In this article
Overview
Use this account to connect ELT Snaps with data sources that use ELT database accounts. This account enables you to write transformed data to target databases hosted in the following cloud locations. The JDBC URL you define for your target database indicates the respective cloud location where the database is hosted.
| Target Database | Supported Cloud Location | Cloud Location in JDBC URL |
|---|---|---|
| Snowflake | AWS | jdbc:snowflake://<account_name>.snowflakecomputing.com |
| Microsoft Azure | jdbc:snowflake://<account_name>.<region>.azure.snowflakecomputing.com | |
| Google Cloud Platform (GCP) | jdbc:snowflake://<account_name>.<region>.gcp.snowflakecomputing.com | |
| Redshift | AWS | jdbc:redshift://<redshift-cluster-name>.<region>.redshift.amazonaws.com |
| Azure Synapse | Microsoft Azure | jdbc:sqlserver://<yourserver>.database.windows.net |
Databricks Lakehouse Platform | Microsoft Azure | jdbc:spark://<your_instance_code>.cloud.databricks.com |
| Google BigQuery | Google Cloud Platform (GCP) | jdbc:bigquery://<host_URL>/bigquery |
The ELT Snap Pack does not support mixed accounts from different types of databases in the same Pipeline. For example, a Pipeline in which some Snaps are connecting to the Snowflake database cannot have other Snaps connecting to the Redshift database.
Prerequisites
A valid Snowflake, Redshift, Azure Synapse, or Databricks Lakehouse Platform database account.
Limitations
- Connects only to the Snowflake, Redshift, Azure Synapse, or Databricks Lakehouse Platform.
- In case of Azure Synapse database, the ELT database account supports the following:
- Only provisioned clusters of Azure Synapse, but not in Serverless mode.
- External locations:
- Blob Storage: https://.blob.core.windows.net//
- ADLS Gen2: https://.dfs.core.windows.net//
Known Issue
- When ELT and Spark SQL 2.x Snap account credentials—such as user names, passwords, client secrets, auth codes and tokens, secret keys, and keystores—are auto-filled using the Google Chrome browser, the accounts and hence the Pipelines fail. This is because the browser overwrites the field values with its own encrypted values that the SnapLogic Platform cannot read. SnapLogic recommends that you do not auto-save your Snap account credentials in the Chrome browser.
- Ensure that you delete any credentials that the browser has already saved for elastic.snaplogic.com, and then perform ONE of the following actions:
- Option 1: Click
 that appears in the address bar after you submit your login credentials at elastic.snaplogic.com, and then click Never.
that appears in the address bar after you submit your login credentials at elastic.snaplogic.com, and then click Never. - Option 2: Disable the Offer to save Passwords option at chrome://settings/passwords while working with your SnapLogic Pipelines. If you disable this option, your Chrome browser will not remember your passwords on any other website.
- Option 1: Click
Account Settings
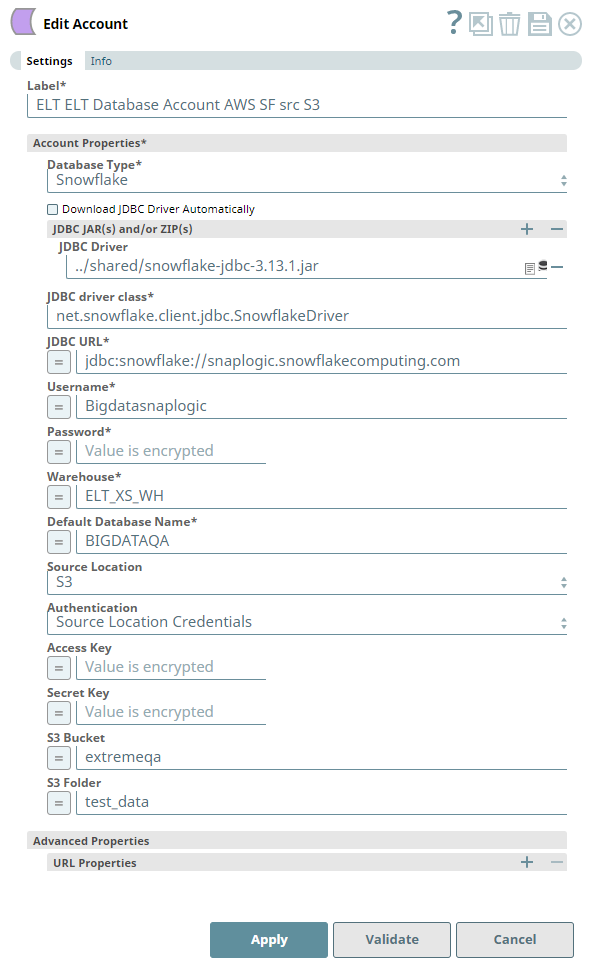
Click the = (Expression) button in the Account's configuration, if available, to define the corresponding field value using expression language and Pipeline parameters.
