On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap Type: | Read | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap provides functionality to lookup records in the target Redshift table and return a selected set of fields for every matched record. The Snap executes one request per multiple input documents to avoid making a request for every input record. JSON Path can be used in the Snap properties and will have values from an incoming document substituted into the properties. However, documents missing values for a given JSON path will be written to the Snap's error view. After a query is executed, the query's results are merged into the incoming document. Queries produced by the Snap have the format:
The Snap ignores any duplicated lookup condition in the input document stream since it maintains a cache for lookup conditions internally. ETL Transformations & Data FlowThe Snap extracts records from a Redshift table based on the condition configured using input document stream/parameters. Input & Output
| |||||||||||||
| Prerequisites: | [None] | |||||||||||||
| Limitations and Known Issues: | Works in Ultra Task Pipelines.
| |||||||||||||
| Account: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Redshift Account for information on setting up this type of account. | |||||||||||||
| Views: |
| |||||||||||||
Settings | ||||||||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||||||
Schema name | The database schema name. Selecting a schema filters the Table name list to show only those tables within the selected schema. | |||||||||||||
Table name | Required. Enter or select the name of the table to execute the lookup query on Example: people Default value: [None] | |||||||||||||
Output fields | Required. Enter or select output filed names for SQL SELECT statement. If this property is empty, the Snap selects all fields by executing the statement "SELECT * FROM ...". Example: email, address, first, last Default value: [None] | |||||||||||||
Lookup conditions | Required. The lookup conditions are created by using the lookup column name and the lookup column value. Each row will build a condition, such aslookupColumn1 = $inputField. Each additional row will be concatenated using a logical AND. All rows together build the lookup condition being used to lookup records in the lookup table. Default value: Not selected | |||||||||||||
Value | Required. Enter or select the JSON path of the lookup column value. The value will be provided by the input data field.JSON path of the lookup column value. The value will be provided by the input data field. Example: $email, $first, $last Default value: [None] | |||||||||||||
Lookup column name | Required. Enter or select lookup column name. Example: email, first, last, etc. Default value: [None] | |||||||||||||
Pass-through on no lookup match | When there is no lookup matching an input document, the input document will pass through to the output view if this property is checked. Otherwise, it will be written to the error view as an error condition. Default value: False | |||||||||||||
| Number of Retries | Specifies the maximum number of attempts to be made to receive a response. The request is terminated if the attempts do not result in a response. Example: 3 Default value: 0 | |||||||||||||
| Retry Interval (seconds) | Specify the time interval between two successive retry requests. A retry happens only when the previous attempt resulted in an exception. Example: 10 Default value: 1 | |||||||||||||
|
| |||||||||||||
Troubleshooting
| Error | Reason | Resolution |
|---|---|---|
| This issue occurs due to incompatibilities with the recent upgrade in the Postgres JDBC drivers. | Download the latest 4.1 Amazon Redshift driver here and use this driver in your Redshift Account configuration and retry running the Pipeline. |
Examples
Basic Use Cases
The following example shows looking up names of people based upon the billing city. The city name is passed using the JSON Generator Snap and the Lookup Snap searches and retrieves the records based on the Lookup conditions where the billing city matches to the value $city as passed via the upstream.
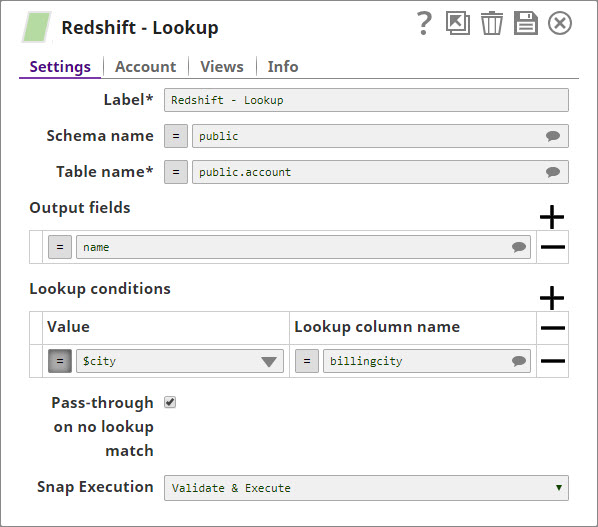
In the below pipeline, the Redshift Execute Snap reads the records from a table and the Lookup Snap retrieves the specified records as configured on the Lookup conditions.
