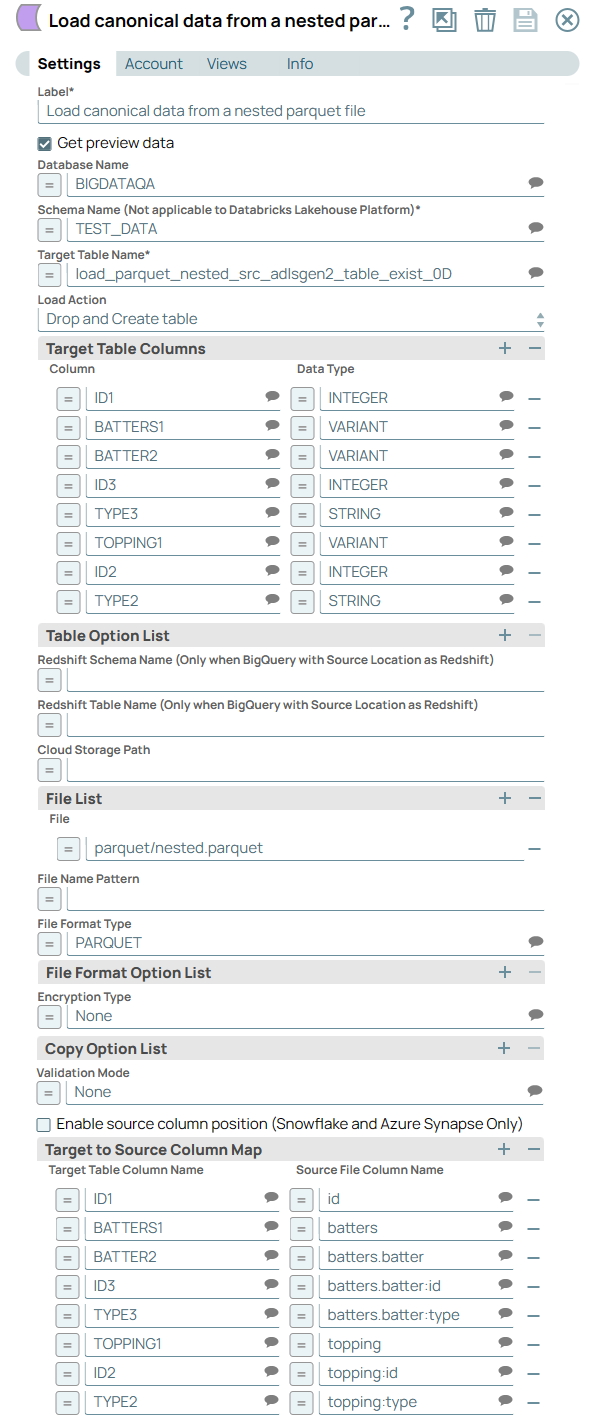
Load data from a canonical format Parquet file
Suppose that your Parquet file contains a few rows of data split into three columns (id, batters, and topping) as shown below:

You can configure the ELT Load Snap in the following ways to load this data into a two-dimensional table on your Snowflake instance.
Create a target table or update an existing table with the same three columns - id, batters, and topping. In this case, the data type of the batters and topping columns must be VARIANT. Or
Create a (flat) target table with the following columns and data types, and load values into the respective columns using the Parquet file data identifiers.
| Cfm tabs page | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||
|
| Cfm tabs page | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||
|
Load data from a non-canonical format Parquet file
Suppose that your Parquet file contains a few rows of data split into three columns (id, batters, and topping) as shown below:

If you want to load only a part of this data set (a subset of columns) to a target table in Snowflake, here is how you define your Source File Column Names in the Target to Source Column Map.
