Atlassian uses cookies to improve your browsing experience, perform analytics and research, and conduct advertising. Accept all cookies to indicate that you agree to our use of cookies on your device. Atlassian cookies and tracking notice, (opens new window)
This Snap provides functionality to lookup records in the target Redshift table and return a selected set of fields for every matched record. The Snap executes one request per multiple input documents to avoid making a request for every input record.
JSON Path can be used in the Snap properties and will have values from an incoming document substituted into the properties. However, documents missing values for a given JSON path will be written to the Snap's error view. After a query is executed, the query's results are merged into the incoming document.
Queries produced by the Snap have the format:
SELECT [Output fields] FROM [Table name] WHERE
[C1 = V11 AND C2 = V21 AND...[Cn = Vn1] OR
[C1 = V12 AND C2 = V22 AND...[Cn = Vn2] OR
...................................... OR
[Cn = V1n AND Cm = V2m AND...[Cn = Vnm]
The Snap ignores any duplicated lookup condition in the input document stream since it maintains a cache for lookup conditions internally.
ETL Transformations & Data Flow
The Snap extracts records from a Redshift table based on the condition configured using input document stream/parameters.
Input & Output
Input: Each document in the input view should contain a Map data of key-value entries. Input data may contain values needed to evaluate expressions in the Object type, Output fields and Conditions properties. If the Pass-through on no lookupmatch property is unchecked, please make sure input data types match column data types in the database table. Otherwise, you may encounter an error message "Cannot find an input data which is related to the output record .....". If the error view is open, all input data in the batch are routed to the error view with the same error information.
Output: Each document in the output view contains a Map data of key-value entries, where keys are the Output fields' property values. The input data that has produced the corresponding output data is also included in the output data under the "original" key.
Expected Upstream Snaps: Any Snap which produces documents in the output view, for example CSV Parser, JSON Parser, Structure, Data, and so on.
Expected Downstream Snaps: Any Snap which receives documents in the input view, for example JSON Formatter, Structure, Data, etc. CSV Formatter will cause an error since the output data is not a flattened Map data.
If you use the PostgreSQL driver (org.postgresql.Driver) with the Redshift Snap Pack, it could result in errors if the data type provided to the Snap does not match the data type in the Redshift table schema. Either use the Redshift driver (com.amazon.redshift.jdbc42.Driver) or use the correct data type in the input document to resolve these errors.
Account:
This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Redshift Account for information on setting up this type of account.
Views:
Input
This Snap allows exactly one document input view and expects documents in the view. Each document should have values for one AND clause in the WHERE statement.
Output
This Snap has exactly one output view and produces documents in the view. The output document includes the corresponding input data under the "original" key. If there are no results from the query, each output field will have a null value.
Error
This Snap has at most one error view and produces zero or more documents in the view.
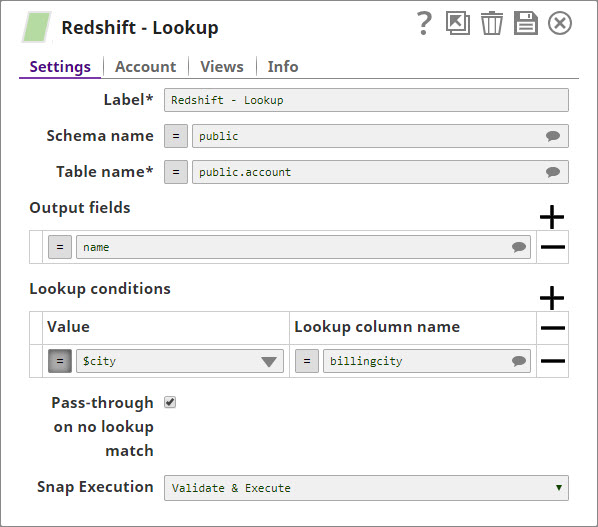
Settings
Label
Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline.
Schema name
The database schema name. Selecting a schema filters the Table name list to show only those tables within the selected schema.
Table name
Required. Enter or select the name of the table to execute the lookup query on
Example: people
Default value: [None]
Output fields
Required. Enter or select output filed names for SQL SELECT statement. If this property is empty, the Snap selects all fields by executing the statement "SELECT * FROM ...".
Example: email, address, first, last
Default value: [None]
Lookup conditions
Required. The lookup conditions are created by using the lookup column name and the lookup column value. Each row will build a condition, such aslookupColumn1 = $inputField. Each additional row will be concatenated using a logical AND. All rows together build the lookup condition being used to lookup records in the lookup table.
