Redshift - S3 Upsert
On this Page
Snap Type: | Write | |||||||
|---|---|---|---|---|---|---|---|---|
Description: | This Snap executes a Redshift S3 upsert. This Snap directly upserts (inserts or updates) data from a file (source) on a specified Amazon S3 location to the target Redshift table. A temporary table is created on Redshift with the contents of the staging file. An update operation is then run to update existing records in the target table and/or an insert operation is run to insert new records into the target table. Refer to AWS Amazon documentation for more information. ETL Transformations & Data FlowThe Redshift S3 Upsert Snap loads the data from the given list of s3 files using the COPY command and inserts the data if not already in the the redshift table using INSERT ALL query or update if it exists. Input & Output:Input: This Snap can have an upstream Snap that can pass values required for expression fields. Output: A document that contains the result providing the number of documents being inserted/ updated/ failed. Modes
| |||||||
| Prerequisites: |
Loading | |||||||
| Limitations and Known Issues: | Loading | |||||||
| Configurations: | Account & AccessThis Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. The S3 Bucket, S3 Access-key ID, and S3 Secret key properties are required for the Redshift- S3 Upsert Snap. The S3 Folder property may be used for the staging file. If the S3 Folder property is left blank, the staging file will be stored in the bucket. See Redshift Account for information on setting up this type of account. Loading Views:
| |||||||
| Troubleshooting: | None. | |||||||
Settings | ||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||
Schema name | Required. The database schema name. Selecting a schema filters the Table name list to show only those tables within the selected schema. The values can be passed using the pipeline parameters but not the upstream parameter. Example: schema123 Default value: [None] | |||||||
Table name | Required. Table on which to execute the upsert operation. The property can be given in format of either <schema>.<table_name> or <table_name>. It is suggestible and will retrieve available tables under the schema (if given) during suggest values. The values can be passed using the pipeline parameters but not the upstream parameter. Example:
Default value: [None] | |||||||
Key columns | Required. Columns to use to check for existing entries in the target table. Example: id Default value: [None] | |||||||
S3 file list | Required. List of S3 files to be loaded into the target table as file names or as expressions. Example: s3:///testing/testtablefors3.csv Default value: [None] | |||||||
| IAM Role | Select this property if the bulk load/unload needs to be performed using an IAM role. If selected, ensure the properties (AWS account ID, role name and region name) are provided in the account. Default value: Not selected | |||||||
Server-side encryption | This defines the S3 encryption type to use when temporarily uploading the documents to S3 before the insert into the Redshift. Default value: Not selected | |||||||
| KMS Encryption type | Specifies the type of KMS S3 encryption to be used on the data. The available encryption options are:
Default value: None If both the KMS and Client-side encryption types are selected, the Snap gives precedence to the SSE, and displays an error prompting the user to select either of the options only. | |||||||
| KMS key | Conditional. This property applies only when the encryption type is set to Server-Side Encryption with KMS. This is the KMS key to use for the S3 encryption. For more information about the KMS key, refer to AWS KMS Overview and Using Server Side Encryption. Default value: [None] | |||||||
Truncate data | Truncate existing data before performing data load. With the Bulk Update Snap, instead of doing truncate and then update, a Bulk Insert would be faster. Default value: Not selected | |||||||
Update statistics | Update table statistics after data load by performing an analyze operation on the table. Default value: Not selected | |||||||
Accept invalid characters | Accept invalid characters in the input. Invalid UTF-8 characters are replaced with a question mark when loading. Default value: Selected | |||||||
Maximum error count | Required. A maximum number of rows which can fail before the bulk load operation is stopped. By default, the load stops on the first error. Example: 10 (if you want the pipeline execution to continue as far as the number of failed records is less than 10) | |||||||
