Redshift - Insert
- Kalpana Malladi
- Aparna Tayi (Unlicensed)
- Cindy Hall (Unlicensed)
On this Page
Snap Type: | Write | |||||||
|---|---|---|---|---|---|---|---|---|
Description: | This Snap executes a SQL INSERT statement using the document's keys as the columns to insert to and the document's values as the values to insert into the columns. According to Amazon's Redshift documentation, Amazon strongly recommends using the BULK insert functionality, advising against using the INSERT statement. The Redshift - Insert Snap will use the batch INSERT methodology suggested, but the performance of Redshift in executing might be, as Amazon advises, prohibitively. SnapLogic has created the Redshift - Bulk Load Snap to address this issue, automating the use of the advised BULK insert using the COPY command. Refer to the Redshift - Bulk Load Snap for more information. ETL Transformations & Data FlowThe Snap receives data from upstream component and loads the data into the selected table in the Redshift DB. Input & Output
| |||||||
Prerequisites: | None. | |||||||
Limitations and Known Issues: | Works in Ultra Pipelines if batch size is set to 1 in the Redshift account. Loading | |||||||
| Configurations: | N/A | |||||||
| Views: | Account and AccessThis Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Redshift Account for information on setting up this type of account. Views
| |||||||
| Troubleshooting: | Error Message: "Cannot find an input data which is related to the output record ....." This error occurs when the data types in the input document do not match the column types in the database table. Ensure that the input data types match the column types in the database table. | |||||||
Settings | ||||||||
Label* | Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||
Schema name | Specify the database schema name. Selecting a schema filters the Table name list to show only those tables within the selected schema. The property is suggestible and will retrieve available database schemas during suggest values. The values can be passed using the pipeline parameters but not the upstream parameter. Default value: None | |||||||
| Table name* | Specify the name of the table to execute an insert query on. The values can be passed using the pipeline parameters but not the upstream parameter. Default value: None | |||||||
Create table if not present | Loading Default value: Not selected | |||||||
| Preserve case sensitivity | ||||||||
| Number of retries | Specify the maximum number of attempts to be made to receive a response. The request is terminated if the attempts do not result in a response. If the value is larger than 0, the Snap first downloads the target file into a temporary local file. If any error occurs during the download, the Snap waits for the time specified in the Retry interval and attempts to download the file again from the beginning. When the download is successful, the Snap streams the data from the temporary file to the downstream Pipeline. All temporary local files are deleted when they are no longer needed. Default value: 0 | |||||||
| Retry interval (seconds) | Specifies the time interval between two successive retry requests. A retry happens only when the previous attempt resulted in an exception. Default value: 1 | |||||||
Execute during preview | This property enables you to execute the Snap during the Save operation so that the output view can produce the preview data. Default value: Not selected | |||||||
Table Creation
If the table does not exist when the Snap tries to do the insert, and the Create table if not present property is selected, the table will be created with the columns and data types required to hold the values in the first input document. If you would like the table to be created with the same schema as a source table, you can connect the second output view of a Select Snap to the second input view of this Snap. The extra view in the Select and Bulk Load Snaps are used to pass metadata about the table, effectively allowing you to replicate a table from one database to another.
The table metadata document that is read in by the second input view contains a dump of the JDBC DatabaseMetaData class. The document can be manipulated to affect the CREATE TABLE statement that is generated by this Snap. For example, to rename the name column to full_name, you can use a Mapper Snap that sets the path $.columns.name.COLUMN_NAME to full_name. The document contains the following fields:
columns - Contains the result of the getColumns() method with each column as a separate field in the object. Changing the COLUMN_NAME value will change the name of the column in the created table. Note that if you change a column name, you do not need to change the name of the field in the row input documents. The Snap will automatically translate from the original name to the new name. For example, when changing from name to full_name, the name field in the input document will be put into the "full_name" column. You can also drop a column by setting the COLUMN_NAME value to null or the empty string. The other fields of interest in the column definition are:
TYPE_NAME - The type to use for the column. If this type is not known to the database, the DATA_TYPE field will be used as a fallback. If you want to explicitly set a type for a column, set the DATA_TYPE field.
_SL_PRECISION - Contains the result of the getPrecision() method. This field is used along with the _SL_SCALE field for setting the precision and scale of a DECIMAL or NUMERIC field.
