On this Page
Overview
This Snap provides the functionality of SCD (Slowly Changing Dimension) Type 2 on a target Snowflake table. The Snap executes one SQL lookup request per set of input documents to avoid making a request for every input record. Its output is typically a stream of documents for the Snowflake - Bulk Upsert Snap, which updates or inserts rows into the target table. Therefore, this Snap must be connected to the Snowflake - Bulk Upsert Snap to accomplish the complete SCD2 functionality.

Input and Output
Expected input: Each document in the input view should contain a data map of key-value entries. The input data must contain data in the Natural Key (primary key) and Cause-historization fields.
Expected output: Each document in the output view contains a data map of key-value entries for all fields of a row in the target Snowflake table.
Expected upstream Snaps: Any Snap, such as a Mapper or JSON Parser Snap, whose output contains a map of key-value entries.
Expected downstream Snaps: Snowflake Bulk Upsert snap must be used as downstream snap since the Snowflake SCD2 snap only generates set of rows to be inserted or updated and it doesn't do any write operation on the table.
Prerequisites
- Read and write access to the Snowflake instance.
- The target table should have the following three columns for field historization to work:
- Column to demarcate whether a row is a current row or not. For example, "CURRENT_ROW". For the current row, the value would be true or 1. For the historical row, the value would be false or 0.
- Column to denote the starting date of the current row. For example, "START_DATE".
- Column to denote when the row was historized. For example, "END_DATE". For the active row, it is null. For a historical row, it has the value that indicates it was effective till that date.
- You must have minimum permissions on the database to execute Snowflake Snaps. To understand if you already have them, you must retrieve the current set of permissions. The following commands enable you to retrieve those permissions:
SHOW GRANTS ON DATABASE <database_name> SHOW GRANTS ON SCHEMA <schema_name> SHOW GRANTS TO USER <user_name>
Security Prerequisites: You should have the following permissions in your Snowflake account to execute this Snap:
- Usage (DB and Schema): Privilege to use database, role and schema.
- Create table: Privilege to create a table on the database. role and schema.
For more information on Snowflake privileges, refer to Access Control Privileges.
Internal SQL Commands
This Snap uses the SELECT command internally. It enables querying the database to retrieve a set of rows.
Configuring Accounts
This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Snowflake Account for information on setting up this type of account.
Configuring Views
Input | This Snap has exactly one document input view. |
|---|---|
| Output | This Snap has exactly one document output view. |
| Error | This Snap has at most one document error view. |
Troubleshooting
None.
Limitations and Known Issues
Because of performance issues, all Snowflake Snaps now ignore the Cancel queued queries when pipeline is stopped or if it fails option for Manage Queued Queries, even when selected. Snaps behave as though the default Continue to execute queued queries when the Pipeline is stopped or if it fails option were selected.
We plan to address this issue in a patch for the next monthly release in December.
Modes
- Ultra Pipelines: Works in Ultra Pipelines.