Default value: Not selected
Value
Required. Enter or select the JSON path of the lookup column value. The value will be provided by the input data field.JSON path of the lookup column value. The value will be provided by the input data field.
Example: $email, $first, $last
Default value: [None]
Lookup column name
Required. Enter or select lookup column name.
Example: email, first, last, etc.
Default value: [None]
Pass-through on no lookup match
When there is no lookup matching an input document, the input document will pass through to the output view if this property is checked. Otherwise, it will be written to the error view as an error condition.
Default value: False
Number of Retries
Specifies the maximum number of attempts to be made to receive a response. The request is terminated if the attempts do not result in a response.
Example: 3
Default value: 0
Retry Interval (seconds)
Specify the time interval between two successive retry requests. A retry happens only when the previous attempt resulted in an exception.
Example: 10
Default value: 1
Snap Execution
Default Value: Validate & Execute Example: Execute only
Select an option to specify how the Snap must be executed. Available options are:
Validate & Execute: Performs limited execution of the Snap (up to 50 records) during Pipeline validation; performs full execution of the Snap (unlimited records) during Pipeline execution.
Execute only: Performs full execution of the Snap during Pipeline execution; does not execute the Snap during Pipeline validation.
Disabled: Disables the Snap and, by extension, its downstream Snaps.
Troubleshooting
Error
Reason
Resolution
type "e" does not exist
This issue occurs due to incompatibilities with the recent upgrade in the Postgres JDBC drivers.
Download the latest 4.1 Amazon Redshift driverhereand use this driver in yourRedshift Account configuration and retry running the Pipeline.
Examples
Basic Use Cases
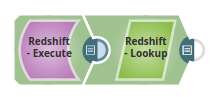
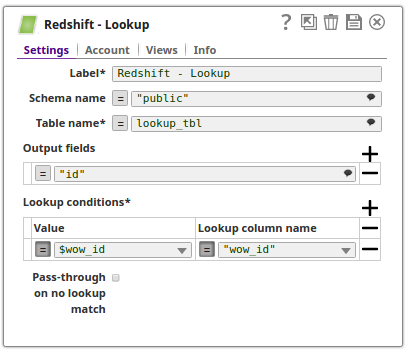
The following example shows looking up names of people based upon the billing city. The city name is passed using the JSON Generator Snap and the Lookup Snap searches and retrieves the records based on the Lookup conditions where the billing city matches to the value $city as passed via the upstream.
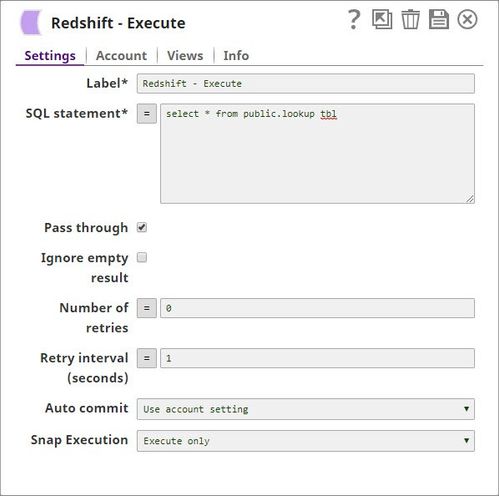
In the below pipeline, the Redshift Execute Snap reads the records from a table and the Lookup Snap retrieves the specified records as configured on the Lookup conditions.
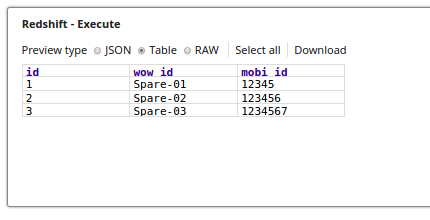
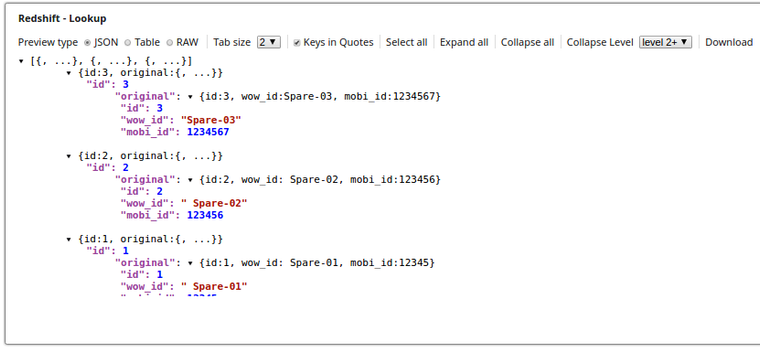
The Execute Snap reads the records from from a table public.lookup_tbl and the respective output preview as below:
The Lookup Snap retrieves the records from the table lookup_tbl and the respective output preview is as displayed below:
Typical Snap Configurations
Key configuration of the Snap lies in how SQL statements are passed to perform lookup of the records. The statements can be passed:
Without Expressions
The values are passed directly into the Snap.