_SL_SCALE - Contains the result of the getScale() method. This field is used along with the _SL_PRECISION field for setting the precision and scale of a DECIMAL or NUMERIC field.
primaryKeyColumns - Contains the result of the getPrimaryKeys() method with each column as a separate field in the object.
declaration - Contains the result of the getTables() method for this table. The values in this object are just informational at the moment. The target table name is taken from the Snap property.
importedKeys - Contains the foreign key information from the getImportedKeys() method. The generatedCREATE TABLE statement will include FOREIGN KEY constraints based on the contents of this object. Note that you will need to change the PKTABLE_NAME value if you changed the name of the referenced table when replicating it.
indexInfo - Contains the result of the getIndexInfo() method for this table with each index as a separated field in the object. Any UNIQUE indexes in here will be included in the CREATE TABLE statement generated by this Snap.
- The Primary key is not enforced in RedShift, therefore it will allow duplicated records inserted with the same primary key. In fact, uniqueness, primary key, and foreign key constraints are informational only in Amazon RedShift. For more information, refer to: http://docs.aws.amazon.com/redshift/latest/dg/t_Defining_constraints.html
- The Snap will not automatically fix some errors encountered during table creation since they may require user intervention to resolve correctly. For example, if the source table contains a column with a type that does not have a direct mapping in the target database, the Snap will fail to execute. You will then need to add a Mapper (Data) Snap to change the metadata document to explicitly set the values needed to produce a valid CREATE TABLE statement.
Troubleshooting
Examples
Basic Use Cases
Use Case #1
This Use Case Pipeline demonstrates how to insert input data into a table along with the table's structure
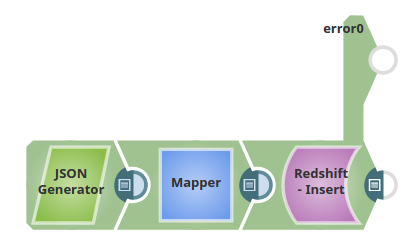
In this use case we will insert a collection of records into a table "SNAPPOD"."EMPLOYEE_DATA" which is defined as below: (Where SNAPPOD is the schema name and EMPLOYEE_DATA is the name of the table).
CREATE TABLE "SNAPPOD"."EMPLOYEE_DATA"
(
"employee_code" integer,
"employee_name" varchar(50),
"job" char(20),
"salary" float,
"department_code" integer
);
The input data will be provided from an upstream Snap, in this example JSON Generator is used which contains the data as below:
[
{ "empno": 101, "ename": "John", "job": "Manager", "sal": 144000, "deptno": 10 },
{ "empno": 102, "ename": "Thomas", "job": "Marketing ", "sal": 84000, "deptno": 20 },
{ "empno": 103, "ename": "Williams", "job": "Technical", "sal": 96000, "deptno": 30 },
{ "empno": 104, "ename": "Scott", "job": "Sales", "sal": 84000, "deptno": 20 },
{ "empno": 105, "ename": "Richard", "job": "Accounts", "sal": 72000, "deptno": 40 },
{ "empno": 106, "ename": "James", "job": "Sales", "sal": 84000, "deptno": 20 }
]
Use Case #2
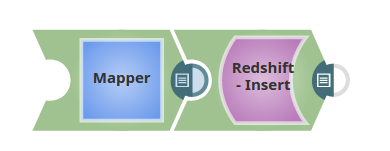
The pipeline below shows a typical scenario where data from a Mapper Snap is passed to the Redshift Insert Snap.