Snap Settings
| Label | Required. The name for the Snap. Modify this to be more specific, especially if there are more than one of the same Snap in the pipeline. |
|---|---|
| Schema name | The name of the schema containing the target table. Providing the schema name along with the table name in the Table name field is sufficient. The suggestible field that lists all available schema in the configured account. Default value: None Example: "TestSchema" |
| Table name | Required. The name of the target table. Syntax is "<schema_name>"."<table_name>". This is a suggestible field that lists all available tables if the schema is provided in the Schema name field. Alternatively, if the Schema name field is blank, it lists all tables within the account if the schema is not provided. Default value: None Example: "TestSchema"."TestTable" The target table should have the following three columns for field historization to work:
Use the ALTER table command to add these columns to your target table if they are not present. |
| Natural key | Names of fields that identify a unique row in the target table. The identity key cannot be used as the Natural key, since a current row and its historical rows cannot have the same natural key value Default value: None Example: id (Each record has to have a unique value) |
| Cause-historization fields | Names of fields where any change in value causes the historization of an existing row and the insertion of a new current row. Default value: None Example: gold bullion rate |
| SCD fields | Required. The historical and updated information for the Cause-historization field. Click + to add SCD fields. By default, there are four rows in this field-set:
|
| Meaning | Specifies the table columns that are to be updated for implementing the SCD2 type transformation. Default value:
|
| Field | The fields in the table will contain the historical information. Default value: None Below are the values that must be configured for each row:
By default, the start and end date for both Current row and Historical row are null. After the Snap is executed, the start date for the updated row data automatically becomes the end date for the earlier version of the data (Historical row). |
| Value | The value to be assigned to the current or historical row. For date-related rows, the default is Date.now(). Default value:
The Value field should be configured as follows:
|
| Ignore unchanged rows | Specifies whether the Snap must ignore writing unchanged rows from the source table to the target table. If you enable this option, the Snap generates a corresponding document in the target only if the Cause-historization column in the source row is changed. Else, the Snap does not generate any corresponding document in the target. Default value: Not selected |
| Number of retries | The number of times that the Snap must try to write the fields in case of an error during processing. An error is displayed if the maximum number of tries has been reached. Default value: 0 |
| Retry interval (seconds) | The time interval, in seconds, between subsequent retry attempts. Default value: 1 |
| Auto Historization Query | This field-set is used to specify the fields that are to be used to historize table data. Historization is in the sort order specified. Care must be taken that the field is sortable. You can also add multiple fields here; historizaton occurs when even of the fields is changed. |
| Field | The name of the field. This is a suggestible field and suggests all the fields in the target table. Example: Invoice_Number Default value: N/A If this field has null values in the incoming records, then the value in the Snowflake table is treated as the current value and the incoming record is historized. |
| Sort Order | The order in which the selected field is to be historized. Available options are:
Default value: Ascending Order |
| Input Date Format | The property has the following two options:
|
| Manage Queued Queries | Select this property to decide whether the Snap should continue or cancel the execution of the queued Snowflake Execute SQL queries when you stop the pipeline. If you select Cancel queued queries when pipeline is stopped or if it fails, then the read queries under execution are canceled, whereas the write queries under execution are not canceled. Snowflake internally determines which queries are safe to be canceled and cancels those queries. Default value: Continue to execute queued queries when pipeline is stopped or if it fails |
Page lookup error: page "Anaplan Read" not found. If you're experiencing issues please see our Troubleshooting Guide. | Page lookup error: page "Anaplan Read" not found. If you're experiencing issues please see our Troubleshooting Guide. |
Examples
Historizing Incoming Records
This example demonstrates how you can use the Snowflake SCD2 Snap to auto-historize records. In this example, since the existing record in the Snowflake table is the latest, the incoming records are historized.
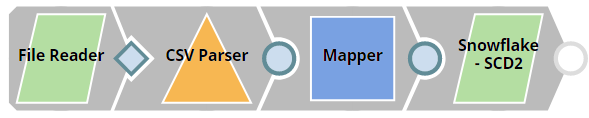
This Pipeline performs the following operations:
- Read, parse, and map the input data with the fields in the target table.
- Historize records based on the specified criteria.
- Upsert the latest data into the target table.
The Target Table
Before we start, let us look at the target table and understand some of its columns that are necessary for the Pipeline:

We focus on the highlighted columns above to demonstrate auto-historization and describe their function in the table.
- POINT ID is the natural key in this table.
- Changes in SCHEDULEDVOLUME for a natural key are historized.
- HISTORYSTARTDATE and HISTORYENDDATE are used to identify the current record.
- FLAG denotes if a record is a current record with the value TRUE.
- STARTDATE and ENDDATE are automatically calculated by the Snap. They represent the date range during which a record was the current record. The ENDDATE is blank for the current record.