The Execute Snap reads the records from from a table public.lookup_tbl and the respective output preview as below:
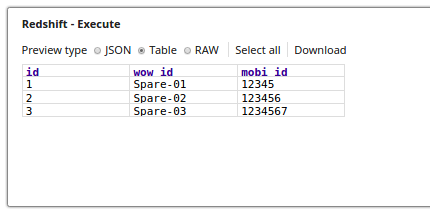
The Lookup Snap retrieves the records from the table lookup_tbl and the respective output preview is as displayed below:
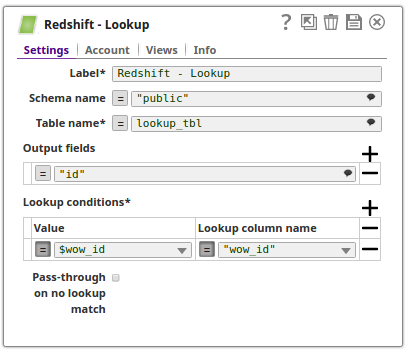
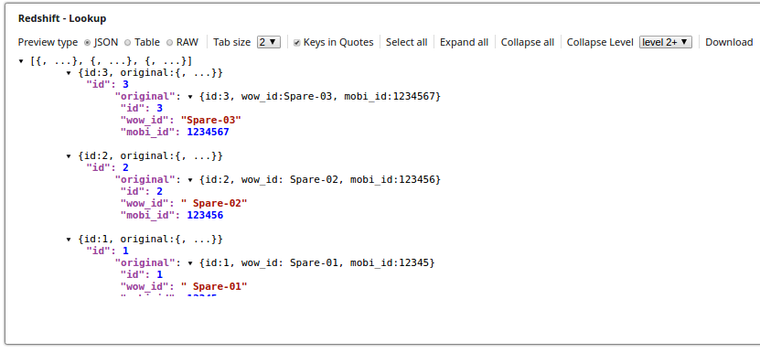
Typical Snap Configurations
Key configuration of the Snap lies in how SQL statements are passed to perform lookup of the records. The statements can be passed:
Without Expressions
The values are passed directly into the Snap.
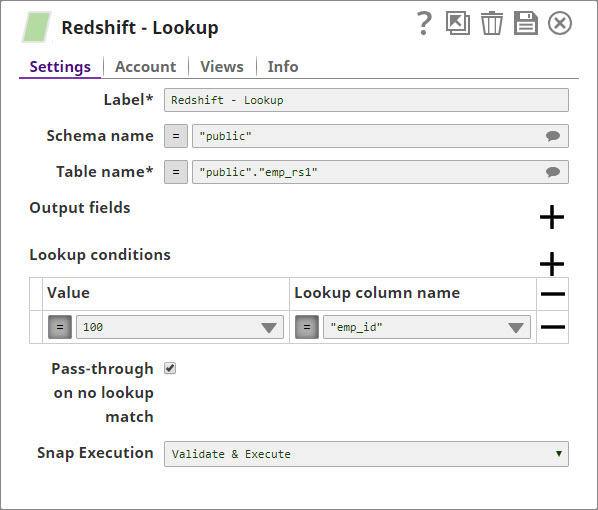
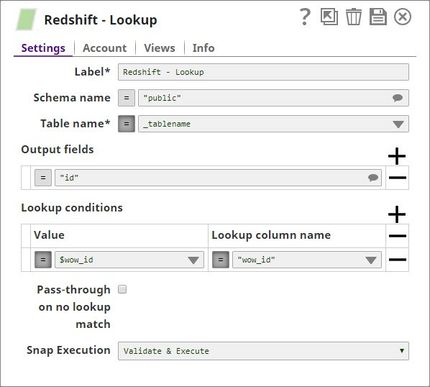
With Expressions
Using Pipeline parameters: The Table name is passed as a pipeline parameter.
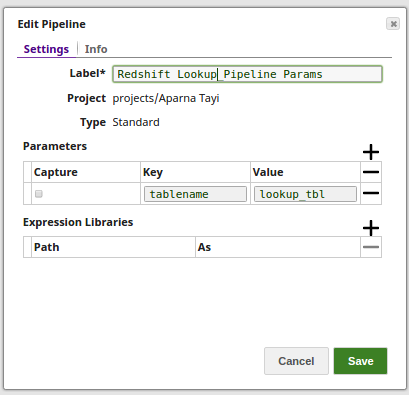
Advanced Use Case
The following describes a pipeline that shows how typically in an enterprise environment, a lookup functionality is used. Pipeline download link is in the Downloads section below.
