On this page
Overview
Use this Snap to remove duplicate records from input documents. When you use multiple matching criteria to deduplicate your data, it is evaluated using each criterion separately, and then aggregated to give the final result.
Prerequisites
None.
Limitations
None.
Troubleshooting
None.
Modes
- Ultra pipelines: Does not support Ultra pipelines.
- Spark mode: Not supported in Spark mode.
Snap Input and Output
| Input/Output | Type of View | Number of Views | Compatible Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
| Input | Document |
|
| A document with data containing duplicate records. |
| Output | Document |
|
|
|
Snap Settings
| Parameter Name | Data Type | Description | Default Value | Example |
|---|---|---|---|---|
| Label | String | Specify a unique name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. | N/A | Deduplicate Office Names |
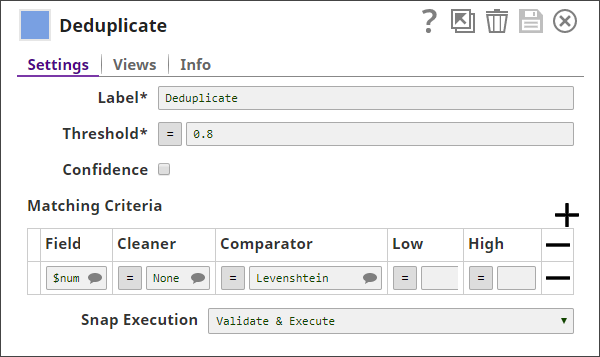
Threshold | Decimal | Required. The minimum confidence required for documents to be considered matched as duplicates using the matching criteria. Minimum Value: 0 Maximum Value: 1 | 0.8 | 0.95 |
| Confidence | Check box | Select this check box to include each match's confidence levels in the output. | Deselected | N/A |
| Matching Criteria | Fieldset | Enables you to specify the settings that you want to use to match input documents with the matching criteria. | N/A | N/A |
Field | JSONPath | The field in the input dataset that you want to use for matching and identifying duplicates. | N/A | $name |
Cleaner | String | Select the cleaner that you want to use on the selected fields. A cleaner makes comparison easier by removing variations from data, which are not likely to indicate genuine differences. For example, a cleaner might strip everything except digits from a ZIP code. Or, it might normalize and lowercase text. Depending on the nature of the data in the identified input fields, you can select the kind of cleaner you want to use from the options available:
| None | Text |
Comparator | String | A comparator compares two values and produces a similarity indicator, which is represented by a number that can range from 0 (completely different) to 1 (exactly equal). Choose the comparator that you want to use on the selected fields, from the drop-down list:
| Levenshtein | Numeric |
Low | Decimal | A decimal value representing the level of probability of the input documents to be matched if the specified fields are completely unlike. If this value is left empty, a value of 0.3 is applied automatically. | N/A | 0.1 |
High | Decimal | A decimal value representing the level of probability of the input documents to be matched if the specified fields are a complete match. If this value is left empty, a value of 0.95 is applied automatically. | NA | 0.8 |
| Snap Execution | String | Specifies the execution type:
| Validate & Execute | N/A |
Examples
Deduplicating the List of Childhood Centers in Chicago
In this example, you deduplicate the data in a CSV file containing a list of childhood centers in Chicago.
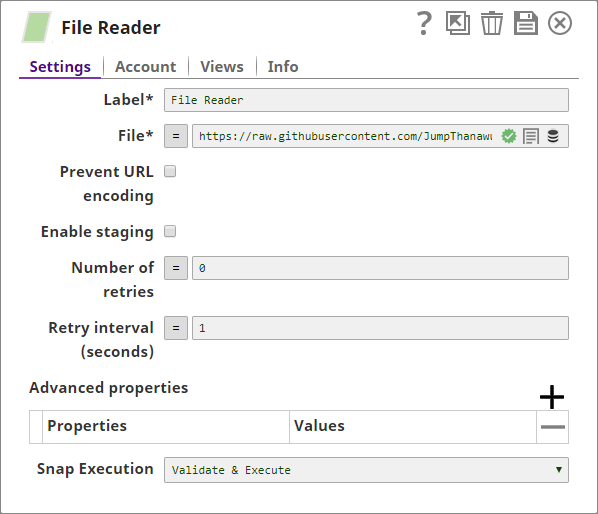
- You add a File Reader Snap to the Pipeline and configure it to read the source CSV file stored online:
The File Reader Snap displays the contents of the file, which contains many duplicate entries:
- You add a CSV Parser Snap to the Pipeline to interpret the input data as a CSV document.
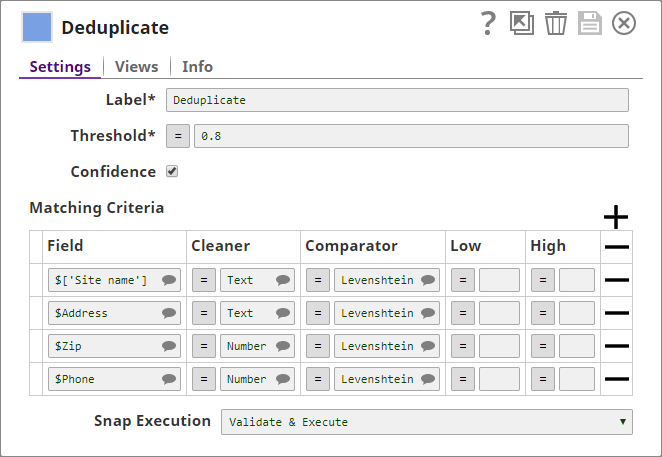
- You add a Deduplicate Snap to the Pipeline and configure it to use the name, address, ZIP, and phone details in the input document as fields for deduplication:
- You also add an additional output view to the Snap, where the Snap can display the duplicate data. Now, the Snap has two output views, one for the cleaned (deduplicated) data, and another for the duplicated records that the Snap filtered out.