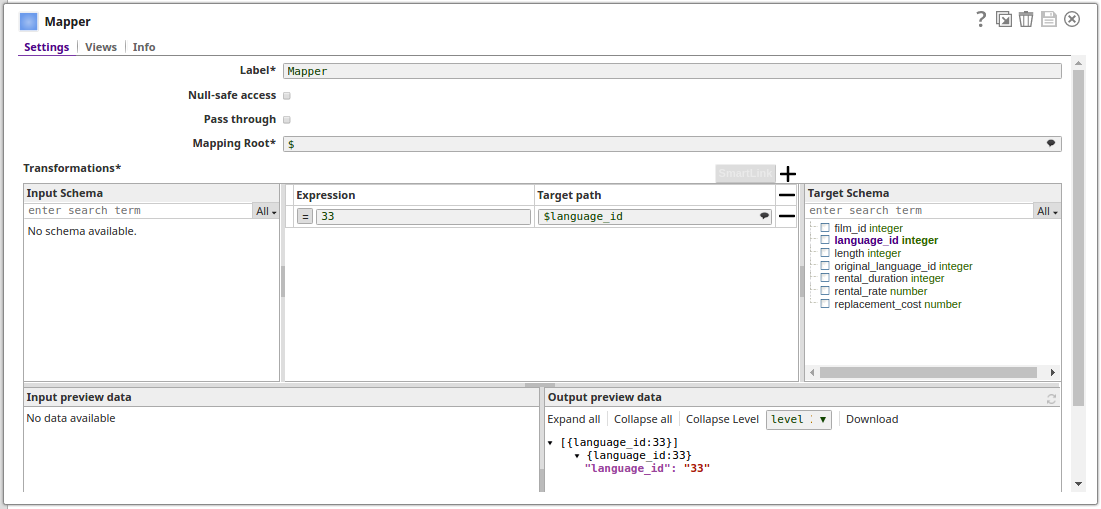
The configuration of the Mapper Snap:
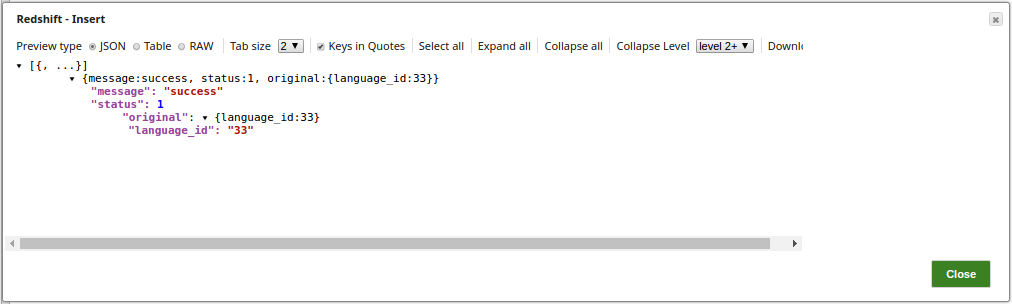
Preview of the successful execution of the Redshift Insert Snap:
Typical Snap Configurations
Key configuration of the Snap lies in how you pass the SQL statements to insert the records. The statements can be passed:
- Without Expressions
The values are passed directly into the Snap.
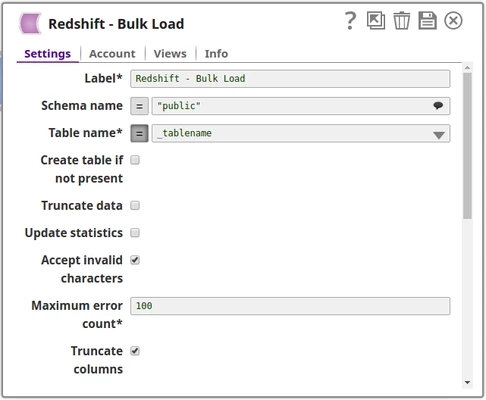
- With Expressions
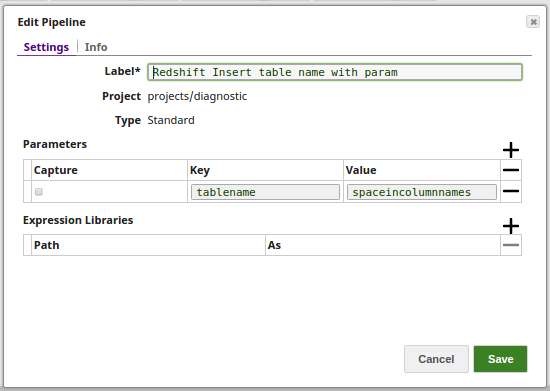
- Pipeline Parameters
The Table Name is passed as a pipeline parameter.
- Pipeline Parameters
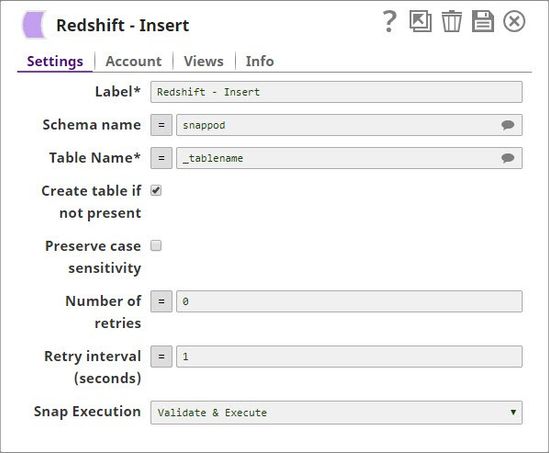
Advanced Use Case
The following describes a pipeline that shows how typically in an enterprise environment, an insert functionality is used. Pipeline download link in the Downloads section below.
In this example we will insert a collection of records into a table "snappod"."EMPLOYEE_DATA" and the Snap also creates the table if it is not existing.