Input Data: Reading, Parsing and Mapping
This Pipeline is configured to send records into the target table. The File Reader Snap is configured to read a CSV file that contains the records. The downstream CSV Parser Snap parses the CSV file read by the File Reader Snap. Below is a preview of this file:
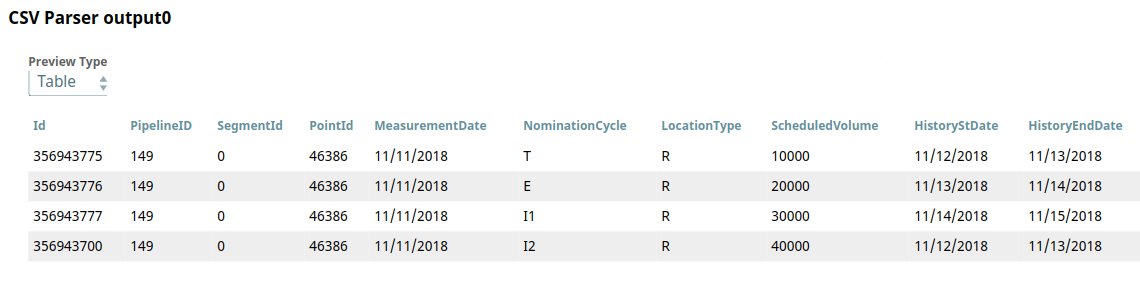
Based on the values of HistoryStDate and HistoryEndDate, it is clear that the existing record in the target table is the latest (or current) record.
Since the output from the CSV Parser Snap is a string, it has to be parsed into the appropriate data type. Parsing and data mapping is done using the Mapper Snap, as shown below:
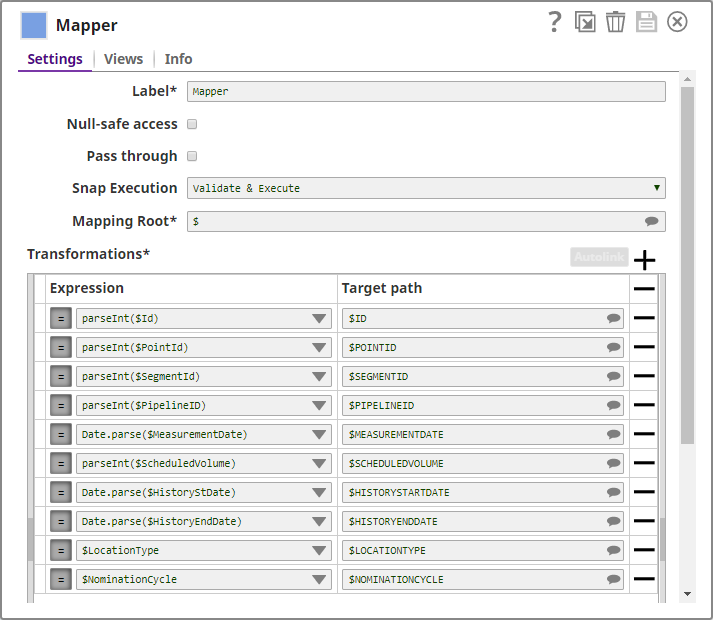
This mapped data is then sent to the Snowflake SCD2 Snap.
Data Processing
The Snowflake SCD2 Snap performs SCD2 operations on the target table. We configure it as shown below:
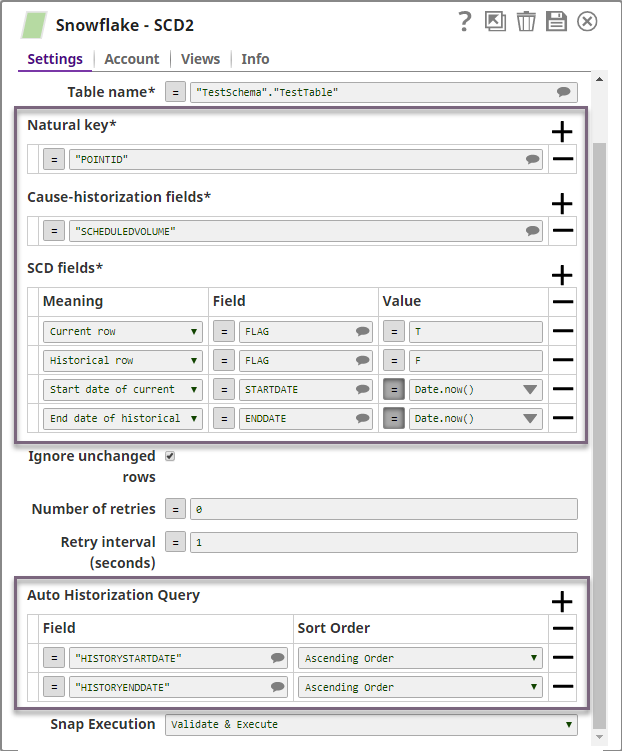
Let us take a look at the highlighted Snap fields and how they affect the Snap functionality in this example:
- Natural key: The Snap looks for records with matching POINT ID values in the incoming documents to group the records.