With Expressions
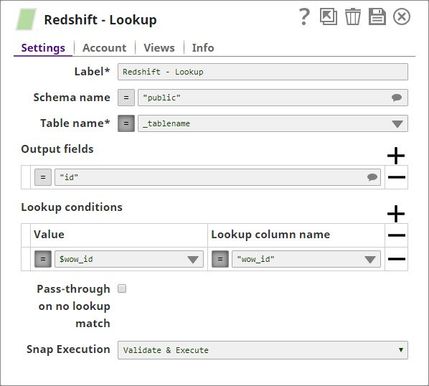
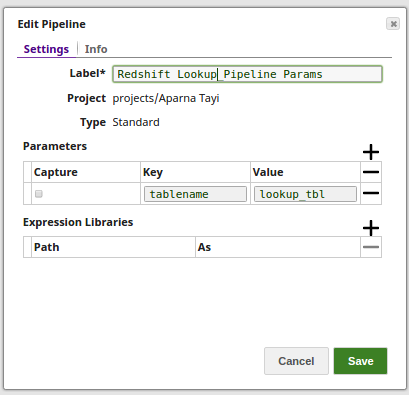
Using Pipeline parameters: The Table name is passed as a pipeline parameter.
Advanced Use Case
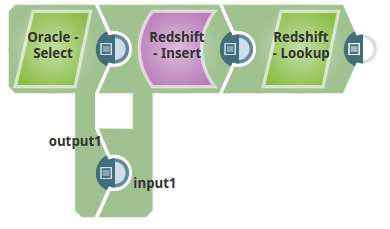
The following describes a pipeline that shows how typically in an enterprise environment, a lookup functionality is used. Pipeline download link is in the Downloads section below.
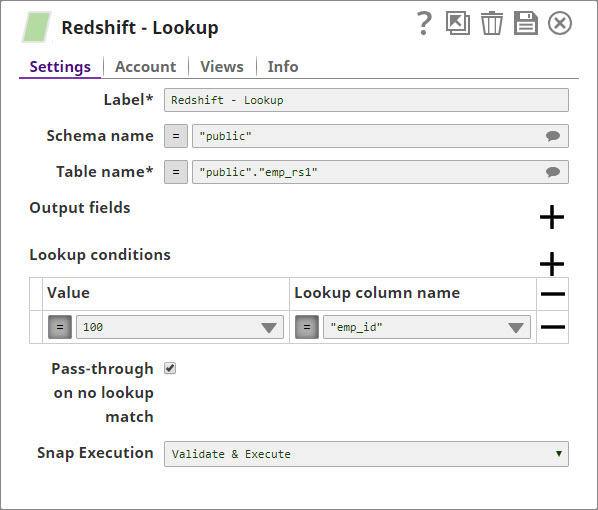
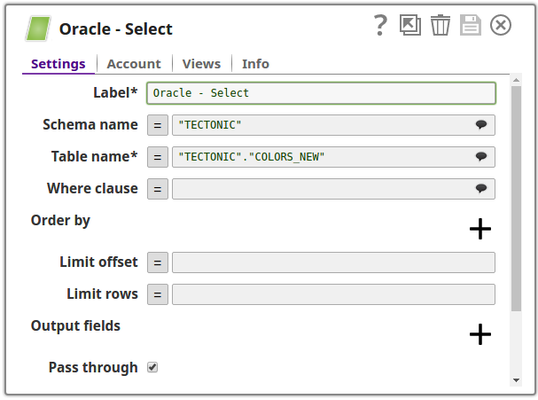
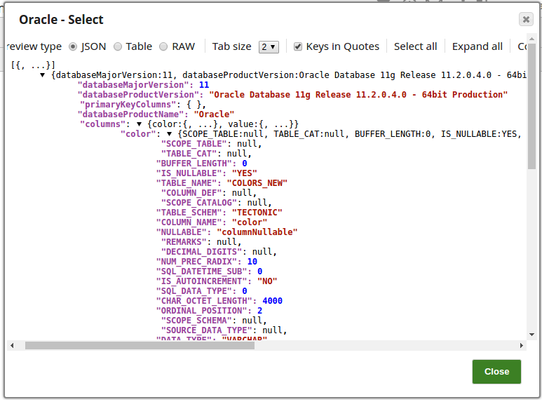
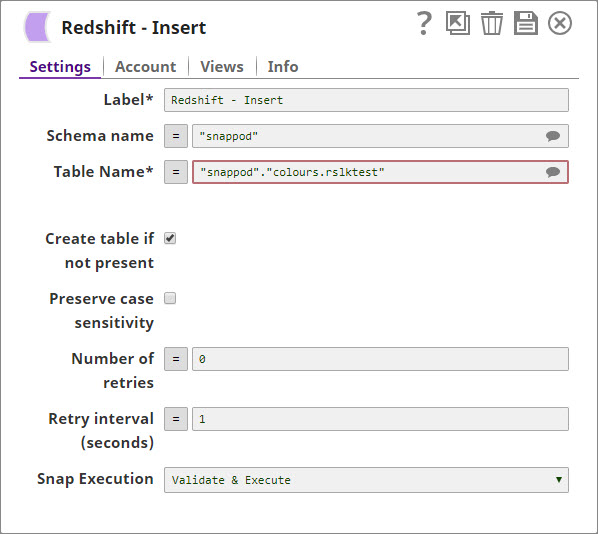
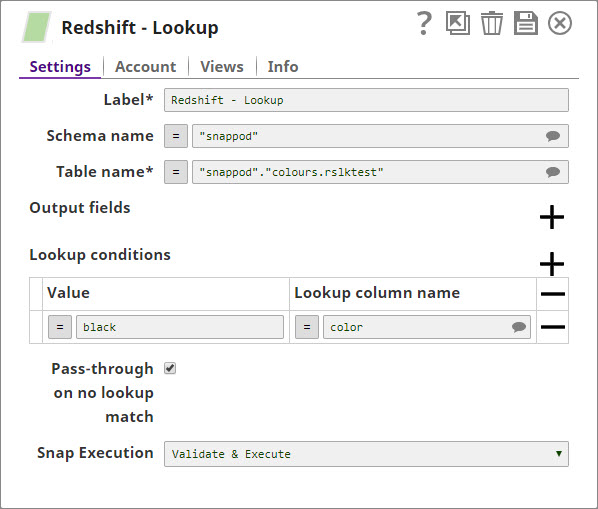
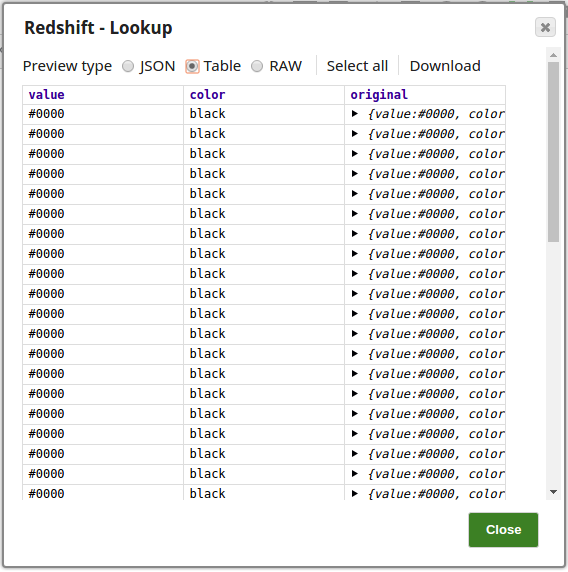
In this pipeline, a table "COLORS_NEW" belonging to the "TECTONIC" schema is selected from the Oracle DB, the values and data structure are passed to the Redshift Insert Snap where it is inserted into another table "colours_rslktest" in the "snappod" schema of the Redshift DB. The Redshift Insert Snap is configured to create a new table if the specified table does not exist and insert the data from the Oracle Select Snap into it. The Redshift Lookup Snap is then used to lookup all the records in this table that match the specified Lookup conditions. Output previews and configurations of each of the Snaps used in this pipeline are shown below.
