In this article
Overview
You can use this Snap to read a document at the input, format it as CSV based on the specified parameters, and write CSV data to the output.
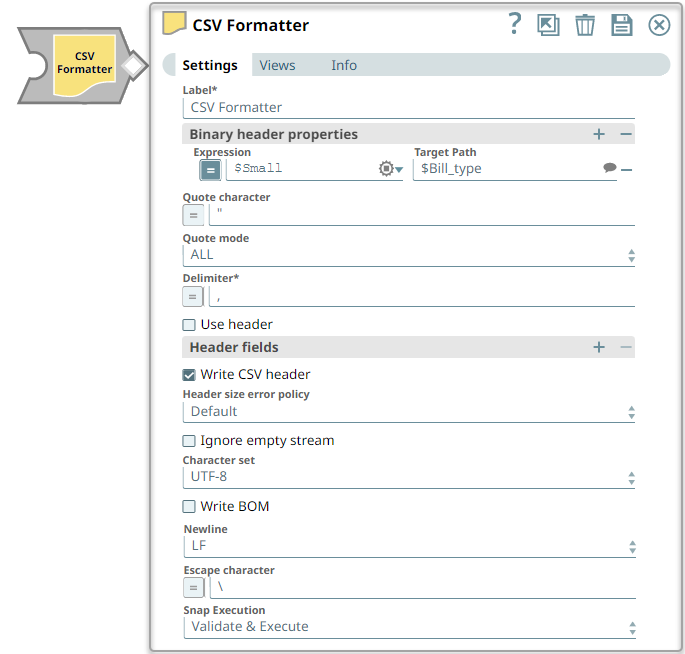
Snap Type
CSV Formatter Snap is a READ-type Snap that reads a document that contains data structured as key-value attributes and generates CSV data formatted using specifications provided in the Snap's settings.
Prerequisites
None.
Support for Ultra Pipelines
Does not work in Ultra Pipelines.
Limitations and Known Issues
The Snap ignores escape characters when used along with any quote characters. When this happens, the resultant data cannot be parsed correctly using CSV Parser Snap which can cause an error. See Apache CSV Format Issue for details.
The Snap prepares the column header for the output view (and hence the CSV file) using the keys defined in the first record. This may result in ignoring any additional key passed in the subsequent records. We recommend that you pass values for a comprehensive set of all keys used in the input view, for the first record.
Snap Views
Type | Format | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input | Document |
|
| Any document that contains data structured as key-value attributes. |
Output | Document |
|
| CSV data formatted using specifications provided in the Snap's settings. |
Error | Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter while running the Pipeline by choosing one of the following options from the When errors occur list under the Views tab. The available options are:
Learn more about Error handling in Pipelines. | |||
Snap Settings
Asterisk (*): Indicates a mandatory field.
Suggestion icon (
 ): Indicates a list that is dynamically populated based on the configuration.
): Indicates a list that is dynamically populated based on the configuration.Expression icon (
): Indicates whether the value is an expression (if enabled) or a static value (if disabled). Learn more about Using Expressions in SnapLogic.Add icon (
): Indicates that you can add fields in the field set.Remove icon (
): Indicates that you can remove fields from the field set.