Fields marked with an asterisk ( * ) in the table below are mandatory.
| Parameter | Field Dependency | Description | ||
|---|---|---|---|---|
| Label* | None. | Required. Unique user-provided label for the account. Default Value: N/A Example: ELT Account | ||
| Account Properties* | Use this field set to configure the information required to establish a JDBC connection with the account. This field set consists of the following fields:
| |||
| Database Type* | None. | Required. Select the target data warehouse into which the queries must be loaded. Available options are:
Default Value: N/A Example: Snowflake | ||
| Download JDBC Driver Automatically | Check box | Select this checkbox to allow the Snap account to download the certified JDBC Driver based on the Database Type you have selected. The following fields are disabled when this checkbox is selected.
To use a JDBC Driver of your choice, clear this checkbox, upload (to SLDB), and choose the required JAR files in the JDBC JAR(s) and/or ZIP(s): JDBC Driver field. Use of Custom JDBC JAR version You can use different JAR file versions than those listed here. We recommend that you use the listed JAR file versions. See the latest Release Notes for more details. Default Value: Not Selected Example: Selected | ||
| JDBC JAR(s) and/or ZIP(s): JDBC Driver | Required when the Download JDBC Driver Automatically check box is not selected. | Upload the JDBC driver and other JAR files that you want to use into SLDB. Click Default Value: N/A Example: snowflake-jdbc-3.9.1.jar | ||
| JDBC driver class* | Required when the Download JDBC Driver Automatically check box is not selected. | Specify the driver class to use for your application. We recommend that you use the following classes to suit your database type as other classes and methods may change due to future enhancements:
Default Value: N/A Example: net.snowflake.client.jdbc.SnowflakeDriver | ||
| JDBC URL* | None. | Required. Enter the JDBC driver connection string that you want to use, based on the Database you are connecting to. Use the appropriate syntax provided below.
Alternatively, for Redshift, Azure Synapse, and Databricks Lakehouse Platform, you can make use of the Username, Password, and Database Name fields, along with the Advanced Properties > URL Properties field set to provide the parameters required for building your JDBC URL. See Passing your JDBC URL for more information. Avoid passing Password inside the JDBC URL If you specify the password inside the JDBC URL, it is saved as it is and is not encrypted. We recommend passing your password using the Password field provided, instead, to ensure that your password is encrypted. Default Value: N/A Example: jdbc:snowflake://xy12345.us-east-2.aws.snowflakecomputing.com, jdbc:snowflake://xy12345.east-us-2.azure.aws.snowflakecomputing.com | ||
Use Token Based Authentication | Database Type is Databricks Lakehouse Platform | Select this checkbox to use token-based authentication for connecting to the target database (DLP) instance. Activates the Token field. Default value: Selected Example: Not selected | ||
| Username* | When Use Token Based Authentication check box is not selected. | Enter the username provided for your database account. In case the Database Type is Databricks Lakehouse Platform and the Use Token Based Authentication check box is not selected, you can enter the value token in this field and provide the token's value in the Password field. Default value: N/A Example: Bigdatasnaplogic | ||
| Password* | When Use Token Based Authentication check box is not selected. | Enter the password for the username specified above. In case the Database Type is Databricks Lakehouse Platform and the Use Token Based Authentication check box is not selected, you can enter the value token in the Username field and provide the token's value in this field. Default value: N/A Example: <Encrypted> | ||
| Token* | When Use Token Based Authentication check box is selected. | Enter the token value for accessing the target database/folder path. Default value: N/A Example: <Encrypted> | ||
| Warehouse* | Database Type is Snowflake | Enter the name of the Snowflake warehouse that you want to use. Default value: N/A Example: 12345abcdefghikj1km2345no | ||
| Default Database Name* | String | Enter the name of the database to use by default. This database is used if you do not specify one in the ELT Select, ELT Insert-Select, or ELT Merge Into Snaps. Default value: N/A Example: EMPLOYEEDB | ||