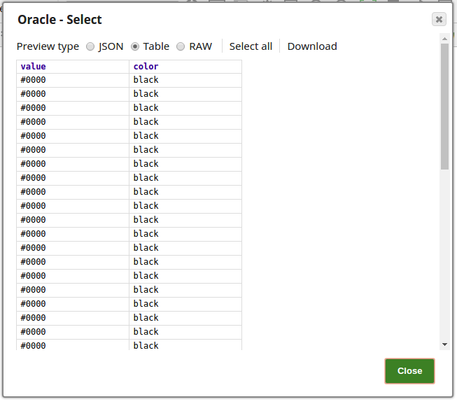
Configuration and the output preview of the Oracle Select Snap respectively:
Note that there are two output views in the Oracle Select Snap, the first output view passes the table's data whereas the second output view (output1) passes the data structure.
First output view is shown below. Table data is passed in this view.:
Second output view - output1. Table's data structure is passed to input1 in the Redshift Insert Snap:
Configuration and output preview of the Redshift Insert Snap:
Configuration and output preview of the Redshift Lookup Snap:
Downloads
Important steps to successfully reuse Pipelines
Download and import the pipeline into the SnapLogic application.
Updated and certified against the current SnapLogic Platform release.
November 2024
main29029
Stable
Updated and certified against the current SnapLogic Platform release.
August 2024
main27765
Stable
Upgraded the org.json.json library from v20090211 to v20240303, which is fully backward compatible.
Upgraded the JDBC driver for the Redshift Snap Pack to v2.1.0.29 to address the SQL Injection vulnerabilities. Pipelines using the Redshift Snaps are not impacted after the driver upgrade, because the latest JDBC driver is fully backward compatible.
May 2024
437patches26634
Latest
Fixed an issue withRedshift - Execute Snap that produced logs causing node crashes.
May 2024
main26341
Stable
Updated the Delete Condition (Truncates a Table if empty) field in the Redshift - DeleteSnap to Delete condition (deletes all records from a table if left blank) to indicate that all entries will be deleted from the table when this field is blank, but no truncate operation is performed.
February 2024
main25112
Stable
Updated and certified against the current SnapLogic Platform release.
November 2023
main23721
Stable
Updated and certified against the current SnapLogic Platform release.
August 2023
main22460
Stable
The Redshift-Bulk Load and Redshift-Bulk Upsert Snaps now support expression enablers for the Additional options field that enables you to use parameters.
The Redshift - Execute Snap now includes a new Query type field. When Auto is selected, the Snap tries to determine the query type automatically.
Behavior Change
Starting withversion main22460, in the Redshift Select Snap:
When you create a table in Redshift, by default, all column names are displayed in lowercase in the output.
When you enter column names in uppercase in theOutput Fieldproperty, the column names are displayed in lowercase in the output.
May 2023
main21015
Stable
Upgraded with the latest SnapLogic Platform release.
February 2023
432patches20500
Latest
The Redshift Account no longer fails when a URL is entered in the JDBC URL field and no driver is specified.
February 2023
432patches20166
Latest
Updated the description for S3 Security Token field as follows:
Specify the S3 security token part of AWS Security Token Service (STS) authentication. It is not required unless a particular S3 credential is configured to require it.
February 2023
432patches20101
Latest
The JDBC driver class for Redshift accounts is bundled with the com.amazon.redshift.jdbc42.Driver as the default driver. This upgrade is backward-compatible. The existing pipelines will continue to work as expected and the new pipelines will use the Redshift Driver as the default driver. SnapLogic will support providing fixes for the issues you might encounter with accounts that use the PostgreSQL driver only until November 2023. After November 2023, SnapLogic will not provide support for the issues with the PostgreSQL driver. Therefore, we recommend you to migrate from the PostgreSQL JDBC driver to the Redshift JDBC driver. Learn more about migrating from the PostgreSQL JDBC Driver to the Amazon Redshift Driver. (432patches20101)
The Instance type option in the Redshift Bulk Load Snap enables you to use the Amazon EC2 R6a instance. This property appears only when the parallelism value is greater than one.
February 2023
432patches20035
Latest
The Redshift Snaps that earlier supported only Redshift Cluster now support Redshift Serverless as well. With Redshift Serverless, you can avoid setting up and managing data warehouse infrastructure when you run or scale analytics.
February 2023
main19844
Stable
Upgraded with the latest SnapLogic Platform release.
