On this Page
Overview
This is a Transform type Snap that builds model for a classification dataset. In the Snap's settings, you can select the target field in the dataset, algorithm, and configure parameters for the selected algorithm.
If you want to build the model on regression dataset, use Trainer -- Regression Snap instead.
Input and Output
Expected input: The classification dataset.
Expected output: A serialization of the model, and metadata which are not human-readable. Additionally, the output includes a human-readable representation of the model if the Readable checkbox is selected.
Expected upstream Snap: Any Snap that generates a classification dataset document. For example, CSV Generator, JSON Generator, or a combination of File Reader and JSON Parser.
Expected downstream Snap: Snaps that require a model input. For example, the Predictor (Classification) Snap. Alternatively, any Snap that stores the model to be used in another pipeline. For example, a combination of JSON Formatter and File Writer.
Prerequisites
- The data from upstream Snap must be in tabular format (no nested structure).
- This Snap automatically derives the schema (field names and types) from the first document. Therefore, the first document must not have any missing values.
Configuring Accounts
Accounts are not used with this Snap.
Configuring Views
Input | This Snap has exactly one document input view. |
|---|---|
| Output | This Snap has exactly one document output view. |
| Error | This Snap has at most one document error view. |
Troubleshooting
None.
Limitations and Known Issues
None.
Modes
- Ultra Pipelines: Does not work in Ultra Pipelines.
Snap Settings
| Label | Required. The name for the Snap. Modify this to be more specific, especially if there are more than one of the same Snap in the pipeline. |
|---|---|
| Label field | Required. The label or output field in the dataset. This must be a categorical type represented as text (string data type). This is the field that the model will be trained to predict. Default value: None Example: $class |
| Algorithm | Required. The classification algorithm to be used to build the model. There are eight classification algorithms currently available:
The implementations are from WEKA, an open source machine learning library in Java. Default value: Decision Tree |
| Options | The parameters to be applied on the selected classification algorithm. Each algorithm has a different set of parameters to be configured in this property. If this property is left blank, the default values are applied for all the parameters. If specifying multiple parameters, separate them with a comma ",". See Options for Algorithms section below for details. Default value: None Examples:
|
| Readable | Select this to output the model in human-readable format. When selected, a $readable field is added to the output, this displays the model in a readable format. Default value: Not selected |
Page lookup error: page "Anaplan Read" not found. If you're experiencing issues please see our Troubleshooting Guide. | Page lookup error: page "Anaplan Read" not found. If you're experiencing issues please see our Troubleshooting Guide. |
Best Practices
Using Type Converter Snap Upstream
In some cases, the numerical fields may be represented as text. You can use the Type Converter Snap to convert data into appropriate types before feeding into the Trainer (Classification) Snap.
Algorithm Selection
In order to choose the best possible algorithm for your dataset, use the Cross Validator (Classification) Snap to perform k-fold cross validation on the dataset. The algorithm that produces the best accuracy is likely to be the one most suitable for your dataset. Apply the same algorithm for your dataset in the Trainer (Classification) Snap to build the model.
Options for Algorithms
Example
Weight Balance Classification – Model Training
This pipeline demonstrates training a model to predict whether a weighing scale is balanced. The classification algorithm is selected based on the algorithm evaluation in the Cross Validator (Classification) Snap's example. The input dataset depicts the weight on each side of the scale and the side's distance from the floor.

Download this pipeline.
Input
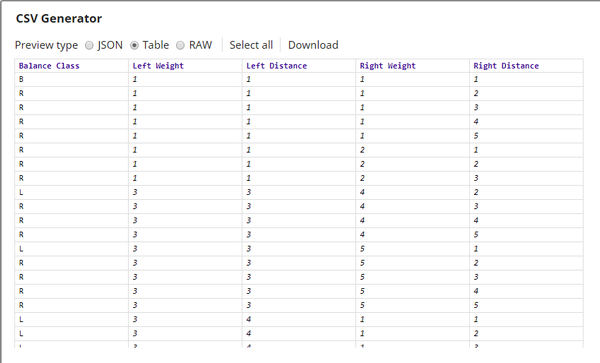
The input document is generated by the CSV Generator Snap and is composed of four fields, one classification field and three numeric fields:
- Balance Class: The classification field to denote status of the weighing scale. B for Balanced, L for Left-inclined, and R for Right-inclined.
- Left Weight
- Left Distance
- Right Weight
- Right Distance
This dataset has been sourced from UCI Dataset Archive.
Objective
Use Trainer (Classification) Snap to train the model for the dataset.
Data Preparation
This input document is passed through the Type Converter Snap that is configured to automatically detect and convert the data types. In any ML pipeline, you must first analyze the input document using the Profile Snap and the Type Inspector Snap to ensure that there are no null values or that the data types are accurate. This step is skipped in this example for simplicity's sake.
Model Training
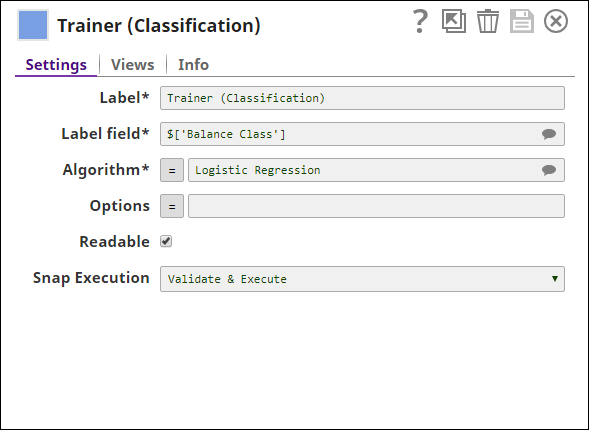
Since the training algorithm was evaluated in the Cross Validator (Classification) Snap, the Trainer (Classification) Snap is configured with the same settings:
The output from this Snap is as shown below:

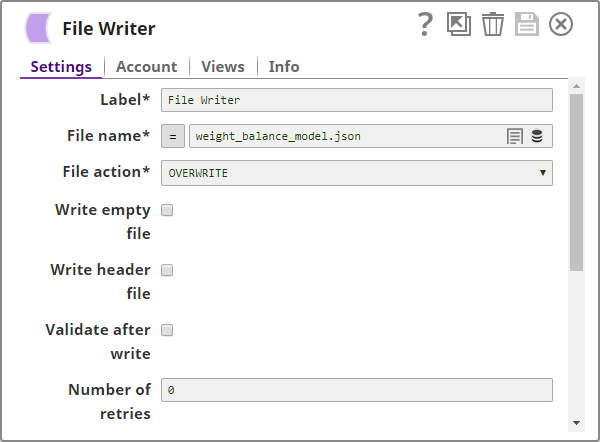
The model in the Trainer (Classification) Snap's output is written into a file using the File Writer Snap which is configured as shown below:
This model is used to predict the Balance Class for an unlabeled dataset. See Weight Balance Classification – Testing for details.
Download this pipeline.
Additional Example
The following use case demonstrates a real-world scenario for using this Snap:
Downloads
Important steps to successfully reuse Pipelines
- Download and import the pipeline into the SnapLogic application.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.