Pipeline: Replicate a Database Schema in Redshift
In this Page
Scenario
I want to replicate one or more tables from a source database in RedShift.
Requirements
Snaps Used
For this scenario, the following Snaps are used:
- a DB Select Snap, such as MySQL Select
- a Redshift Insert/Bulk Load Snap
Configuration
Replicating a table is done using the Select and Insert/Bulk Load Snaps. The rows are sent out the main output view and then a second output view is used to pass the schema. Here are the steps to follow to build the pipeline:
- Add a DB Select Snap, such as MySQL Select.
- Add a second output view to the Select Snap.
- Add a Redshift Insert/Bulk Load Snap.
- Add a second input view to the Redshift Snap.
- Connect the views together.
- Configure the Select Snap to read from a table.
- Configure the table name in the Redshift Snap and set it to create the table.
To replicate multiple tables, you can use the Redshift Table List Snap to get the list of tables for a schema. You can then use a ForEach Snap to run the above pipeline using the table name as the parameter.
The DB Select Snaps support a second output view that is used to send out the database schema. The database schema is basically the dump of the JDBC metadata returned by the getTables(), getColumns(), getIndexInfo(), and getImportedKeys() methods. You can read more about these methods at: http://docs.oracle.com/javase/7/docs/api/java/sql/DatabaseMetaData.html
The Redshift Insert and Bulk Load Snaps also support two input views. One view accepts the rows to insert into a table and the other accepts the JDBC metadata dump generated by the second output view of a DB Select Snap. You can do a trivial table replication by creating a pipeline with a Select and a Redshift Insert Snap and connecting the views together, like so:
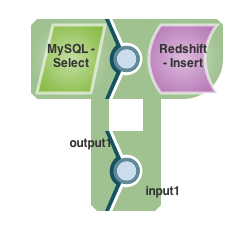
If you want to change the schema that will be generated in Redshift, you can manipulate the JDBC metadata sent out the second output view of the Select Snap. For example, you can change the name of a "foobar" column by inserting a Mapper (Data) Snap between the second views of the Select and Insert. Then, configure the Mapper (Data) Snap to assign the path $.columns.foobar.COLUMN_NAME a new name, like "baz". So, it would look something like this:
"baz" $.columns.foobar.COLUMN_NAME
Note that you don't need to change the rows that are flowing into the Insert Snap when you do this, it will automatically know to map the "foobar" field in the incoming documents to the "baz" column in the database.
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.