Redshift - Unload
On this Page
Snap Type: | Read | |||||||
|---|---|---|---|---|---|---|---|---|
Description: | This Snap unloads the result of a query to one or more files on Amazon S3, using Amazon S3 server-side encryption (SSE)/server-side encryption with KMS/client-side encryption with CMK. The target Redshift table is not modified. ETL Transformations & Data Flow https://github.com/awslabs/amazon-redshift-utils/tree/master/src/UnloadCopyUtility. [
{
"entries": [
{
"url": "s3:///mybucket/unload_folder/test0000_part_00"
},
{
"url": "s3:///mybucket/unload_folder/test0001_part_00"
},
{
"url": "s3:///mybucket/unload_folder/test0002_part_00"
},
{
"url": "s3:///mybucket/unload_folder/test0003_part_00"
}
],
"status": "success",
"unloadQuery": "UNLOAD ('SELECT * FROM public.company') TO 's3://mybucket/unload_folder/test'
CREDENTIALS 'aws_access_key_id=;aws_secret_access_key=' MANIFEST ESCAPE ALLOWOVERWRITE PARALLEL"
}
]
Upon the successful preview, the expected output data is as follows: [
{
"entries": [
{
"url": "s3:///<bucket>/<folder>/<prefix>000n_part_00"
}
],
"status": "preview",
"unloadQuery": "UNLOAD ('SELECT * FROM public.company') TO 's3://mybucket/unload_folder/test'
CREDENTIALS 'aws_access_key_id=;aws_secret_access_key=' MANIFEST ESCAPE ALLOWOVERWRITE PARALLEL"
}
]
The Snap behaves the same on a Groundplex as it does in a Cloudplex. Expected upstream Snaps: Any Snap with a document output view Expected downstream Snaps: Any Snap with a document input view, such as JSON Formatter, Mapper, and so on. The CSV Formatter Snap cannot be connected directly to this Snap since the output document map data is not flat. This Snap provides a front end to the Amazon Redshift Unload/Copy Utility. The Snap allows data to be efficiently moved from one Redshift instance to an optionally encrypted S3 bucket. The COPY snap moves data from an optionally encrypted S3 bucket into a second Redshift instance. Alternately the data may be downloaded to another system using the S3 READ Snap. By default the data will be written to a separate CSV-encoded compressed file per Redshift 'slice'. It is possible to override this behavior but the resulting file must be smaller than 6.2 GB. The default CSV delimiter is a carat ('^'), not a comma. (Note: elsewhere I've seen the default delimiter listed as a pipe ('|') character.) Input & OutputInput: Key-value map data to evaluate expression properties of the Snap. Input Schema Provided: No Output: This snap produces one document. The fields are:
Output Schema Provided: No Preview Supported: Yes Passthrough Supported: No Output Examples:
| |||||||
| Prerequisites: |
| |||||||
| Limitations and Known Issues: | Works in Ultra Tasks. Loading | |||||||
| Configurations: | Account & AccessThis Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. This Snap requires a Redshift Account with S3 properties. See Configuring Redshift Accounts for information on setting up this type of account. Loading Views:
| |||||||
| Troubleshooting: | The preview on this Snap will not execute the Redshift UNLOAD operation. Connect a JSON Formatter and a File Writer Snaps to the error view and then execute the pipeline. If there is any error, you will be able to preview the output file in the File Writer Snap for the error information. | |||||||
Settings | ||||||||
Label | Required The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||
Select query Required. | Defines a SELECT query. The results of the query are unloaded. In most cases, it is worthwhile to unload data in sorted order by specifying an ORDER BY clause in the query; this approach will save the time required to sort the data when it is reloaded. Example: SELECT * FROM public.company ORDER BY id Default value: SELECT * FROM | |||||||
S3 file prefix | The prefix of AWS S3 file names which are used by Redshift to write data. The Snap uses S3 Bucket and S3 Folder in the RedShift Account to format the full S3 path. File names created by RedShift are in the format: s3://<bucket>/<folder>/<s3-file-prefix><slice-number>_part_<file-number>, where <s3-file-prefix> is the value of this property. The Amazon S3 bucket where Amazon Redshift will write the output files must reside in the same region as your cluster. Example: test Default value: [None] | |||||||
Delimiter | Required. Single ASCII character that is used to separate fields in the output file. DELIMITER will be ignored if FIXEDWIDTH is specified. If the data contains the delimiter character, you will need to specify the ESCAPE option to escape the delimiter, or use ADDQUOTES to enclose the data in double quotes. Alternatively, specify a delimiter that is not contained in the data. Example: a pipe character ( | ), a comma ( , ), or a tab ( \t ) Default value: a pipe character ( | ) | |||||||
Fixed width | Specifies FIXEDWIDTH spec., in which Redshift unloads the data to a file where each column width is a fixed length, rather than separated by a delimiter. The FIXEDWIDTH spec is a string that specifies the number of columns and the width of the columns. DELIMITER is ignored if FIXEDWIDTH is specified. Because FIXEDWIDTH does not truncate data, the specification for each column in the UNLOAD query needs to be at least as long as the length of the longest entry for that column. The format for fixedwidth_spec is: 'colID1:colWidth1,colID2:colWidth2, ...' Example: colID1:36,colID2:36,colID3:256 Default value: [None] | |||||||