November 2022
main18944
Stable
TheRedshift - InsertSnap now creates the target table only from the table metadata of the second input view when the following conditions are met:
The Create table if not present checkbox is selected.
The target table does not exist.
The table metadata is provided in the second input view.
The Redshift Account now validates correctly when the S3 bucket is blank.
August 2022
main17386
Stable
The Redshift accounts support:
Expression enabler to pass values from Pipeline parameters.
Security Token for S3 bucket external staging.
4.29 Patch
429patches16908
Latest
Enhanced the Redshift accounts with the following:
Expression enabler to pass values from Pipeline parameters.
Support for Security Token for S3 bucket external staging.
Fixed an issue with Redshift - Execute Snap where the Snap failed when the query contained comments with single or double quotes in it. Now the Pipeline executes without any error if the query contains a comment.
4.29 Patch
429patches15806
Latest
Fixed an issue with Redshift Account and Redshift SSL Account where the Redshift Snaps failed when the S3 Secret key or S3 Access-key IDcontained special characters, such as +.
4.29
main15993
Stable
Upgraded with the latest SnapLogic Platform release.
4.28
main14627
Stable
Updated the label for Delete Condition to Delete Condition (Truncates Table if empty) in the Redshift DeleteSnap.
4.27 Patch
427patches12999
Latest
Fixed an issue with the Redshift Bulk Load Snap, where the temporary files in S3 were not deleted for aborted or interrupted Pipelines.
Upgraded with the latest SnapLogic Platform release.
4.25 Patch
425patches11008
Latest
Updated the AWS SDK from version 1.11.688 to 1.11.1010 in the Redshift Snap Pack and added a custom SnapLogic User Agent header value.
4.25
main9554
Stable
Upgraded with the latest SnapLogic Platform release.
4.24
main8556
Stable
Enhanced the Redshift - SelectSnap to return only the selected output fields or columns in the output schema (second output view) using the Fetch Output Fields In Schema checkbox. If the Output Fields field is empty all the columns are visible.
Fixed an issue with theRedshift Bulk Load Snapthat fails while displaying aFailed to commit transactionerror.
4.22
main6403
Stable
Upgraded with the latest SnapLogic Platform release.
4.21 Patch
421patches6144
Latest
Fixed the following issues with DB Snaps:
The connection thread waits indefinitely causing the subsequent connection requests to become unresponsive.
Connection leaks occur during Pipeline execution.
4.21 Patch
MULTIPLE8841
Latest
Fixed the connection issue in Database Snaps by detecting and closing open connections after the Snap execution ends.
4.21
snapsmrc542
Stable
Upgraded with the latest SnapLogic Platform release.
4.20 Patch
db/redshift8774
Latest
Fixed the Redshift - Execute Snap that hangs if theSQL statement field contains only a comment ("-- comment").
4.20
snapsmrc535
Stable
Upgraded with the latest SnapLogic Platform release.
4.19 Patch
db/redshift8410
Latest
Fixed an issue with the Redshift - Update Snap wherein the Snap is unable to perform operations when:
An expression is used in theUpdate conditionproperty.
Input data contain the character '?'.
4.19
snaprsmrc528
Stable
Upgraded with the latest SnapLogic Platform release.
4.18 Patch
db/redshift8043
Latest
Enhanced the Snap Pack to support AWS SDK 1.11.634 to fix the NullPointerException issue in the AWS SDK. This issue occurred in AWS-related Snaps that had HTTP or HTTPS proxy configured without a username and/or password.
4.18 Patch
MULTIPLE7884
Latest
Fixed an issue with the PostgreSQL grammar to better handle the single quote characters.
4.18 Patch
MULTIPLE7778
Latest
Updated the AWS SDK library version to default to Signature Version 4 Signing process for API requests across all regions.
4.18
snapsmrc523
Stable
Upgraded with the latest SnapLogic Platform release.
4.17 Patch
db/redshift7433
Latest
Fixed an issue with the Redshift Bulk Load Snap wherein the Snap fails to copy the entire data from source to the Redshift table without any statements being aborted.
4.17
ALL7402
Latest
Pushed automatic rebuild of the latest version of each Snap Pack to SnapLogic UAT and Elastic servers.
4.17
snapsmrc515
Latest
Fixed an issue with the Redshift Execute Snap wherein the Snap would send the input document to the output view even if the Pass through field is not selected in the Snap configuration. With this fix, the Snap sends the input document to the output view, under the key original, only if you select the Pass through field.