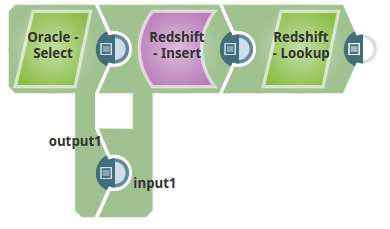
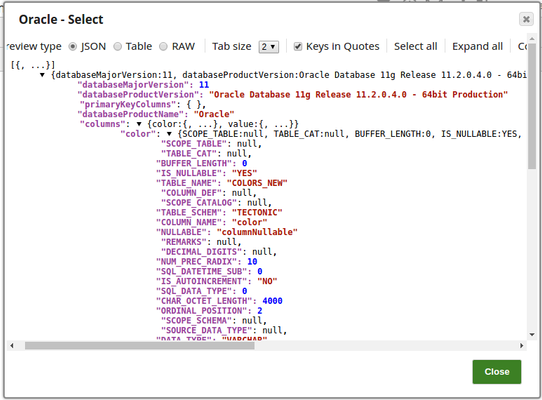
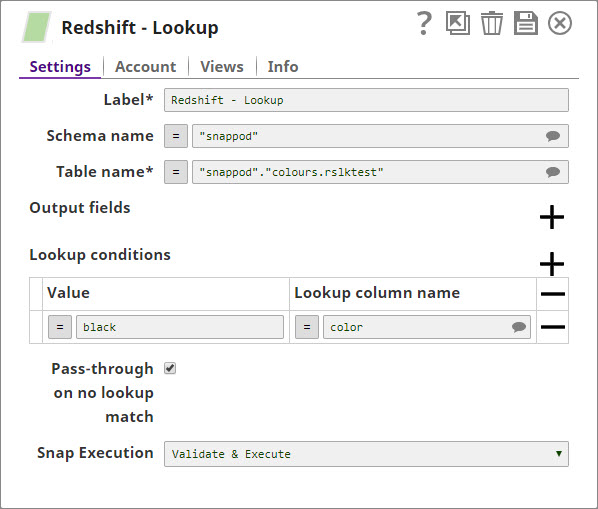
In this pipeline, a table "COLORS_NEW" belonging to the "TECTONIC" schema is selected from the Oracle DB, the values and data structure are passed to the Redshift Insert Snap where it is inserted into another table "colours_rslktest" in the "snappod" schema of the Redshift DB. The Redshift Insert Snap is configured to create a new table if the specified table does not exist and insert the data from the Oracle Select Snap into it. The Redshift Lookup Snap is then used to lookup all the records in this table that match the specified Lookup conditions. Output previews and configurations of each of the Snaps used in this pipeline are shown below.
Configuration and the output preview of the Oracle Select Snap respectively:
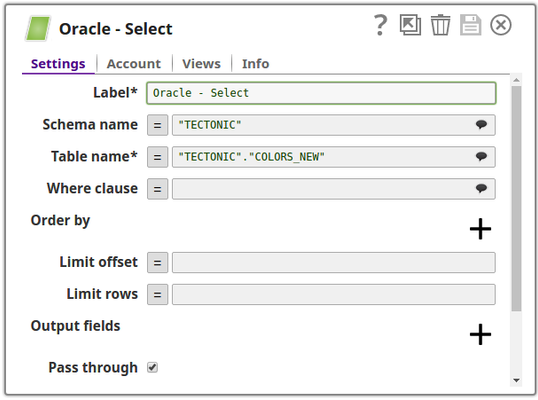
Note that there are two output views in the Oracle Select Snap, the first output view passes the table's data whereas the second output view (output1) passes the data structure.
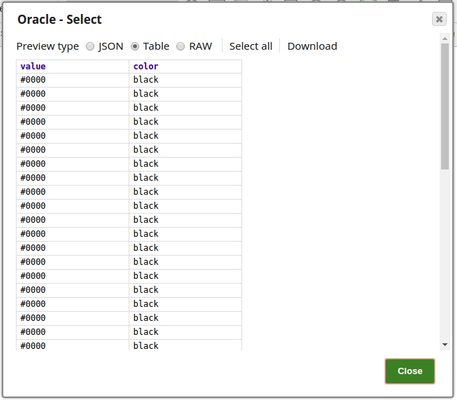
First output view is shown below. Table data is passed in this view.:
Second output view - output1. Table's data structure is passed to input1 in the Redshift Insert Snap:
Configuration and output preview of the Redshift Insert Snap:
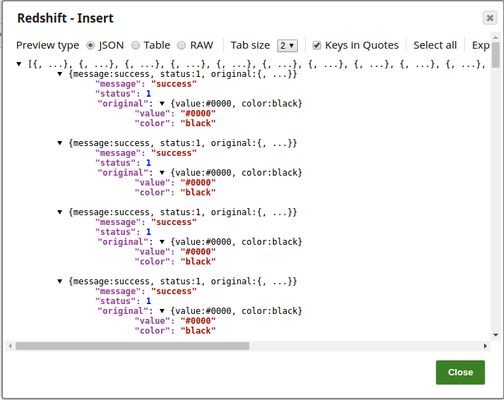
Configuration and output preview of the Redshift Lookup Snap:
Downloads
| Multiexcerpt include macro | ||||
|---|---|---|---|---|
|
| Attachments | ||
|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|