Null as | Specifies a string that represents a null value in unload files. If this option is used, all output files contain the specified string in place of any null values found in the selected data. If this option is not specified, null values are unloaded as: Default value: [None] Anaplan server may ignore this setting and try to auto-detect. See Anaplan for details. | |||||||
Escape | If selected, for CHAR and VARCHAR columns in delimited unload files, an escape character (\) is placed before every occurrence of the following characters: Important: If you loaded your data using a COPY with the ESCAPE option, you must also specify the ESCAPE option with your UNLOAD command to generate the reciprocal output file. Similarly, if you UNLOAD using the ESCAPE option, you will need to use ESCAPE when you COPY the same data. Default value: Selected | |||||||
Add quotes | If checked, RedShift places quotation marks around each unloaded data field, so that Amazon Redshift can unload data values that contain the delimiter itself. Default value: Not selected | |||||||
Allow overwrite | By default, UNLOAD fails if it finds files that it would possibly overwrite. If specified, UNLOAD will overwrite existing files, including the manifest file. Default value: Not selected | |||||||
Manifest | Creates a manifest file that explicitly lists the data files that are created by the UNLOAD process. The manifest is a text file in JSON format that lists the URL of each file that was written to Amazon S3. The manifest file is written to the same Amazon S3 path prefix as the unload files in the format <s3_path_prefix>manifest. For example, if the unload file S3 path prefix is 's3://mybucket/myfolder/venue_', the manifest file location will be 's3://mybucket/myfolder/venue_manifest'. Since this Snap needs to read the content of the manifest file for the output document data, it always includes MANIFEST option in the query. After reading the content of the manifest file, the Snap deletes the manifest file if this property is un-selected. Default value: Not selected | |||||||
Parallel | By default, UNLOAD writes data in parallel to multiple files, according to the number of slices in the cluster. If unchecked, UNLOAD writes to one or more data files serially, sorted absolutely according to the ORDER BY clause, if one is used. The maximum size for a data file is 6.2 GB. Therefore, if the unload data is larger than 6.2 GB, UNLOAD will create more than one file. The UNLOAD command is designed to use parallel processing. We recommend leaving this property selected for most cases. Default value: Selected | |||||||
Gzip | Unloads data to one or more gzip-compressed file per slice. Each resulting file is appended with a .gz extension. Default value: Not selected | |||||||
Client-side Encryption | Specifies the Amazon S3 client-side encryption type for the output files on Amazon S3. UNLOAD by default creates encrypted files using Amazon S3 server-side encryption with AWS-managed encryption keys (SSE). UNLOAD does not support Amazon S3 server-side encryption with a customer-supplied key (SSE-C). To unload to encrypted gzip-compressed files, check the GZIP property. If selected, provide the customer master key in the Master symmetric key property. Default value: Not selected | |||||||
IAM role | Check this property if the bulk load/unload has to be done using IAM role. If checked, ensure the properties (AWS account ID, role name and region name) are provided in the account. Default value: [None] | |||||||
| KMS Encryption type | Specifies the type of KMS S3 encryption to be used on the data. The available encryption options are:
Default value: None If both the KMS and Client-side encryption types are selected, the Snap gives precedence to the SSE, and displays an error prompting the user to select either of the options only. | |||||||
| Master symmetric key | Conditional. This property applies only when the Client-side Encryption property is selected. This is the customer master key for the data to be encrypted client side. For more information about this please refer to Customer Master Keys and Using Client Side Encryption. Default value: [None] | |||||||
KMS key | Specifies the AWS Key Management Service (KMS) key ID or ARN to be used for the S3 encryption. This is only required if the KMS Encryption type property is configured to use the encryption with KMS. For more information about the KMS key refer to AWS KMS Overview and Using Server Side Encryption. Default value: [None] | |||||||
Snap Execution Default Value: Validate & Execute | Select an option to specify how the Snap must be executed. Available options are:
| |||||||
Troubleshooting
Error | Reason | Resolution |
|---|---|---|
| This issue occurs due to incompatibilities with the recent upgrade in the Postgres JDBC drivers. | Download the latest 4.1 Amazon Redshift driver here and use this driver in your Redshift Account configuration and retry running the Pipeline. |
Example
Transferring data from one Redshift instance to another
The Redshift Unload and Redshift Copy Snaps can be used to transfer data from one Redshift instance to a second.