The snap will use two input views, the first input view is to receive data from the upstream Snap and insert the data into the destination table. The second input view receives the structure of the table along with table constraints and creates the table in Redshift DB if the table is not existing.
Pipeline:
Oracle Select Snap: This Snap will have two output streams,
Output view rows: Selects the data from the given table and writes the records to this output view.
Output view output1: Writes the structure of the table along with the column constraints such as primary key, not null, and so on.
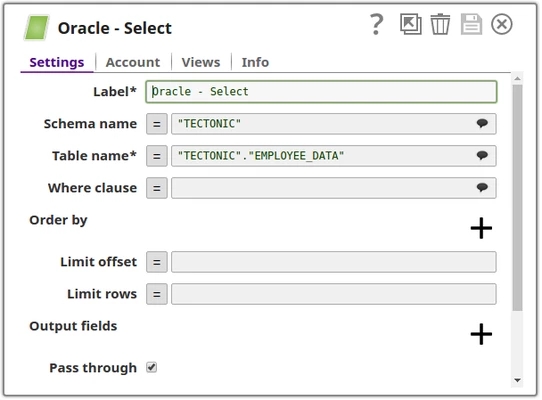
Output View 'output1' (contains table structure)
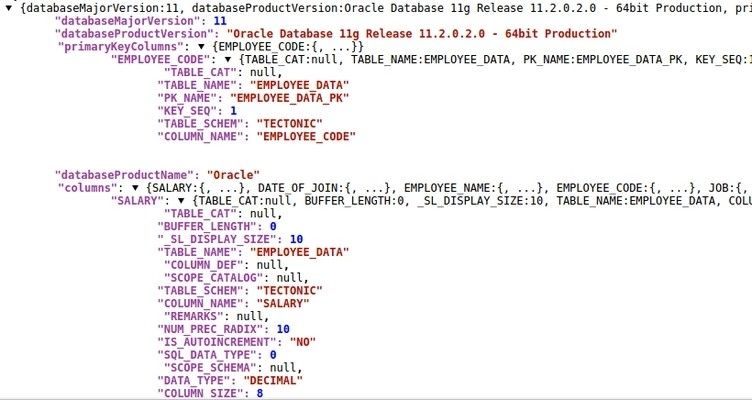
Output View 'rows' (contains input data)
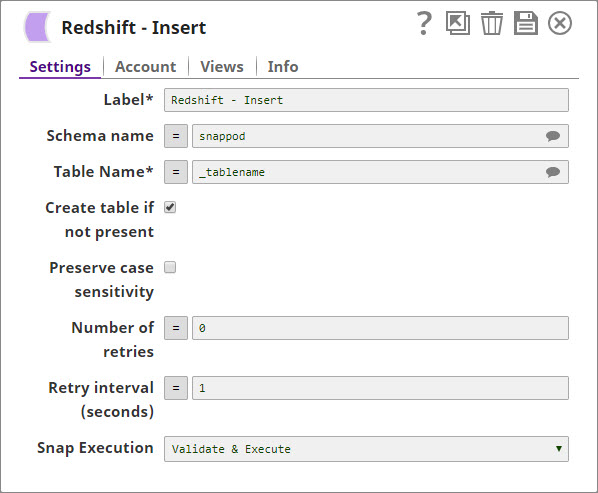
Redshift Insert Snap:
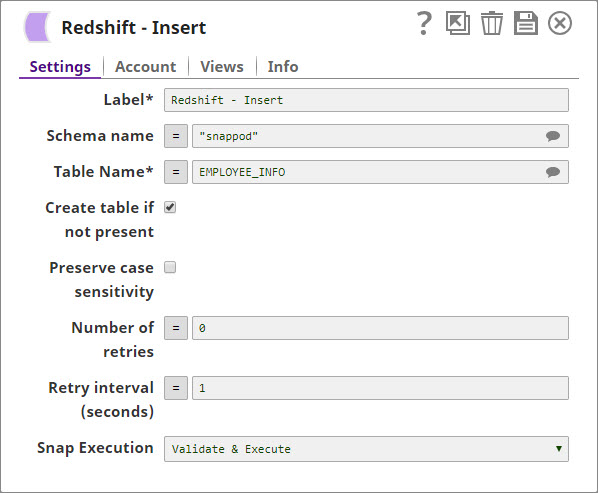
Contains two input views
Input view 'input1': To receive the table structure and to create the table in Redshift if it is not existing. (The user needs to enable the 'create table if not existing' property)
Input view 'rows': To receive input data from the upstream Snap and to insert them into the selected table on Redshift.
Downloads
Related Links
Snap Pack History
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.