In this article
Overview
You can use this Snap to apply aggregate functions on input data using the Group By support. This Snap enables you to calculate an aggregate function on a set of values to return a single scalar value.
This Snap does not support
listandmapobjects referenced in the JSON paths.If the input documents are unsorted and GROUP-BY fields are used, you must use the Sort Snap upstream of the Aggregate Snap to presort the input document stream and set the Sorted stream field Ascending or Descending to prevent the
out-of-memoryerror. Learn more about presorting unsorted input documents to be processed by the Aggregate Snap. However, if the total size of input documents is expected to be relatively small compared to the available memory, then Sort Snap is not required upstream.
The following are the commonly used SQL Aggregate functions:
AVG – calculates the average of a set of values.
COUNT – counts rows in a specified table or view.
MIN – gets the minimum value in a set of values.
MAX – gets the maximum value in a set of values.
SUM – calculates the sum of values.
CONCAT – calculates the sum of values.
UNIQUE_CONCAT – calculates the sum of values.
Snap Type
Aggregate Snap is a Transofrm type Snap that transforms, parses, cleans, and formats data from binary to document data.
Prerequisites
None.
Support for Ultra Pipelines
Does not support Ultra Pipelines.
Limitations and Known Issues
None.
Snap Views
Type | Format | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input | Document |
|
| Each document should contain values referenced in the Aggregate fields and the GROUP-BY fields field set. If not, the input data is sent to the error view. |
Output | Document |
|
| Each document contains the mapped data that includes key-value entries of the GROUP-BY field name and its value, and a key-value entry of the Result field and its value, if processed successfully. |
Error | Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter while running the Pipeline by choosing one of the following options from the When errors occur list under the Views tab. The available options are:
Learn more about Error handling in Pipelines. | |||
Snap Settings
Asterisk (*): Indicates a mandatory field.
Suggestion icon (
 ): Indicates a list that is dynamically populated based on the configuration.
): Indicates a list that is dynamically populated based on the configuration.Expression icon (
): Indicates whether the value is an expression (if enabled) or a static value (if disabled). Learn more about Using Expressions in SnapLogic.Add icon (
): Indicates that you can add fields in the field set.Remove icon (
): Indicates that you can remove fields from the field set.
Field Name | Type | Description | |
|---|---|---|---|
Label* Default Value: Aggregate | String | Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. | |
Aggregate fields* | Use this field set to define the type of Aggregate function to perform on the field and the key name to be used in the output. This field set contains the following fields:
| ||
Function* Default Value: SUM | String | Select the functions that applies to the aggregate field value in the input data. The available functions and the supported datatypes are:
When you select the AVG function, the Snap rounds up all numeric values that have more than 16 digits. The AVG function handles the numeric values as below:
| |
Field* Default value: [None] | String/Expression | Specify a JSON path to the field on which the Aggregate function should be applied such as | |
Result field* Default value: [None] | String | Specify the field name to be used for mapped data in the output. This value is the aggregate computed result corresponding to the GROUP-BY field values. | |
GROUP-BY fields* | Use this field set to define field paths and names. If you leave this field blank, the Snap produces only one output document. | ||
Field Default value: [None] | String/Expression | Specify a JSON path for the GROUP-BY field. | |
Output field Default value: [None] | String | Specify the GROUP-BY field name to be used in the output map data. If left blank, the Field path is used instead. | |
Integer mode Default value: Deselected | Checkbox | Select this checkbox if you want the Snap to produce integer results rounded half up. The input data can be mixed in integers and floating-point numbers, and the Snap maintains intermediate results in floating-point numbers. The value of this field is ignored in the COUNT Aggregate function. | |
Sorted streams* Default value: Unsorted | Dropdown list | Select an option to specify if the input documents are sorted or not. This option enables the Snap to verify if the input is sorted as it processes each document and performs the aggregation efficiently and displays an error if the records are not sorted. The available options are:
If the input data stream contains a large number of documents, then presort the input using the Sort Snap as this uses less memory and results in an effective performance. If you select Unsorted and are using GROUP-BY fields, the Aggregate Snap uses MapDB internally in order to avoid an out-of-memory error issue. Therefore, starting with 434patches23034, when GROUP-BY fields are used in the Aggregate Snap and the Sorted streams field is Unsorted, the order of the output documents may be different from one execution to another. | |
Minimum memory (MB) Default value: 500 | String/Expression | If the available memory is less than this property value while processing input documents, the Snap stops to fetch the next input document until more memory is available. This feature is disabled if this property value is 0. | |
Out-of-memory timeout (minutes) Default value: 30 | String/Expression | If the Snap pauses longer than this property value while waiting for more memory available, it throws an exception to prevent the system from running out of memory. | |
Snap Execution Default value: Validate & Execute | Dropdown list | Select one of the three modes in which the Snap executes. Available options are:
| |
Temporary Files
During execution, data processing on Snaplex nodes occurs principally in-memory as streaming and is unencrypted. When larger datasets are processed that exceeds the available compute memory, the Snap writes Pipeline data to local storage as unencrypted to optimize the performance. These temporary files are deleted when the Snap/Pipeline execution completes. You can configure the temporary data's location in the Global properties table of the Snaplex's node properties, which can also help avoid Pipeline errors due to the unavailability of space. For more information, see Temporary Folder in Configuration Options.
Troubleshooting
Error | Reason | Resolution |
|---|---|---|
| Expressions have been detected in Aggregate. | Remove all expressions. |
| The selected aggregate function is not supported. | Select a valid aggregate function. |
| One or more variables in the JSON file are not mapped. | Either remove non substituted variables starting with |
| Reserved characters are detected in the JSON key value pair. | Replace the reserved characters using # and [[ ]]. For example, replace ‘##’ as #[[##]]# to escape it. |
| MapDB intermittently retrieves null for non-null value. | Use Sort Snap to sort the input data stream. |
Examples
Sort input data and perform aggregate functions
This example pipeline demonstrates how to pre-sort the records with the Sort Snap and then perform the aggregate functions on each group using the Aggregate Snap.