Added the Snap Execution field to all Standard-mode Snaps. In some Snaps, this field replaces the existing Execute during preview checkbox.
4.16 Patch
db/redshift6821
Latest
Fixed an issue with the Lookup Snap passing data simultaneously to output and error views when some values contained spaces at the end.
4.16
snapsmrc508
Stable
Upgraded with the latest SnapLogic Platform release.
4.15 Patch
db/redshift6286
Latest
Fixed an issue with the Bulk Upsert Snap wherein there was no output for any input schema.
4.15 Patch
db/redshift6334
Latest
ReplacedMax idle timeandIdle connection testperiodproperties withMax life timeandIdle Timeout properties, respectively, in the Account configuration. The new properties fix the connection release issues that were occurring due to default/restricted DB Account settings.
4.15
snapsmrc500
Stable
Upgraded with the latest SnapLogic Platform release.
4.14 Patch
db/redshift5786
Latest
Fixed an issue wherein the Redshift Upload snap logged the access and secret keys without encryption in the error logs. The keys are now masked.
4.14 Patch
db/redshift5667
Latest
Added "Validate input data" property in the Redshift Bulk Load Snap to enable users to troubleshoot input data schema.
Enhanced a check to identify whether the Provided Query in the Redshift Execute Snap is of read or write type.
4.14
snapsmrc490
Stable
Upgraded with the latest SnapLogic Platform release.
4.13 Patch
db/redshift/5303
Latest
Added a new property "Validate input data" in the Redshift Bulk Load Snap to help users troubleshoot the input data schema.
4.13 Patch
db/redshift5186
Latest
Fixed the Bulk Load and Unload Snaps wherein the KMS encryption type property is failing with validation error.
4.13
snapsmrc486
Stable
Added KMS encryption support to these Snaps: Redshift Unload, Redshift Bulk Load, Redshift Bulk Upsert, and Redshift S3 Upsert.
4.12 Patch
db/redshift5027
Latest
Fixed an issue wherein the Redshift Snaps timeout and fail to retrieve a database connection.
4.12 Patch
MULTIPLE4967
Latest
Provided an interim fix for an issue with the Redshift accounts by re-registering the driver for each account validation. The final fix is being shipped in a separate build.
4.12 Patch
MULTIPLE4744
Latest
Added support for Redshift grammar to recognize window functions as being part of the query statement.
4.12
snapsmrc480
Stable
Upgraded with the latest SnapLogic Platform release.
4.11 Patch
db/redshift4589
Latest
Fixed an issue when creating a Redshift table via the second/metadata input viewfor the Redshift Bulk Load Snap.
The Upsert or BulkUpdate/BulkLoad shall not execute and produce output when no inputView has been provided.
4.10 Patch
redshift3936
Latest
Addressed an issue in Redshift Execute with a Select that hangs after extracting 13 million in the morning or 30 million in the evening
4.10
snapsmrc414
Stable
AddedAuto commitproperty to the Select and Execute Snaps at the Snap level to support overriding of theAuto commitproperty at the Account level.
4.9.0 Patch
redshift3229
Latest
Addressed an issue in Redshift Multiple Execute where INSERT INTO SELECT statement generated a 'transaction, commit and rollback statements are not supported' exception.
4.9.0 Patch
redshift3073
Latest
Fixed an issue regarding connection not closed after login failure; Expose autocommit for "Select into" statement in PostgreSQL Execute Snap and Redshift Execute Snap
4.9
snapsmrc405
Stable
Updated the Bulk Load, Bulk Upsert and S3 Upsert Snaps with the properties Vacuum type & Vacuum threshold (%) (replaced the original Vacuum property).
Update the S3 Upsert Snap with the properties, IAM role and Server-side encryption to support data upsert across two VPCs.
Added support for the Redshift driver under the account setting for JDBC jars.
4.8.0 Patch
redshift2852
Latest
Addressed an issue with Redshift Insert failing with 'casts smallint as varchar'
Addressed an issue with Redshift Bulk Upsert fails to drop temp table
4.8.0 Patch
redshift2799
Latest
Addressed an issue with Redshift Snaps with the default driver failing with could not load JDBC driver for url file.
Added the properties,JDBC Driver Class,JDBC jarsandJDBC Urlto enable the users toupload the Redshift JDBC drivers that can override the default driver.
4.8.0 Patch
redshift2758
Latest
Potential fix for JDBC deadlock issue.