Truncate columns | Truncate column values which are larger than the maximum column length in the table. Default value: Selected | |||||||
Load empty strings | If selected, empty string values in the input documents are loaded as empty strings to the string-type fields. Otherwise, empty string values in the input documents are loaded as null. Null values are loaded as null regardless. Default value: Not selected | |||||||
Compression format | The format in which the provided S3 files are compressed in. Specifies:
Example: GZIP Default value: Uncompressed | |||||||
File type | The type of input files. Specifies:
Example: JSON Default value: CSV | |||||||
Ignore header | Required. Treats the specified number of rows as file headers and does not load them. Example: 1 Default value: 0 | |||||||
Delimiter | The single ASCII character that is used to separate fields in the input file, such as a pipe character ( | ), a comma (, ), or a tab ( \t ). Non-printing ASCII characters are supported. ASCII characters can also be represented in octal, using the format '\ddd', where 'd' is an octal digit (0–7). The default delimiter is a pipe character ( | ), unless the CSV parameter is used, in which case the default delimiter is a comma (, ). The AS keyword is optional. DELIMITER cannot be used with FIXEDWIDTH. Example: , Default value: pipe character ( | ) | |||||||
Additional options | Additional options to be passed to the COPY command. Refer to AWS Amazon - COPY documentation for available options. Example: ACCEPTANYDATE Default value: [None] | |||||||
Vacuum type | Reclaims space and sorts rows in a specified table after the upsert operation. The available options to activate are FULL, SORT ONLY, DELETE ONLY and REINDEX. Please refer to the AWS Amazon - VACUUM documentation for more information. Example: FULL Default value: [None] | |||||||
Vacuum threshold (%) | Specifies the threshold above which VACUUM skips the sort phase. If this property is left empty, Redshift sets it to 95% by default. Default value: [None] | |||||||
Loading | Loading | |||||||
Redshift's Vacuum Command
In Redshift, when rows are DELETED or UPDATED against a table they are simply logically deleted (flagged for deletion), not physically removed from disk. This causes the rows to continue consuming disk space and those blocks are scanned when a query scans the table. This results in an increase in table storage space and degraded performance due to otherwise avoidable disk IO during scans. A vacuum recovers the space from deleted rows and restores the sort order.
Groundplex System Clock and Multiple Snap Instances with the same 'S3 file list' property
- The system clock of the Goundplex should be accurate down to less than a second. The Snap executes Redshift COPY command to have Redshift load CSV data from S3 files to a temporary table created by the Snap. If Redshift fails to load any record, it stores the error information for each failed CSV record into the system error table in the same Redshift database. Since all errors from all executions go to the same system error table, the Snap executes a SELECT statement to find the errors related to a specific COPY statement execution. It uses WHERE clause including the CSV filenames, start time and end time. If the system clock of Groundplex is not accurate down to less than a second, the Snap might fail to find error records from the error table.
- If multiple instances of the Redshift - S3 Upsert Snap have the same S3 file list property value and execute almost same time, the Snap will fail to report correct error documents in the error view. Users should make sure each Redshift - S3 Upsert Snap instance with the same S3 file list executes one at a time.
Troubleshooting
Examples
Basic Use Case
The following pipeline describes how the Snap functions as a standalone Snap in a pipeline:
Step1: Provide a valid Redshift account and database/ table name to upload all the documents in the target table.
Step2: Provide a valid S3 account parameters and S3 file list parameter to copy the list of documents.
Step3: Make sure to choose the proper parameters in the Settings tab and invoke the pipeline.
Below is a preview of the output from the Redshift S3 Upsert Snap depicting that four records have been inserted into the table:
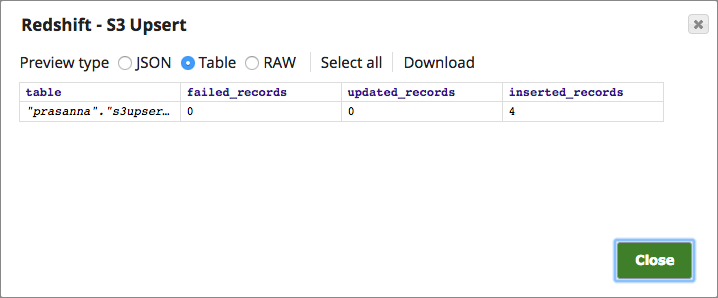
We can also verify the same by checking it in Redshift database.