- Cause-historization fields: For each unique POINT ID, changes in SCHEDULEDVOLUME initiate historization. If a change has not occurred, the incoming records are historized..
- SCD fields:
- The state of the current or historical record is marked in the FLAG field, T for current record and F for the historical record.
- The columns STARTDATE and ENDDATE in the target table are maintained to denote the start and end dates of the current state of the table's data. The ENDDATE is always blank for a current record.
- Auto Historization Query: The Snap sorts the values in the HISTORYSTARTDATE and HISTORYENDDATE columns for the same POINT ID in the Snowflake table and the incoming documents in ascending order. The record with the highest value in those fields is considered the current record.
All incoming records pertaining to a POINT ID are historized. The value F is assigned under the FLAG column to these fields and the corresponding STARTDATE and ENDDATE are evaluated by the expression Date.now().
This can be seen in the SCD2 Snap's output preview:
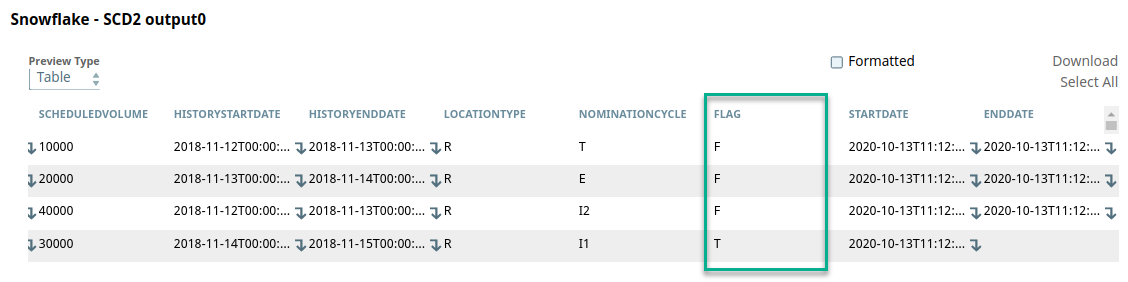
The Snap identifies the current and historical records and this data is now ready to be updated and inserted into the target table.
Upsert Data into the Target Table
We use the Snowflake Bulk Upsert Snap to update the target table with this historized data. We configure the Snowflake Bulk Upsert Snap as shown below:
Downloads
Important steps to successfully reuse Pipelines
- Download and import the pipeline into the SnapLogic application.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.