| DBFS Folder path (source for loading Databricks table) | Database Type is Databricks Lakehouse Platform | Required for ELT Load Snap. Specify the fully qualified path to a target folder in your DBFS instance. It should begin with / which denotes the DBFS Root folder. If DBFS path has a mount point included (to a folder in S3 or Azure Blob Storage or ADLS Gen2 Storage), this field assumes that the specified external data folder is mounted on to DBFS path already. For example, if /mnt/mnt_point _to_s3/csv is the specified path to DBFS folder, this field assumes that you have already created Default value: N/A Example: /my_DBFS/mounted0408_folder | ||
| BigQuery Authentication Types* | Database Type is BigQuery | Select the authentication type that you use to connect to your Google BigQuery instance. It can be one of the following:
Default value: Service Account Example: OAuth 2.0 Access Token Account | ||
| Service Account Email* | Database Type is BigQuery, BigQuery Authentication Types is Service Account | Specify the Google email account that is associated with your Google Cloud project. You would need the associated service account key file to authenticate this account. See Creating a Service Account and Authenticating with a service account key file for more information. Default value: N/A Example: my_service_account@domain.com | ||
| Service Account Key File Path* | Database Type is BigQuery, BigQuery Authentication Types is Service Account | Specify the SLDB location (file path) of the service account key file associated with this service account. Default value: N/A Example: /my_SA/key_file/ | ||
| OAuth 2.0 Access Token | Database Type is BigQuery, BigQuery Authentication Types is OAuth 2.0 Access Token Account | Enter the OAuth 2.0 Access Token pertaining to your BigQuery instance. See Obtaining Access Tokens for the steps to generate and use this access token. Using OAuth2 Access Tokens from BigQuery An OAuth2 Access Token generated for Google BigQuery is valid for 60 minutes. To be able to run SQL queries after the token has expired, generate and enter another Access Token in this field. Default value: N/A Example: ya29.Ci9deZOky9V36Tz497HY1chAA2sA8J_wM8e5FnY9rJg551153GQWGbleO-y9apjLFg | ||
| OAuth2 Refresh Token | Database Type is BigQuery, BigQuery Authentication Types is OAuth 2.0 Refresh Token Account | Provide the OAuth2 Refresh Token string that the Snap can use to automatically generate a valid access token—that you needed to run SQL queries in BigQuery—whenever an access token expires. This method of authentication helps you to avoid constantly updating your Snap accounts in BigQuery ELT Snaps. OAuth2 Refresh Tokens Refresh tokens do not expire until the administrator revokes them. You can use the Refresh Token as many times as necessary to request access tokens. Default value: N/A Example: AA2sA8J_wM8e5FnY9rJg551153GQWGbleO-y9apjLFgya29.Ci9deZOky9V36Tz497HY1ch | ||
| OAuth2 Client ID* | Database Type is BigQuery, BigQuery Authentication Types is OAuth 2.0 Refresh Token Account | Enter the OAuth2 client ID associated with your BigQuery application. The Snap uses this value along with Secret Key and OAuth2 Refresh Token to generate the required Access Token. Default value: N/A Example: 1055912624410-6a29rmvnogteqt99781q0gm4vp2k7v9a.apps.googleusercontent.com | ||
| OAuth2 Client Secret* | Database Type is BigQuery, BigQuery Authentication Types is OAuth 2.0 Refresh Token Account | Default value: N/A Example: bOqUqFQdusfInjfDlh2FDtbD | ||
| Source Location* | Database Type is Snowflake, Redshift or BigQuery | Select the source data warehouse from which to load data into the target database. You must configure this field if you want to use the ELT Load Snap. Available options are:
Default value: None Example: S3, Azure, Google Cloud Storage | ||
| Authentication | Source Location is S3, Azure, or Google Cloud Storage | Select the authentication method to use for the loaded data. Available options are:
Default value: Source Location Credentials Example: Storage Integration | ||
| Storage Integration | Source Location is S3, Azure, or Google Cloud Storage and Authentication is Storage Integration. | Enter the name of the storage integration in your Snowflake database. Navigate to one of the following links for more information on setting up your Storage Integration in Snowflake. Storage integration is not applicable to the Redshift and Azure Synapse databases. Default value: N/A Example: my_s3_integration, my_azure_integration, my_sf_gcs_integration | ||
| IAM Role | Database Type is Redshift, Source Location is S3, and Authentication is IAM Role. | Enter the IAM role associated with the target Redshift cluster. See Create an IAM Role for details on creating and associating IAM Role with your Redshift cluster. Default value: N/A Example: myiamrole | ||