Refer to the "Redshift - S3 Upsert_2017_10_16.slp" in the Download section for more reference
Typical Snap Configurations
Key configuration of the Snap lies in how S3 file list are passed to perform the upsert of the records. The S3 file lists can be passed:
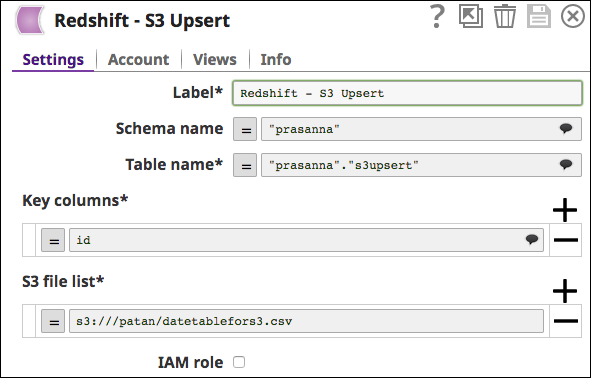
- Without Expressions:
The values are passed directly to the snap
- With Expressions:
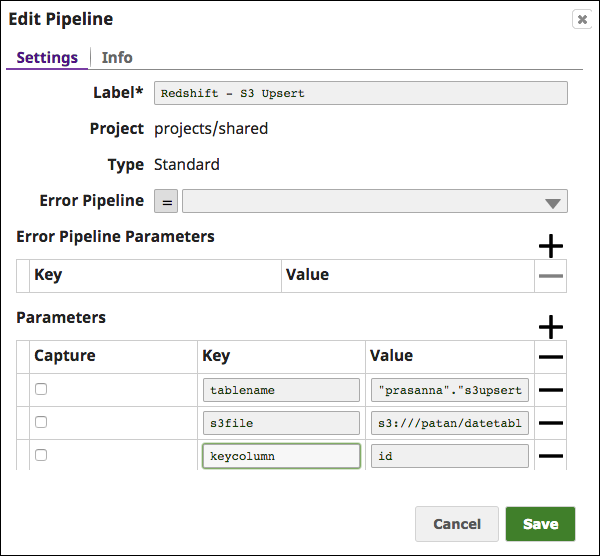
- Using Pipeline parameters:
The table name, Key columns and S3 file list can be passed as the pipeline parameter
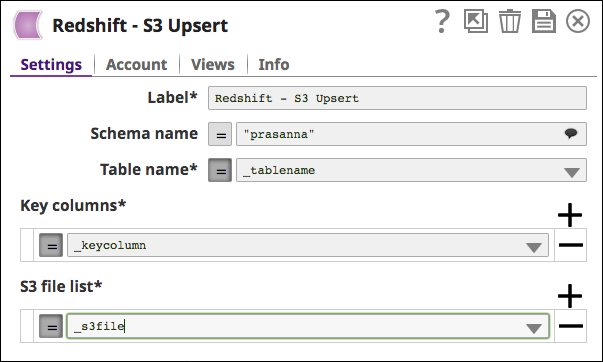
The Redshift S3 Upsert Snap with the pipeline parameter as the Table name/ S3 file list/ Key column:
Advanced Use Case
The following pipeline describes how the Snap functions as a standalone Snap in a pipeline by passing some invalid values (Trying to pass invalid UTF-8 characters in the bpchar(1) column created in Redshift table)
Below is the table structure in Redshift:
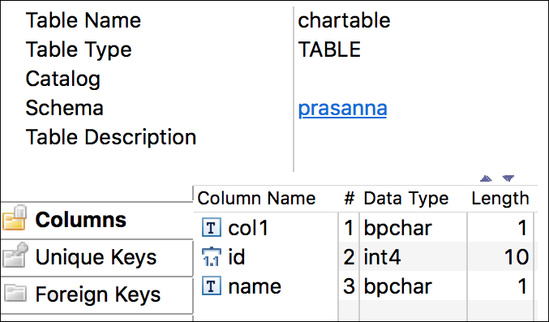
We are then trying to pass a CSV files with some invalid characters (with 6 invalid records). CSV file "chartablefors3_new.csv" has been attached in the Downloads section. Also trying to accept the Invalid characters in the Redshift table by specifying the same in "Additional Options" as show below in the snap configuration:
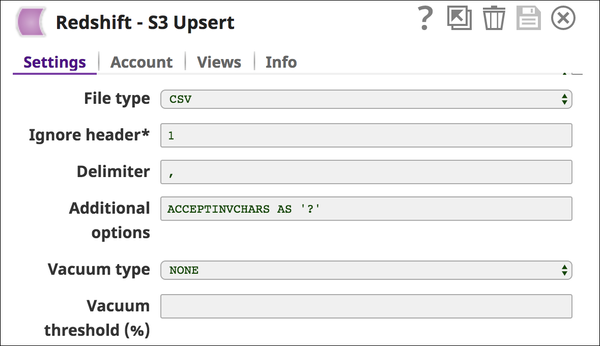
ACCEPTINVCHARS [AS] ['replacement_char'] enables loading of data into VARCHAR columns even if the data contains invalid UTF-8 characters. When ACCEPTINVCHARS is specified, COPY replaces each invalid UTF-8 character with a string of equal length consisting of the character specified by replacement_char. ACCEPTINVCHARS is valid only for VARCHAR columns. Refer to the AWS Amazon documentation - Data Conversion for more information.
Since the data type provided is bpchar which will throw an error for 6 records.
Below is a preview of the output from the Redshift S3 Upsert Snap depicting that three records have been updated into the table and other six records have been failed:
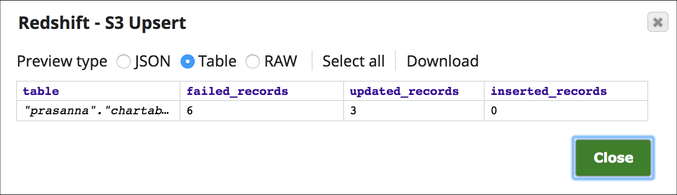
Errors are shown below for your reference:
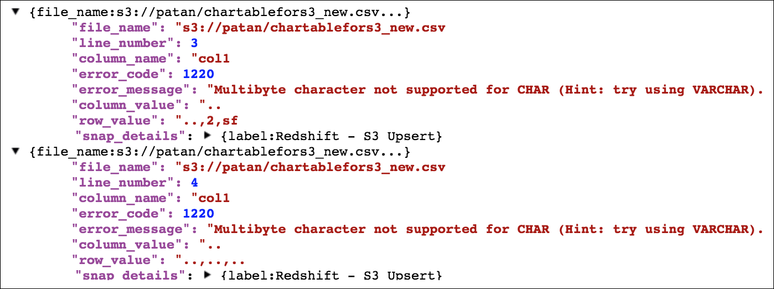
Refer to the "Redshift S3 Upsert - additional options.slp" in the Download section for more reference
Downloads
Related Information
This section gives you a consolidated list of internal and external resources related to this Snap:
Older Examples
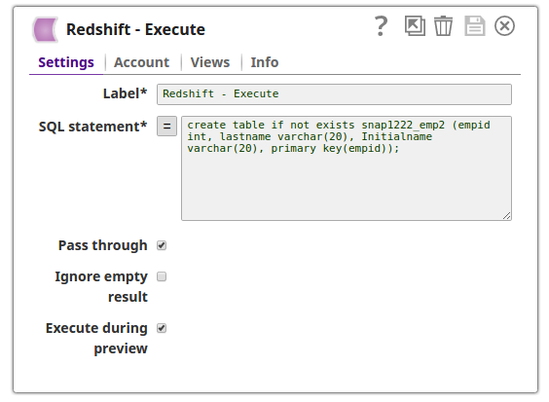
In this pipeline, the Redshift Execute Snap creates a table on a Redshift Database server. The Redshift S3 Upsert Snap upserts the records into the table from a file on an S3 location.