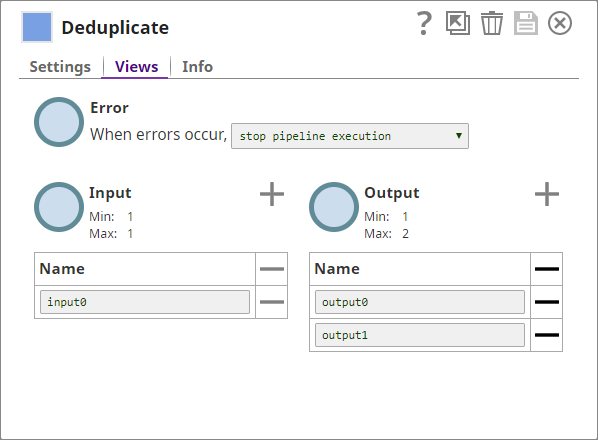
The Snap, when executed, offers the following two output documents (Output0 and Output1). Output0 contains the deduplicated data, while Output1 contains the duplicate data: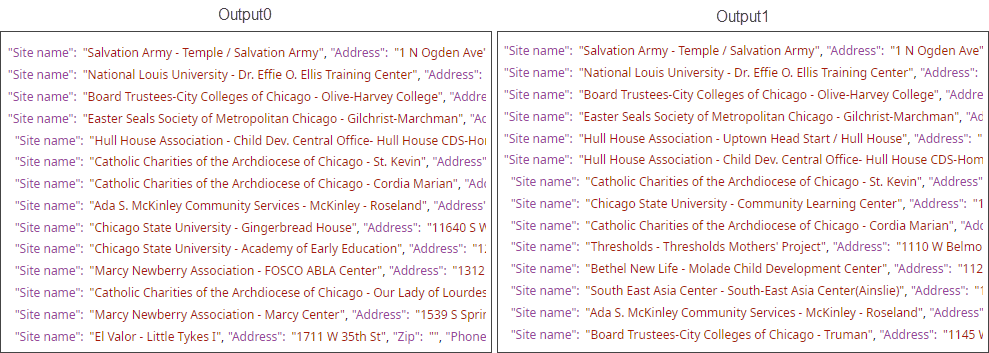
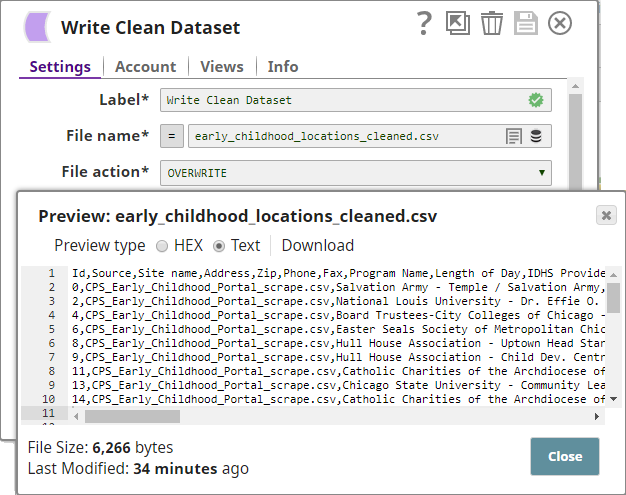
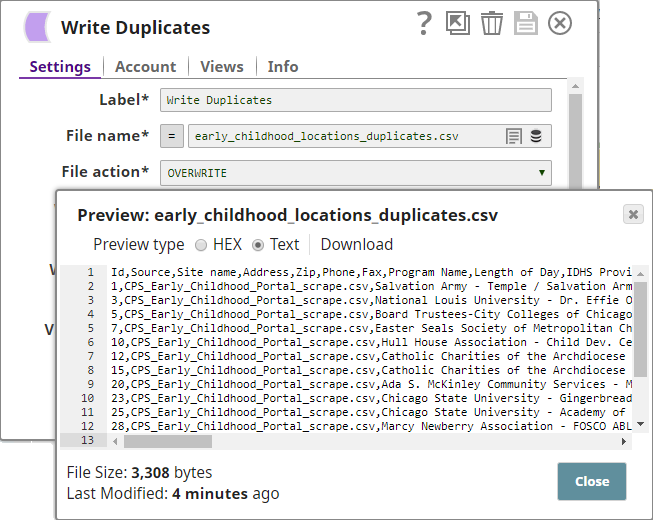
- You attach a CSV Formatter Snap to each output view of the Deduplicate Snap to structure the outputs as CSV documents. You then connect a File Writer Snap to each CSV Formatter Snap to write the input data as files.
- The Pipeline, when run, generates two output documents: one containing deduplicated data, and the other containing the duplicate data:
Downloads