Field Name | Field Type | Description | |
|---|---|---|---|
Label* Default Value: CSV Formatter | String | Specify a unique name for the Snap. | |
Binary header properties | Use this fieldset to add binary-header properties to the output data. These properties contain data related information that enables the system to interpret data. Binary headers in a document can be accessed and used in the expression-enabled properties of downstream Snaps. For example, you can use binary headers to specify custom statuses associated with the output data. Similarly, a 'content-location' property added to the binary header in this Snap can be referenced in the File name property of a File Writer Snap with the expression: $['content-location']. | ||
Expression Default value: N/A | String | Specify the value to be associated with a specific binary header property. | |
Field 2 Default Value: N/A | String | Specify the target JSON path where the value in the expression is written. | |
Quote character Default value: “ | String | The character that you want to use as the escape character in the CSV document. For example, if you use double quotes (") as the escape character, then commas in the actual data will need to be escaped using double-quotes on both sides. This property can be an expression. However, if the value associated with the expression contains more than one character, only the first character is used as the quote character. | |
Quote mode Default value: ALL | Dropdown list | Select an option to specify how the quote character should be used in formatting the CSV data. Available options are:
If the Quote character property is empty, the selection of this property is ignored and the Snap uses NONE for the Quote mode. | |
Delimiter Default value: , | String/Expression | Specify the string or the character that must be used as a delimiter in formatting the CSV data. Tabs are common delimiters. To use a tab as the delimiter, enter \t.
| |
Use header Default value: Deselected | Checkbox | Select this checkbox to indicate whether the column names in the Header fields property should be used to format the CSV data. If this checkbox is deselected, the key set of the first document data is used as a CSV header. Ensure that the CSV document header contains non-empty values for all columns. | |
Header fields Default value: N/A | String | Specify the header values that you want to use in the output CSV data. | |
Write CSV header Default value: Selected | Checkbox | Select this checkbox to indicate whether the header strings listed in the Header fields properties should be written to the output CSV data. Default value: Selected. | |
Header size error policy Default value: Default | Dropdown list | Select an option to handle any header size errors.
The header size error condition occurs when any subsequent input document has additional column names which are not present in the header. To handle header size errors, you can select any of the following options:
| |
Ignore empty stream Default value: Deselected | Checkbox | Select this checkbox to indicate whether you want the Snap to ignore empty streams received at the input view during Pipeline execution. If this option is selected, the Snap does not produce any output stream; else, the Snap writes an empty array to the output stream. | |
Character set Default value: UFT-8 | Dropdown list | Select the character set in which the input CSV data is encoded. The available options are:
| |
Write BOM Default value: Deselected | Checkbox | Select this checkbox to indicate the behavior of the Snap when it starts to write the CSV output data. If this option is selected, the Snap writes the BOM (Byte Order Mark) for the character set selected in the Character-set encoding property; else, the Snap skips writing BOM. | |
Newline Default value: LF | Dropdown list | Select an option to specify the newline characters that you want to use as a line break. The available options are: LF, CR+LF and CR. | |
Escape character Default value: \ | String | Specify the escape character that is to be used when formatting rows. Only single characters are supported. As of 4.3.2, this property can be an expression, which is evaluated with the values from the pipeline parameters. Leave this property empty if no escape character is used in the input CSV data. | |
Snap Execution Default Value: Validate & Execute | Dropdown list | Select one of the three modes in which the Snap executes. Available options are:
| |
Examples
Specifying Line Feeds for Windows while Formatting Documents
Text files created on Windows have different line endings than files created on Linux. Windows uses the carriage return and line feed ("\r\n") as a line ending, while Linux uses just a line feed ("\n").
In this example, we create a Pipeline that reads CSV data and then formats it for Windows-style line feeds using the CSV Formatter Snap.

Download this Pipeline.
Use the CSV Generator Snap to supply CSV documents:
The raw output from the CSV Formatter Snap is as follows:

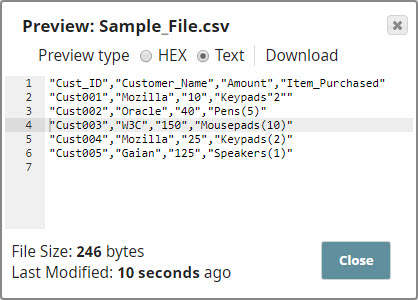
Notice how the double-quotes used in the first line of the input CSV data is escaped in the output document.