Release | Snap Pack Version | Date | Type | Updates |
|---|---|---|---|---|
August 2024 | main27765 | Stable | Upgraded the | |
May 2024 | 437patches27531 |
| Latest | Enhanced the Snowflake - Select Snap with Time Travel query support that enables you to access historical data at any point within a defined period. This includes restoring data-related objects, duplicating and backing up data, and analyzing data usage. |
May 2024 | 437patches27156 |
| Latest |
|
May 2024 | 437patches26821 |
| Latest |
|
May 2024 | 437patches26508 |
| Latest |
|
May 2024 | main26341 |
| Stable |
|
February 2024 | 436patches25630 |
| Latest |
|
February 2024 | main25112 |
| Stable | Updated and certified against the current SnapLogic Platform release. |
November 2023 | 435patches24865 |
| Latest | Fixed an issue across the Snowflake Snaps that populated all suggestions for the Schema and Table Names existing in the configured Snowflake Account. Now, the Snaps only populate suggestions related to the database configured in the Account. |
November 2023 | 435patches24110 |
| Latest | Added a lint warning to the Snowflake-Bulk Load Snap that recommends users to select the Purge checkbox when the Data source is input view and the Staging location is External. |
November 2023 | main23721 |
| Stable | The Snowflake Snap Pack is now bundled with the default Snowflake JDBC driver v3.14. |
August 2023 | 434patches23541 |
| Latest | Fixed an issue with the Snowflake-Bulk Load Snap where the Snap wrote irrelevant errors to the error view when both of the following conditions occurred:
Now, the Snap writes the correct errors to the error view. |
August 2023 | main22460 |
| Stable | The Snowflake - Execute Snap now includes a new Query type field. When Auto is selected, the Snap tries to determine the query type automatically. |
May 2023 | 433patches21890 |
| Latest |
|
May 2023 | 433patches21370 |
| Latest |
|
May 2023 | main21015 |
| Stable |
|
February 2023 | 432patches20906 |
| Latest |
|
February 2023 | 432patches20266 |
| Latest | Fixed an issue with the Snowflake - Bulk Load Snap that resulted in lowercase (or mixed case) column names when creating a new table under specific conditions. The new Create table with uppercase column names checkbox addresses this issue. |
February 2023 | 432patches20120 |
| Latest | The Snowflake Bulk Load, Bulk Upsert, and Unload Snaps now support expressions for the Staging location field. |
February 2023 | main19844 |
| Stable |
|
November 2022 | 431patches19581 |
| Latest |
|
November 2022 | 431patches19454 |
| Latest | The Snowflake Snap Pack supports geospatial data types. As the Snowflake Snap Pack requires using our custom Snowflake JDBC driver for full support of all data types, contact support@snaplogic.com for details. |
November 2022 | 431patches19220 |
| Latest | The Snowflake S3 OAuth2 Account now support expressions for external staging fields. |
November 2022 | 431patches19220
|
| Latest |
|
November 2022 | main18944 |
| Stable |
|
November 2022 | 430patches18911 |
| Latest | Because of performance issues, all Snowflake Snaps now ignore the Cancel queued queries when pipeline is stopped or if it fails option for Manage Queued Queries, even when selected. Snaps behave as though the default Continue to execute queued queries when the Pipeline is stopped or if it fails option were selected. |
October 2022 | 430patches18781 |
| Latest | The Snowflake Insert and Snowflake Bulk Upsert Snaps now do not fail with the The Snowflake Bulk Load Snap now works as expected when you configure On Error with SKIP_FILE_*error_percent_limit*% and set the Error Percent Limit to more than the percentage of rows with invalid data in the CSV file. |
October 2022 | 430patches18432 |
| Latest | The Snowflake Bulk Load Snap now has a Validation Errors Type dynamic field, which provides options for displaying validation errors. You can now choose Aggregate errors per row to display a summary view of errors. |
September 2022 | 430patches17962 |
| Latest | The Snowflake Bulk Load Snap now triggers the metadata query only once even for invalid input, thereby improving the performance of Snap. |