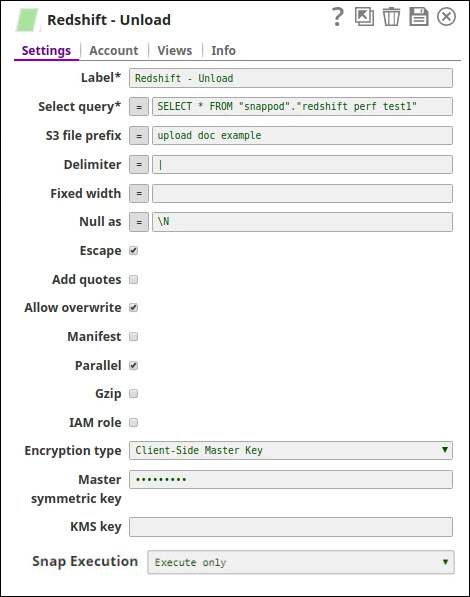
Sample Unload snap settings
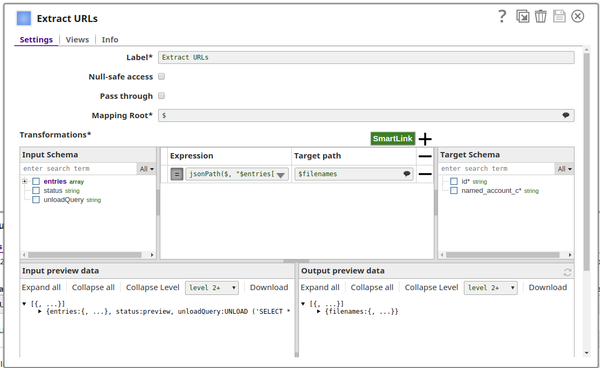
The first mapper extracts the URL elements
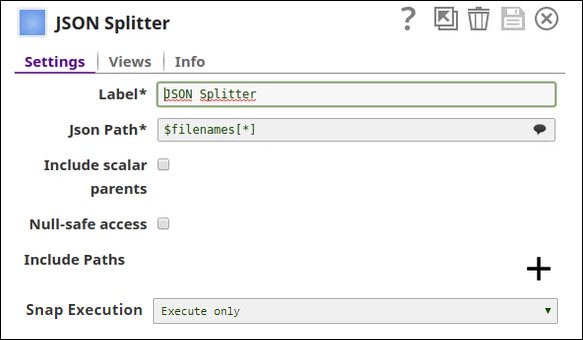
The splitter breaks the string array of URLs into a series of documents.
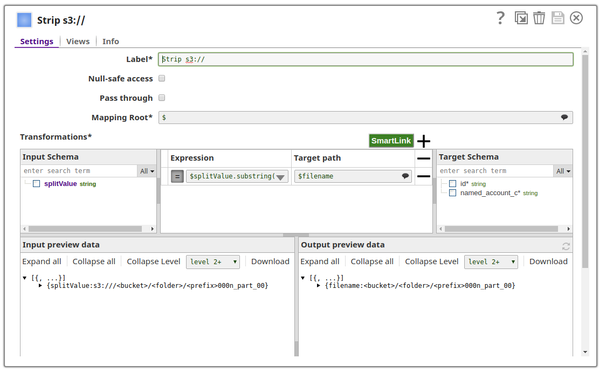
The second mapper strips the leading "s3:///" from the URLs.
The S3 Upsert Snap uses an expression property for the filename.
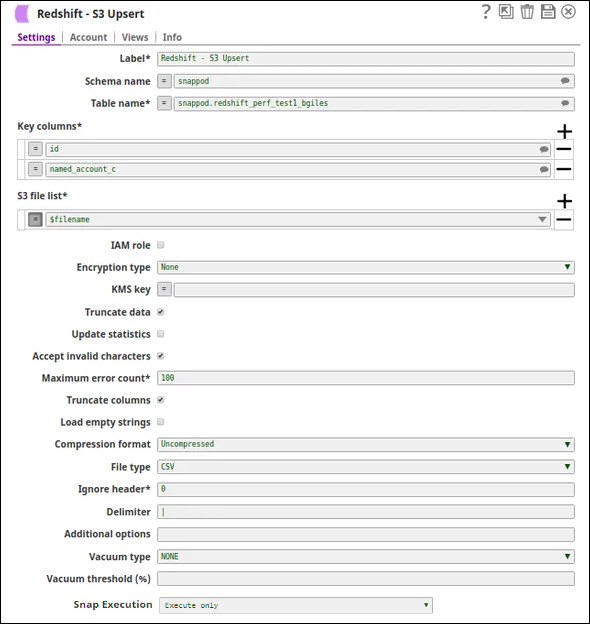
The output of the Upsert Snap shows the results.
The key points are that
- The S3 file list must include the 'slice' information, e.g., '0000_part_00'. There will be one file per slice.
- The Unload Snap will always write to the S3 bucket associated with the Redshift account. The Upsert Snap's S3 file list must include the S3 bucket name.
- The destination table must be created beforehand. There is no auto-creation mode.
- The null substitution is not recognized by the upsert. It must be updated manually. This could cause problems with uniqueness constraints.
Exported pipeline is available in the Downloads section below.
This Snap will leave the data file on the S3 instance.
Downloads
Snap Pack History
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.