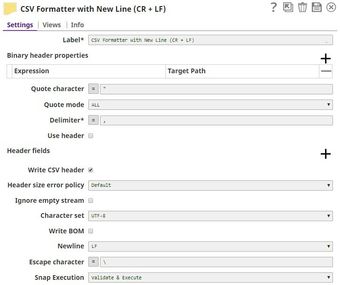
The CSV Formatter Snap formats the input data and produces an output in the line feeds for Windows style. We selected the Newline Property with CR+LF to give the line feeds in Windows format. We also leave the Quote character field unchanged as '"'. This tells the Snap that all special characters have to be placed in quotes in the CSV output.
The Newline property enables you to create output that works with the line feeds for Windows. Unless specified, the Snap's output defaults to Linux.
Use the File Writer Snap to create a file using the output. Successful execution of the Pipeline displays the following output:
Creating Filenames Using the CSV Formatter Snap
In this example, pick up CSV documents that contain details related to simple purchases and, depending on the value of the purchases, we route them into two documents, picking up their names using the output of the CSV Formatter Snap.
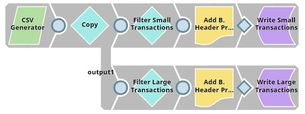
Download this Pipeline.
For the purposes of this example, we are picking up CSV data from a CSV Generator Snap. You can also supply this data using a combination of File Reader and CSV Parser Snaps.
The CSV Generator Snap contains transaction details, as shown below:
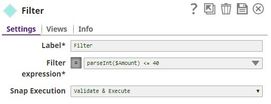
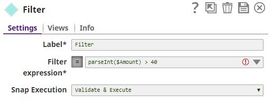
We copy the output of the CSV Generator Snap and connect each copy to a Filter Snap, where we filter out transactions based on whether they are worth more or less than $40:
We now add a 'Bill_Type' binary header property to each set of filtered outputs, so each document is tagged appropriately:
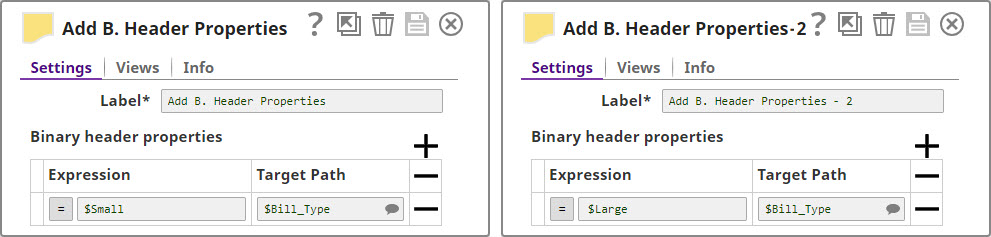
We now have two records, one containing all transactions that are worth less than or equal to $40, and another containing all transactions over $40. We now write each of these files to the SLDB using the File Writer Snap, configuring it to include this classification of transactions in the filename. We do this by using the expression $Bill_Type+".csv" in the File name property.
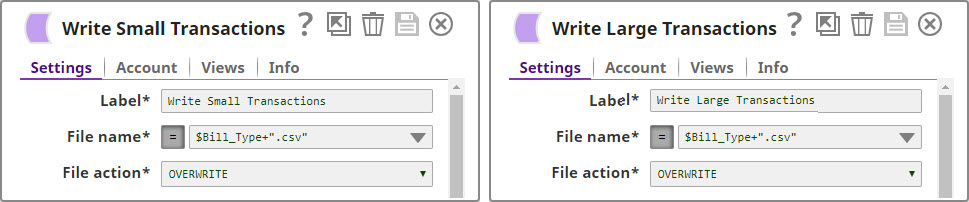
You can now see that two new files were created in the project: $Small.csv and $Large.csv:
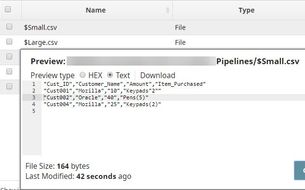
Download this Pipeline.