4.8.0 Patch
redshift2713
Latest
Fixed Redshift Snap Pack rendering dates that are one hour off from the date returned by database query for non-UTC Snaplexes
4.8.0 Patch
redshift2697
Latest
Addresses an issue where some changes made in the platform patch MRC294 to improve performance caused Snaps in the listed Snap Packs to fail.
4.8
snapsmrc398
Stable
Redshift MultiExecute Snap introduced in this release.
Redshift Account: Info tab added to accounts.
Database accounts now invalidate connection pools if account properties are modified and login attempts fail.
Info tab added to accounts.
Database accounts now invalidate connection pools if account properties are modified and login attempts fail.
4.7.0 Patch
redshift2434
Latest
Replaced newSingleThreadExecutor() with a fixed thread pool.
4.7.0 Patch
redshift2387
Latest
Addressed an issue in Redshift Bulk Load Snap where Load Empty String was setting not working after release.
4.7.0 Patch
redshift2223
Latest
Auto-commit is turned off automatically for SELECT
4.7.0 Patch
redshift2201
Latest
Fixed an issue for database Select Snaps regarding Limit rows not supporting an empty string from a pipeline parameter.
4.7
snapsmrc382
Stable
Updated the Redshift Snap Account Settings with the IAM properties that include AWS account ID , IAM role name, and Region name.
Redshift Bulk Load Snap updated with the properties IAM Role & Server-side encryption.
Redshift Bulk Upsert Snap updated with the properties Load empty strings, IAM Role & Server-side encryption.
Updated the Redshift Upsert Snap with Load empty strings property.
Updated the Redshift Unload Snap with the property IAM role.
4.6
snapsmrc362
Stable
Redshift Execute Snap enhanced to fully support SQL statements with/without expressions & SQL bind variables.
Resolved an issue in Redshift Execute Snap that caused errors when executing a command Select current_schemas(true).
Resolved an issues in Redshift Execute Snap that caused errors when a Select * from <table_name> into statement was executed.
Enhanced error reporting in Redshift Bulk Load Snap to provided appropriate resolution messages.
4.5.1
redshift1621
Latest
Redshift S3 Upsert Snap introduced in this release.
Resolved an issue that occurred while inserting mismatched data type values in Redshift Insert Snap.
4.5
snapsmrc344
Stable
Resolved an issue in Redshift Bulk Upsert Snap that occurred when purging temp tables.
Resolved an issue in Redshift Upload/Upsert Snap that occurred when using IAM credentials in an EC2 instance with an S3 bucket.
4.4.1
NA
Latest
Resolved an issue with numeric precision when trying to use create table if not present in Redshift Insert Snap.
4.4
NA
Stable
Upgraded with the latest SnapLogic Platform release.
4.3.2
NA
Stable
Redshift Select Where clause property now has expression support.
Redshift Update Update condition property now has expression support.
Resolved an issue with Redshift Select Table metadata being empty if the casing is different from the suggested one for table name
4.3
NA
Stable
Table List Snap: A new option, Compute table graph, now lets you determine whether or not to generate dependents data into the output.
Redshift Unload Snap Parallel property now explicitly adds 'PARALLEL [OFF|FALSE]' to the UNLOAD query.
4.2
NA
Latest
Resolved an issue where Redshift SCD2 Snap historized the current row when no Cause-historization fields had changed.
Ignore empty result added to Execute and Select Snaps. The option will not any document to the output view for select statements.
Resolved an issue with Redshift Select Snap returning a Date object for DATE column data type instead of a LocalDate object.
Resolved an issue in RedShift SCD2 failing to close database cursor connection.
Resolved an issue with Redshift Lookup Snap not handling values with spaces in the prefix.
Updated driver not distributed with the Redshift Snap Pack.
Output fields table property added to Select Snap.
Resolved an issue with Redshift - Bulk Loader incorrectly writing to wrong location on S3 and disable data compression not working
Resolved an issue in Execute and Select Snaps where the output document was the same as the input document if the query produces no data. When there is no result from the SELECT query, the input document will be passed through to the output view as a value to the 'original' key. The new property Pass through with true default.
NA
NA
NA
Redshift Account: Enhanced error messaging
Redshift SCD2: Bug fixes with compound keys
RedShift Lookup: Bug fixes on lookup failures; Pass-though on no lookup match property added to allow you to pass the input document through to the output view when there is no lookup matching.