September 2022 | 430patches17894 |
| Latest | The Snowflake Select Snap now works as expected when the table name is dependent on an upstream input. |
August 2022 | 430patches17748 |
| Latest | Fixes in the Snowflake Bulk Load Snap:
|
August 2022 | 430patches17377 |
| Latest |
|
August 2022 | main17386 |
| Stable | The following Snowflake Accounts support Key Pair Authentication. |
4.29 Patch | 429patches16478 |
| Latest | Fixed an issue with Snowflake - Bulk Load Snap where Snap failed with 301 status code - SnapDataException. |
4.29 Patch | 429patches16458 |
| Latest |
|
4.29 | main15993 |
| Stable | Upgraded with the latest SnapLogic Platform release. |
4.28 Patch | 428patches15236 |
| Latest |
|
4.28 | main14627 |
| Stable |
|
4.27 | 427patches12999 |
| Latest | Enhanced the Snowflake SCD2 Snap to support Pipeline parameters for Natural key and Cause-historization fields. |
4.27 | main12833 |
| Stable |
|
4.26 Patch | 426patches11469 |
| Latest | Fixed an issue with Snowflake Insert and Snowflake Bulk Load Snaps where the schema names or database names containing underscore (_) caused the time out of Pipelines. |
4.26 | main11181 |
| Stable |
|
4.25 | 425patches10190 | Latest | Enhanced the Snowflake S3 Database and Snowflake S3 Dynamic accounts with a new field S3 AWS Token that allows you to connect to private and protected Amazon S3 buckets. | |
4.25 | main9554 |
| Stable | Upgraded with the latest SnapLogic Platform release. |
4.24 Patch | 424patches8905 |
| Latest | Enhanced the Snowflake - Bulk Load Snap to allow transforming data using a new field Select Query before loading data into the Snowflake database. This option enables you to query the staged data files by either reordering the columns or loading a subset of table data from a staged file. This Snap supports CSV and JSON file formats for this data transformation. |
4.24 | main8556 | Stable | Enhanced the Snowflake - Select Snap to return only the selected output fields or columns in the output schema (second output view) using the Fetch Output Fields In Schema check box. If the Output Fields field is empty all the columns are visible. | |
4.23 Patch | 423patches7905 |
| Latest | Fixed the performance issue in the Snowflake - Bulk Load Snap while using External Staging on Amazon S3. |
4.23 | main7430 |
| Stable |
|
4.22 Patch | 422patches7246 |
| Latest | Fixed an issue with the Snowflake Snaps that failed while displaying similar error in the Snowflake URL connection: |
4.22 Patch | 422patches6849 |
| Latest |
|
4.22 | main6403 |
| Stable | Updated with the latest SnapLogic Platform release. |
4.21 Patch | 421patches6272 |
| Latest | Fixes the issue where Snowflake SCD2 Snap generates two output documents despite no changes to Cause-historization fields with DATE, TIME and TIMESTAMP Snowflake data types, and with Ignore unchanged rows field selected. |
4.21 Patch | 421patches6144 |
| Latest |
|
4.21 Patch | db/snowflake8860 |
| Latest | Added a new field, Handle Timestamp and Date Time Data, to Snowflake Lookup Snap. This field enables you to decide whether the Snap should translate UTC time to your local time and the format of the Date Time data. |
4.21 Patch | MULTIPLE8841 |
| Latest | Fixed the connection issue in Database Snaps by detecting and closing open connections after the Snap execution ends. |
4.21 | snapsmrc542 |
| Stable | Upgraded with the latest SnapLogic Platform release. |
4.20 Patch | db/snowflake8800 |
| Latest |
|
4.20 Patch | db/snowflake8758 |
| Latest | Re-release of fixes from db/snowflake8687 for 4.20: Fixes the Snowflake Bulk Load snap where the Snap fails to load documents containing single quotes when the Load empty strings checkbox is not selected. |
4.20 | snapsmrc535 |
| Stable | Upgraded with the latest SnapLogic Platform release. |
4.19 Patch | db/snowflake8687 |
| Latest | Fixed the Snowflake Bulk Load snap where the Snap fails to load documents containing single quotes when the Load empty strings checkbox is not selected. |
4.19 Patch | db/snowflake8499 |