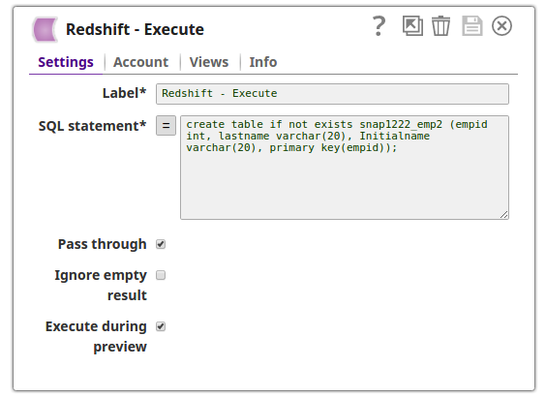
The Redshift Execute Snap creates the table, snap1222_emp2 on the Redshift Database server.
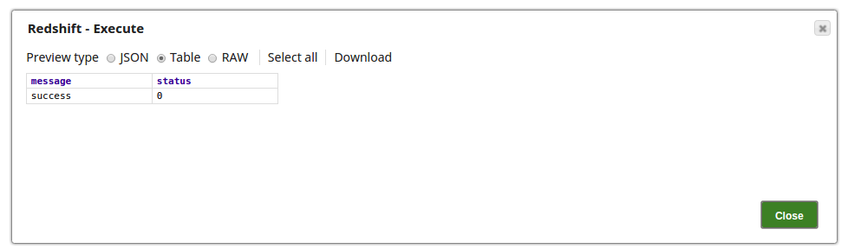
The success status is as displayed below:
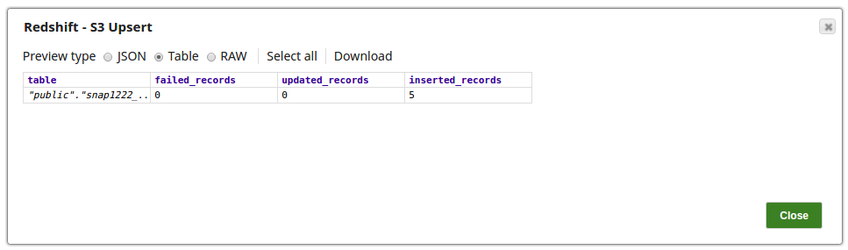
The S3 Upsert Snap upserts the records from the file Emp_S3.csv , from an S3 location on to the table, snap1222_emp2 on the Redshift Database.
Additionally, the IAM role is selected, and hence ensure that the table structure is same as on the file on S3 location.

The successful execution of the pipeline displays the below output preview:
Example # 1
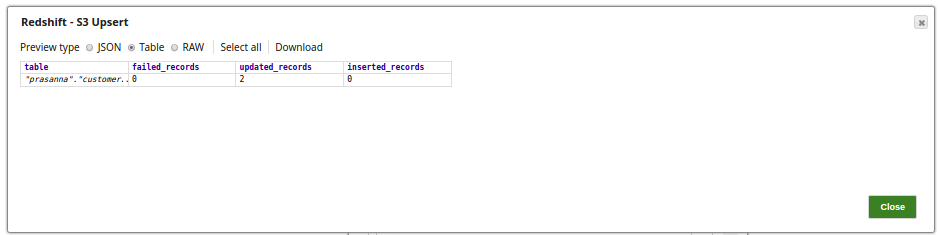
In this example, the table, customer_interleaved in the schema, prasanna, is read and the s3:///patan/customer_interleaved.csv file is upserted (updated or inserted) with records. The table that is read and the file that is updated exists in Amazon S3.
The successful execution of the pipeline displays the output preview where 2 records have been updated:
Example # 2
The example assumes that you have configured & authorized a valid Redshift account (see Redshift Account) to be used with this Snap. In the following example, employee_1 table in the schema, space in schema, is read and the employee_1.csv file is upserted (updated or inserted) with records. The table that is read and the file that is updated exists in Amazon S3.
.png?version=1&modificationDate=1489840328162&cacheVersion=1&api=v2&width=550&height=490)
See Also
Snap Pack History
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.