Passing Execution Status Codes through Binary Header Properties of the CSV Formatter Snap
In this example, we shall send CSV data from ServiceNow into SnapLogic using a Triggered Task. We shall then see how you can use the CSV Formatter Snap in the triggered Pipeline to manipulate the execution status (error) codes generated during Pipeline execution.
Download this Pipeline.
For the example to work, the Pipeline triggered by the Task should lead to an error. We shall route the error output to an error view. We shall then use the error view to manipulate the Status header of the error document. Once this is done, the parent Task sends the updated error output back to ServiceNow, and we should see the updated status code in the ServiceNow Administration interface.
We need to perform the following tasks:
Create a Pipeline that accepts CSV data, generates an error, and manipulates the error data to update the status code.
Create a Triggered Task that can trigger the Pipeline created in Step 1.
Configure ServiceNow to send and receive CSV data from the Triggered Task created in Step 2.
Let us look at each of these tasks in some detail:
Creating a Pipeline to accept CSV and manipulate error document data
This Pipeline is structured as shown in the screenshot above. Let us now look at its constituents:
Snap Name | Snap Type | Task Description | Settings (Click to expand screenshot) |
|---|---|---|---|
Parse Data | CSV Parser | Parses streaming data from the parent Triggered Task. | 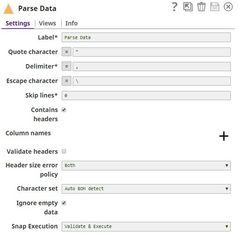 |
Enter Faulty Mappings | Mapper | Creates problematic mappings to trigger an error in the downstream Snap. | 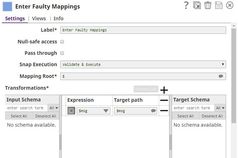 |
Change Status Codes | Mapper | Manipulates (or changes) the status code in the input document containing the error view from the Enter Faulty Mappings (Mapper) Snap. In this example, we choose to update the status code to 603. | 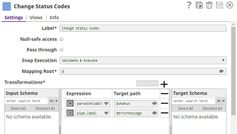 |
Update Headers | CSV Formatter | Adds the updated status code into the binary header of the output CSV document to be sent to ServiceNow. | 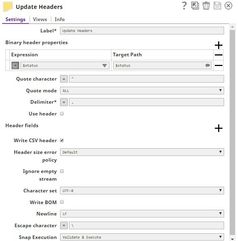 |
Creating a Triggered Task that sends CSV data into the TriggeredTask_CSVFormatter_Example Pipeline
To create a Triggered Task:
Click the Create Task icon at the SnapLogic Designer toolbar. This displays the Create Task popup. Configure the Task as shown below:
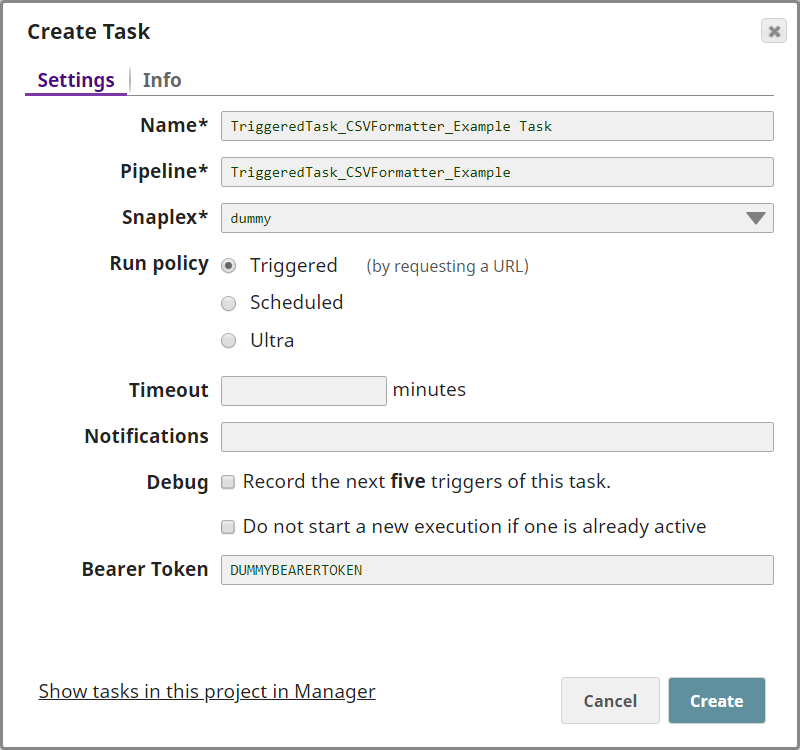
Your Task is now configured. You now need to configure your ServiceNow account to send CSV data to this Task.