| Latest | Added the property Handle Timestamp and Date Time Data to Snowflake - Execute and Snowflake - Select Snaps. This property enables you to decide whether the Snap should translate UTC time to your local time. |
4.19 Patch | db/snowflake8412 |
| Latest | Fixed an issue with the Snowflake - Update Snap wherein the Snap is unable to perform operations when:
|
4.19 | snaprsmrc528 |
| Stable |
|
4.18 Patch | db/snowflake8044 |
| Latest | Fixed an issue with the Snowflake - Select Snap wherein the Snap converts the Snowflake-provided timestamp value to the local timezone of the account. |
4.18 Patch | db/snowflake8044 |
| Latest | Enhanced the Snap Pack to support AWS SDK 1.11.634 to fix the NullPointerException issue in the AWS SDK. This issue occurred in AWS-related Snaps that had HTTP or HTTPS proxy configured without a username and/or password. |
4.18 Patch | MULTIPLE7884 |
| Latest | Fixed an issue with the PostgreSQL grammar to better handle the single quote characters. |
4.18 Patch | db/snowflake7821 |
| Latest | Fixed an issue with the Snowflake - Execute Snap wherein the Snap is unable to support the '$' character in query syntax. |
4.18 Patch | MULTIPLE7778 |
| Latest | Updated the AWS SDK library version to default to Signature Version 4 Signing process for API requests across all regions. |
4.18 Patch | db/snowflake7739 |
| Latest |
|
4.18 | snapsmrc523 |
| Stable | Added the Use Result Query property to the Multi Execute Snap, which enables you to write results to an output view. |
4.17 | ALL7402 |
| Latest | Pushed automatic rebuild of the latest version of each Snap Pack to SnapLogic UAT and Elastic servers. |
4.17 Patch | db/snowflake7396 |
| Latest | Fixed an issue wherein bit data types in the Snowflake - Select table convert to true or false instead of 0 or 1. |
4.17 Patch | db/snowflake7334 |
| Latest | Added AWS Server-Side Encryption support for AWS S3 and AWS KMS (Key Management Service) for Snowflake Bulk Load, Snowflake Bulk Upsert, and Snowflake Unload Snaps. |
4.17 | snapsmrc515 |
| Latest |
|
4.16 Patch | db/snowflake6945 |
| Latest | Fixed an issue with the Snowflake Lookup Snap failing when Date datatype is used in JavaScript functions. |
4.16 Patch | db/snowflake6928 |
| Latest | Added support for file format options for input data from upstream Snaps, to the Snowflake Bulk Load Snap. |
4.16 Patch | db/snowflake6819 |
| Latest |
|
4.16 | snapsmrc508 |
| Stable |
|
4.15 | snapsmrc500 |
| Stable |
|
4.14 | snapsmrc490 |
| Stable | Upgraded with the latest SnapLogic Platform release. |
4.13 | snapsmrc486 |
| Stable | Upgraded with the latest SnapLogic Platform release. |
4.12 | snapsmrc480 |
| Stable | Upgraded with the latest SnapLogic Platform release. |
4.11 Patch | MULTIPLE4377 |
| Latest | Fixed a document call issue that was slowing down the Snowflake Bulk Load Snap. |
4.11 Patch | db/snowflake4283 |
| Latest | Snowflake Bulk Load - Fixed an issue by adding PUT command to the list of DDL command list for Snowflake. |
4.11 Patch | db/snowflake4273 |
| Latest | Snowflake Bulk Load - Resolved an issue with Snowflake Bulk Load Delimiter Consistency (comma and newline). |
4.11 | snapsmrc465 |
| Stable | Upgraded with the latest SnapLogic Platform release. |
4.10 Patch | snowflake4133 |
| Latest | Updated the Snowflake Bulk Load Snap with Preserve case sensitivity property to preserve the case sensitivity of column names. |
4.10 | snapsmrc414 |
| Stable |
|
4.9.0 Patch | snowflake3234 |
| Latest | Enhanced Snowflake - Execute Snap results to include additional details |
4.9.0 Patch | snowflake3125 |
| Latest | Addressed an issue in Snowflake Bulk Load where the comma character in a value is not escaped. |
4.9 | snapsmrc405 |
| Stable | JDBC Driver Class property added to enable the user to custom configure the JDBC driver in the Database and the Dynamic accounts. |
4.8.0 Patch | snowflake2760 |
| Latest | Potential fix for JDBC deadlock issue. |
4.8.0 Patch | snowflake2739 |
| Latest | Addressed an issue with the Snowflake schema not correctly represented in the Mapper Snap. |
4.8 | snapsmrc398 |
| Stable |
|