On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Write | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap executes a SQL Insert statement using the document's keys as the columns to insert to and the document's values as the values to insert into the columns. | |||||||||
| Prerequisites: | None. | |||||||||
| Support and limitations: |
| |||||||||
| Account: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See MySQL Account for information on setting up this type of account. | |||||||||
| Views: |
| |||||||||
Settings | ||||||||||
Label* | Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||
Schema name | Specify the database schema name. In case it is not defined, then the suggestion for the Table Name will retrieve all tables names of all schemas. The property is suggestable and will retrieve available database schemas during suggest values.
| |||||||||
| Table name* | Specify the name of table to execute insert on.
| |||||||||
Create table if not present |
Default value: Not selected | |||||||||
| Preserve case sensitivity |
| |||||||||
Use MySQL INSERT IGNORE option | Select an option to instruct the Snap to ignore the SQL errors encountered during execution.
| |||||||||
Snap Execution | Select one of the three modes in which the Snap executes. Available options are:
Default Value: Execute only | |||||||||
| Note |
|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|
Example
In this Pipeline, we inserted the records to an existing table, via the JSON Generator Snap and mapped them to the MySQL table 'Hues' using the Mapper and the MySQL Insert Snaps respectively. The failed records are routed to the error view.
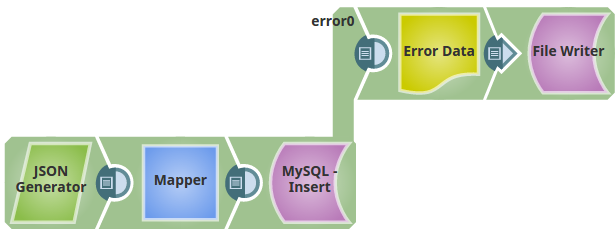
The JSON Generator Snap passes the values to the Mapper Snap.
.png?version=1&modificationDate=1489902451882&cacheVersion=1&api=v2)
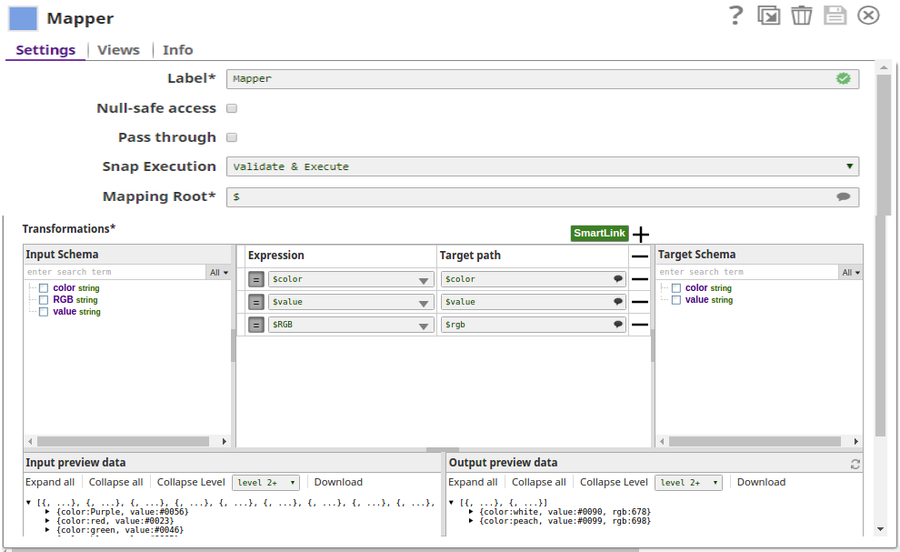
The Mapper Snap maps the records to the respective columns on the table.
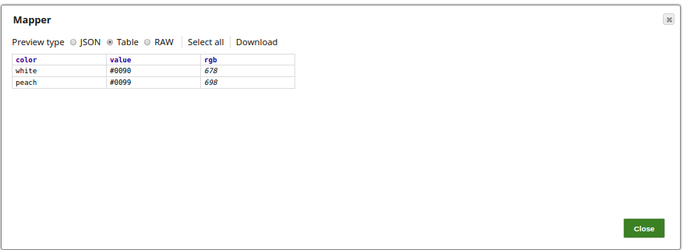
The output preview of the Mapper Snap that displays the added records.
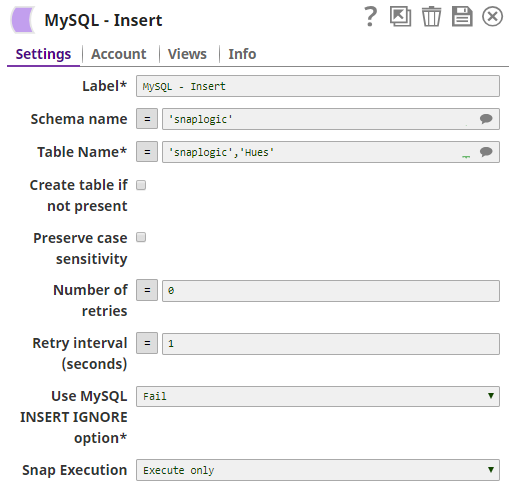
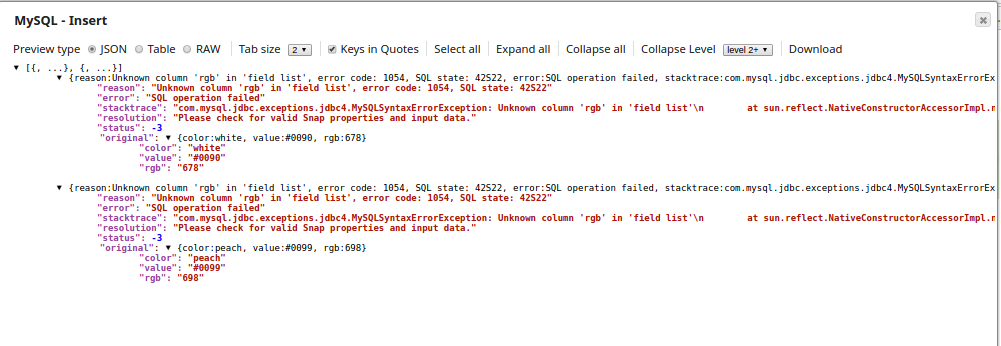
The MYSQL Insert Snap inserts the records into the table 'Hues' on the 'Snaplogic' Schema.
The failed records are routed to the error view, which displays the reason that the column 'rgb' is unknown in the field list (meaning the column rgb is absent in the existing table and hence the two records that has the RGB values are routed to the error view).
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|