Configure the Sequence Snap and Mapper Snap to produce a large set of unsorted input documents to be processed by Aggregate Snap.
Configure the Sort Snap to sort the group values in an ascending order.

Configure the Aggregate Snap as shown below.
Aggregate Snap Configuration | Description |
|---|---|

|
|
On executing the pipeline, the Sort Snap completes the sorting and the Aggregate Snap the aggregate functions. You can view the execution details in the Pipeline Execution Statistics.

Important: If the input documents are unsorted and GROUP-BY fields are used, you must use the Sort Snap upstream of the Aggregate Snap to presort the input document stream and set the Sorted stream field Ascending or Descending to prevent the out-of-memory error. For more information, refer to the attached example pipeline.
Concatenate unique string values
The following example pipeline demonstrates how to concatenate unique string values.
Configure the JSON Generator Snap to pass product and order details. Then, use the Aggregate Snap to concatenate the Order IDs and group the fields by Product names. To achieve this, configure this Snap with CONCAT function and specify $Product.Name.

On validation, you can view the Product names along with the Order IDs in the output preview.

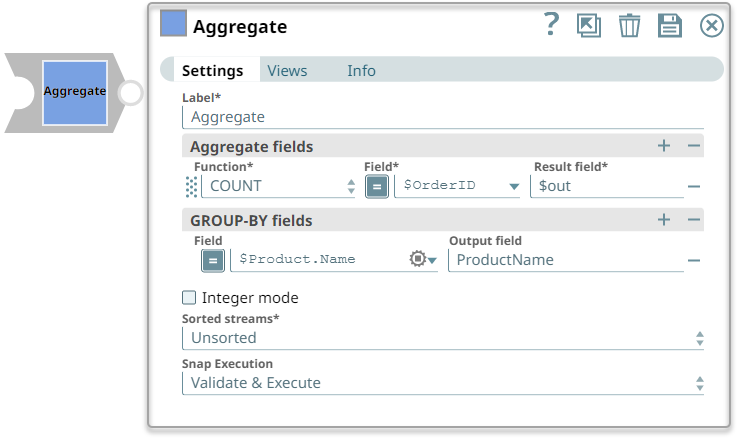
Count the occurrences of a given product name
The following example pipeline demonstrates how to use the Aggregate Snap to count the occurrences of a given product name.


Downloads
Download and import the Pipeline into SnapLogic.
Configure Snap accounts as applicable.
Provide Pipeline parameters as applicable.