Configuring ServiceNow to send and receive CSV data from the Triggered Task
This step can only work if you have a ServiceNow account.
To configure ServiceNow to send and receive CSV data from the Triggered Task created in Step 2:
Log into your ServiceNow account and open the pane on the left of the page.
Search for the string outbound in the Filter field displayed in the top-left section of the page. From the filtered list of options displayed, click REST Messages under the System Web Services section.
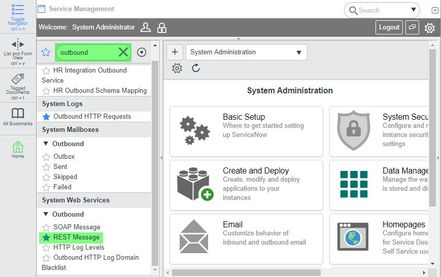
This displays the REST Messages page.Click New to create a new REST message and configure the message as shown below:
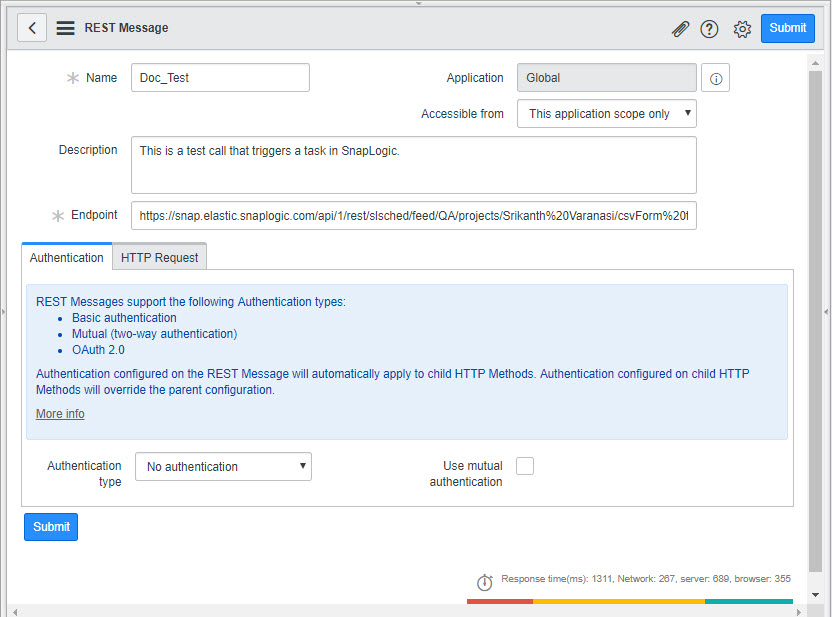
Click Submit to save your changes. This creates the REST call. You now need to configure the call with the data you want to send. To do so, click the REST call. This displays the details of the REST call.
