On this Page
...
| Pipeline | Description |
|---|---|
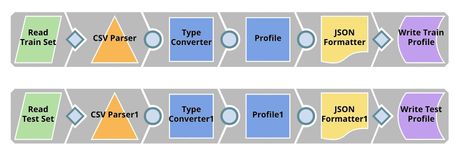
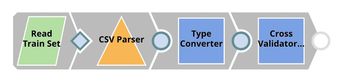
| Profiling. This pipeline reads the training set and test set from GitHub, performs type conversion, and computes data statistics which is saved to SnapLogic File System (SLFS) in a JSON format. |
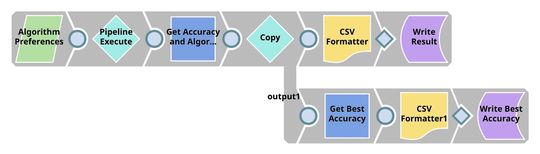
| Cross Validation. We have 2 pipelines in this step. The first pipeline (child pipeline) performs k-fold cross validation using a specific ML algorithm. The second pipeline (parent pipeline) uses Pipeline Execute Snap to automate the process of performing k-fold cross validation on multiple algorithms. The Pipeline Execute Snap spawns and executes child pipeline multiple times with different algorithms. Instances of child pipeline can be executed sequentially or in parallel to speed up the process by taking advantage of multi-core processor. The Aggregate Snap applies max function to find the algorithm with the best result. |
| |
| Model Building. Based on the cross validation result, there is no best algorithm on this dataset. Most of them perform at the same level. Trainer (Classification) Snap trains Random Forests model which is formatted to JSON and compressed. The compressed JSON is written to SLFS. |
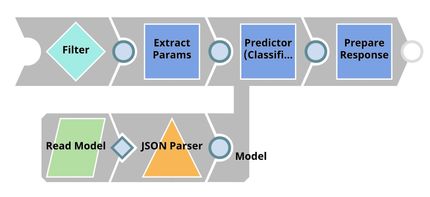
| Model Hosting. This pipeline is scheduled as an Ultra Task to provide REST API to external applications. The request comes into an open input view. The core Snap in this pipeline is Predictor (Classification) which hosts the ML model from JSON Parser Snap. Filter Snap drops the requests with an invalid token. Extract Params (Mapper) Snap extracts input from the request. See more information here. |
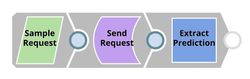
| API Testing. JSON Generator Snap contains a sample request including token and text. REST Post Snap sends a request to the Ultra Task (API). Mapper Snap extracts prediction from the response body. See more information here. |
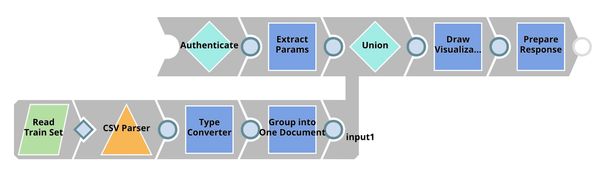
| Visualization API. This pipeline is scheduled as an Ultra Task to provide REST API to external applications. Remote Python Script Snap stores the dataset (from the bottom flow) in memory and generates visualization for each of the incoming requests request from the top flow. Filter Snap drops the requests with an invalid token. Extract Params (Mapper) Snap extracts input from the request. See more information here. |
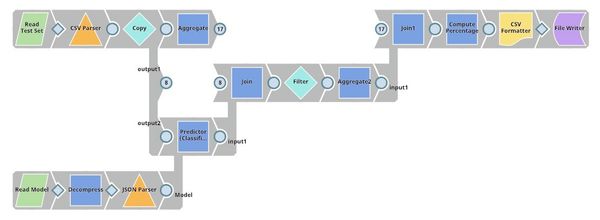
| Profit Analysis. This pipeline uses the trained model to predict the charged-off rate of loans in the test set. The Filter Snap rejects some of the loans based on the confidence level. The Aggregate Snaps compute statistics (before and after applying the ML model) including the number of approved loans, total fund, total profit, and average profit per loan. Finally, Mapper Snap computes the percentage of improvement. |

...
| Expand | ||
|---|---|---|
| ||
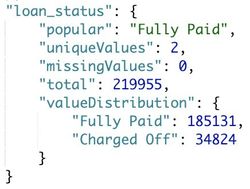
The output contains data statistics of this dataset. The following images show the profile of $addr_state and $loan_status in the training set. As you can see, California state has the most loans.
There are 185131 (84.17%) fully paid loans and 34824 (15.83%) charged-off loans.
|

Cross Validation
...
Model Hosting
Follow the instructions here to schedule this pipeline as REST API.
...
You can find more information about API testing here.
JSON Generator
This Snap contains a sample request which is sent to the API by the REST Post Snap.
...
This Snap loads the dataset from the Group By N Snap into the memory and gives a visualization based on the incoming requests from the Extract Params (Mapper) Snap. We use bokeh to draw visualization. In order to To use Remote Python Script Snap, you must have Remote Python Executor installed on the Snaplex.
...
This section includes the profit analysis in multiple cases: without ML, decision tree, logistic regression, naive bayes, decision stump, random forests, and AutoML.
Without ML
The table below shows the statistics of the loans in the test set before applying the ML model.
...