| Cfm tabs page | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||
|
| Cfm tabs page | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||
|
A few other scenarios
Use the MATCH_BY_COLUMN_NAME copy option without mapping individual columns | Use VARIANT columns without mapping individual columns | ||||
|---|---|---|---|---|---|
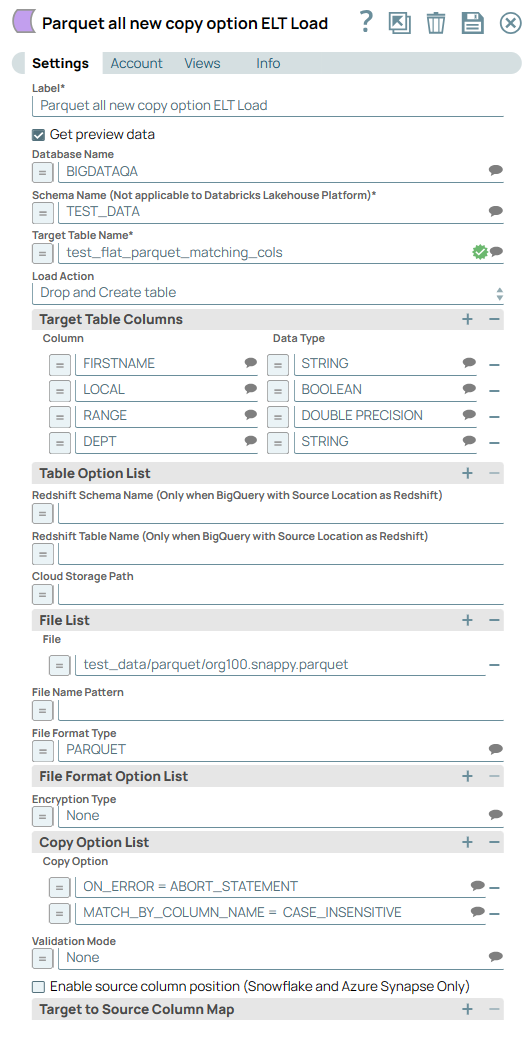
|
|
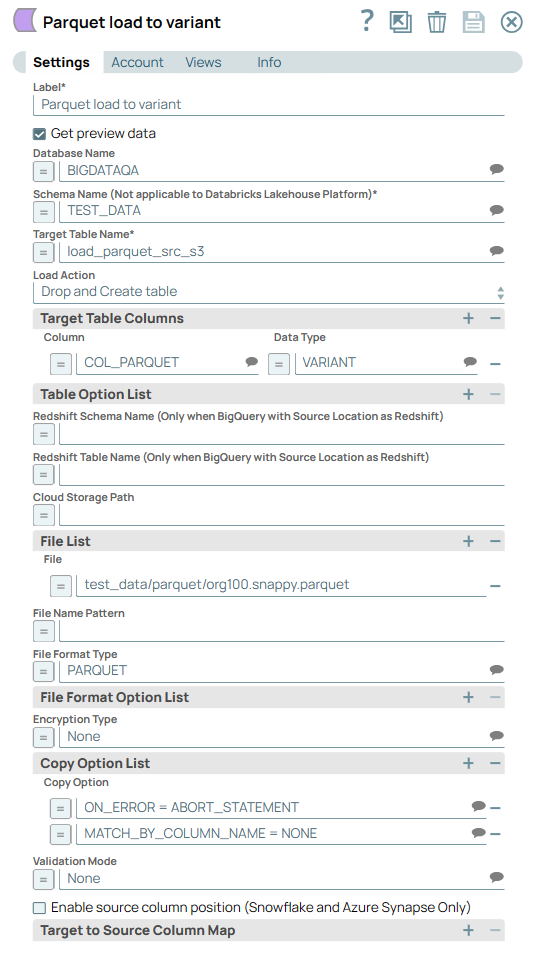
Downloads
| Note |
|---|
Important Steps to Successfully Reuse Pipelines
|
| Attachments | ||
|---|---|---|
|
Snap Pack History
Refer to the Snap Pack History table in ELT Snap Pack.