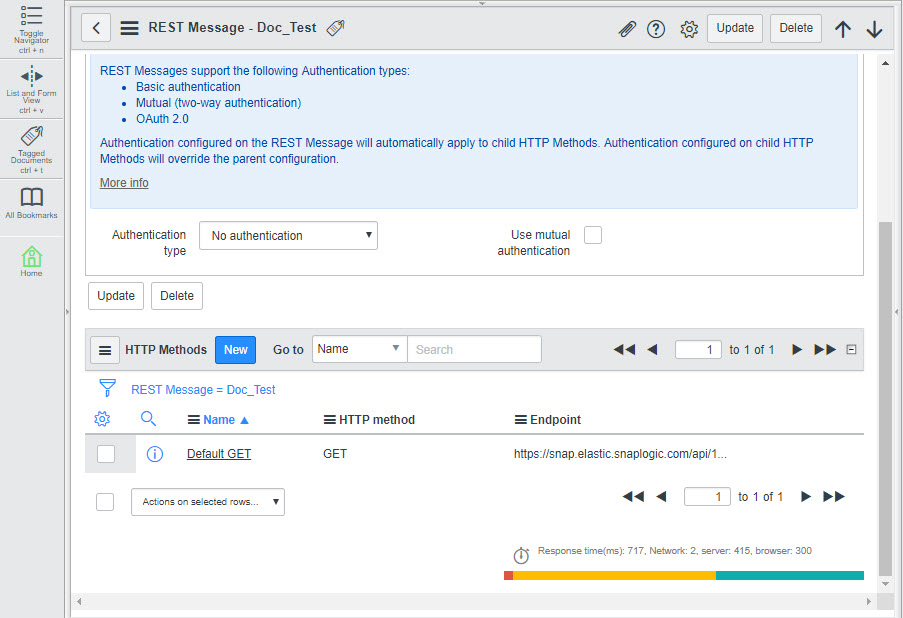
Scroll down to the HTTP Methods section and click on the Default Get method created automatically for the call. This displays the call's details:
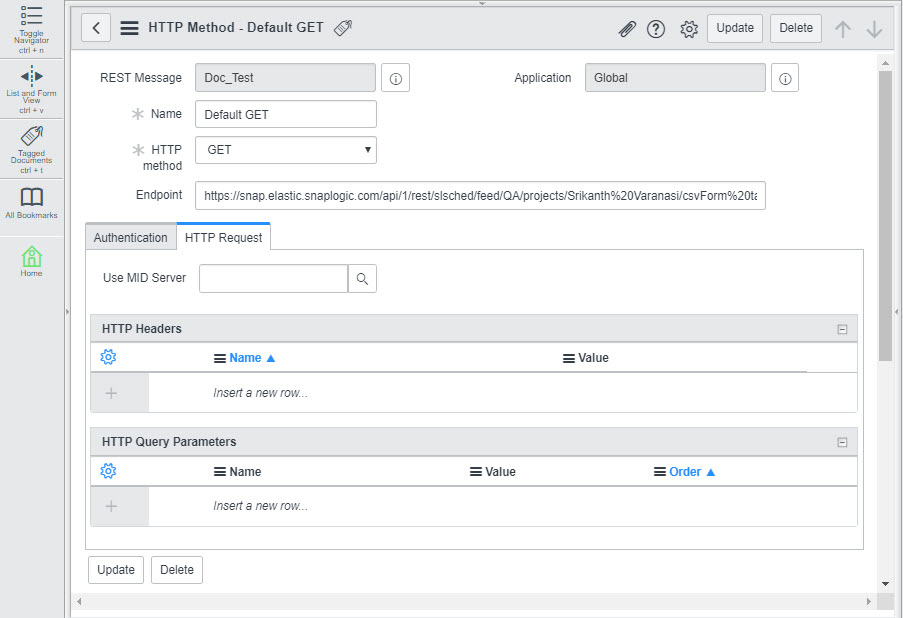
You need to send a POST call to the Task, so that you can provide the content that must be processed as a result of the call. To do so, click the HTTP Method field and, from the drop-down list displayed, select POST. Once you make this selection, the Content field appears at the bottom of the page.
Enter the content you want to use for the call:
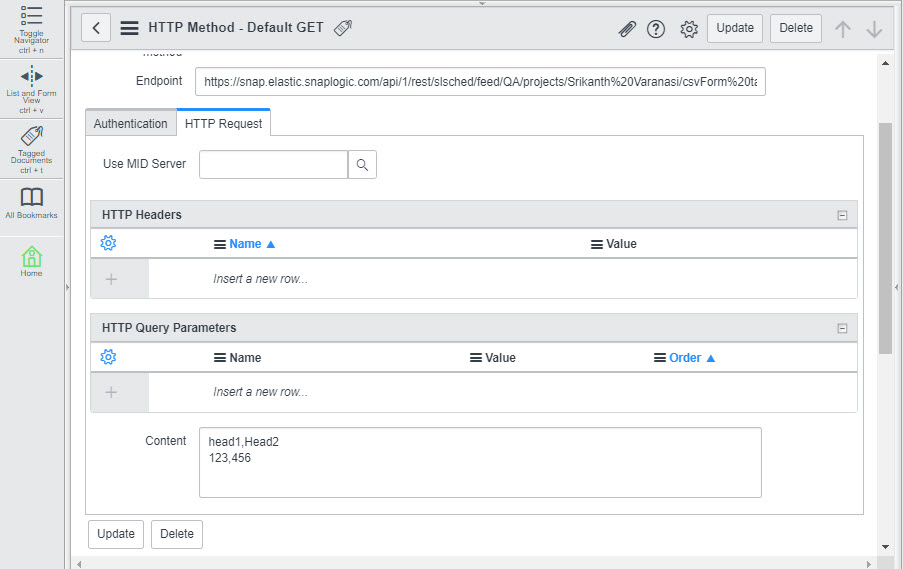
Click Test. This triggers the SnapLogic URL endpoint (This is the Task we created earlier in this example.) and displays the output of the Pipeline in the HTTP Status field: 603, as configured using the Mapper Snap, above.
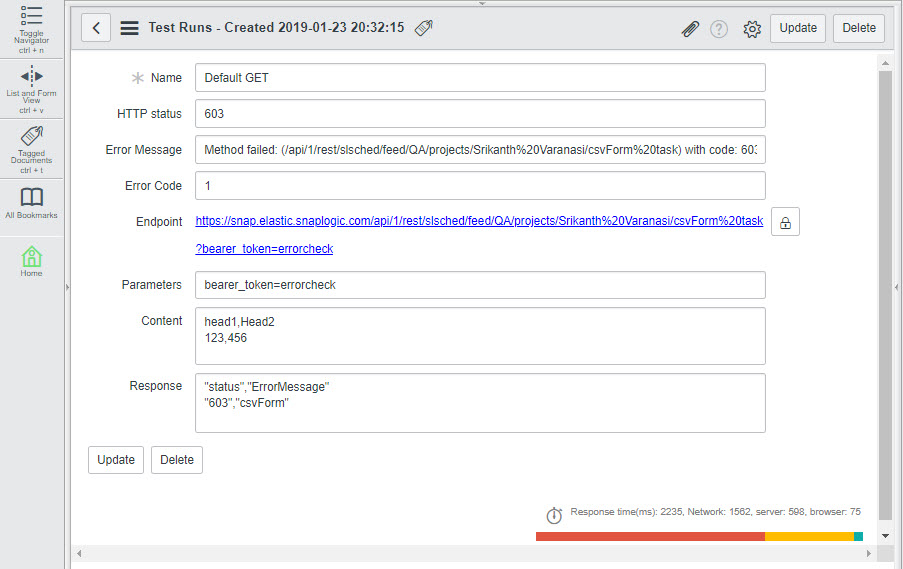
You can similarly use the CSV Formatter Snap to update binary header values associated with any input document.
Downloads
Download and import the Pipeline into SnapLogic.
Configure Snap accounts as applicable.
Provide Pipeline parameters as applicable.