| Access Key | Source Location is S3 or Amazon Redshift, and Authentication is Source Location Credentials. | Enter the access key ID associated with your AWS S3 account. Default value: N/A Example: ABCDEFGHIJKL1MNOPQRS | ||
| Secret Key | Source Location is S3 or Amazon Redshift, and Authentication is Source Location Credentials. | Enter the client secret key associated with your AWS S3 account. Default value: N/A Example: aBcdeFGhiJKLM/N1OPQRS/tUvWxyZABCDEFGHIJKLMN | ||
| SAS Token | Source Location is Azure, and Authentication is Source Location Credentials. | Enter the SAS token part of the SAS URI associated with your Azure storage account. See Getting Started with SAS for details. Default value: N/A Example: ?sv=2020-08-05&st=2020-08-29T22%3A18%3A26Z&se=2020-08-30T02%3A23%3A26Z&sr=b&sp=rw&sip=198.1.2.60-198.1.2.70&spr=https&sig=A%1DEFGH1Ijk2Lm3noI3OlWTjEg2tYkboXr1P9ZUXDtkk%3D | ||
| Session Access Key | Source Location is S3, Database Type is Snowflake, Redshift or Databricks Lakehouse Platform, and Authentication is Source Location Session Credentials. | Enter the access key ID associated with your AWS S3 account. Default value: N/A Example: ABCDEFGHIJKL1MNOPQRS | ||
| Session Secret Key | Source Location is S3, Database Type is Snowflake, Redshift or Databricks Lakehouse Platform, and Authentication is Source Location Session Credentials. | Enter the client secret key associated with your AWS S3 account. Default value: N/A Example: aBcdeFGhiJKLM/N1OPQRS/tUvWxyZABCDEFGHIJKLMN | ||
| Session Token | Source Location is S3, Database Type is Snowflake, Redshift or Databricks Lakehouse Platform, and Authentication is Source Location Session Credentials. | Enter the session token value when the authorization to access the S3 folder is based on Security Token Service (STS) based temporary credentials. Default value: N/A Example: A%1DEFGH1Ijk2Lm3noI3OlWTjEg2tYkboXr1P9ZUXDtkk%3D | ||
| Storage Account | Source Location is S3. | Enter the name of your Azure storage account. Storage Account is not applicable to the Redshift database. Default value: N/A Example: employeedata | ||
| S3 Bucket | Source Location is S3 or Amazon Redshift. | Enter the name of the bucket from which to load the data. Default value: N/A Example: employeedata | ||
| S3 Bucket Region | Database Type is Redshift and Source Location is S3. | Select the region of your Redshift cluster if it is different from the region of the S3 bucket. Available options are:
Default value: Default Example: us-east-1, us-east-2 | ||
| S3 Folder | Source Location is S3 or Amazon Redshift. | Enter the name of the folder in the S3 bucket specified above where the source files are located. Default value: N/A Example: hrdepartment | ||
| Transfer Display Name* | Database Type is BigQuery, Source Location is Amazon Redshift | Specify the display name for the data transfer configuration you created for the load operation. Default value: N/A Example: rs_bq_transfer_one | ||
| Redshift Jdbc Url* | Database Type is BigQuery, Source Location is Amazon Redshift | Specify the JDBC URL needed to locate and connect to the Redshift source data.
Default value: N/A Example: jdbc:redshift://endpoint:port/<databaseName> | ||
| Redshift DB User Name* | Database Type is BigQuery, Source Location is Amazon Redshift | Enter the user name to access your Redshift database. SnapLogic appends this user name to build the final JDBC URL. Default value: N/A Example: rs_user_johndoe | ||
| Redshift DB Password* | Database Type is BigQuery, Source Location is Amazon Redshift | Enter the password associated with the above user name. SnapLogic appends this password to build the final JDBC URL. Default value: N/A Example: SJvcsDjhfASD%^ | ||
| External Location (For Azure Synapse only) | Database Type is Azure Synapse. | Select the source data location from which to load data into the target database. You must configure this field if you want to use the ELT Load Snap. Available options are:
Default value: Blob Storage Example: Azure Data Lake Gen2 | ||
| External Storage Endpoint (For Azure Synapse only) | Database Type is Azure Synapse. | Enter the end point path for the selected external location. You must configure this field if you want to use the ELT Load Snap. Default value: N/A Example: .blob.core.windows.net (for Blob Storage), .dfs.core.windows.net (for ADLS Gen2) | ||
| Storage Account (For Azure Synapse only) | Database Type is Azure Synapse. | Enter your Account name to access the selected Azure external storage location. You must configure this field if you want to use the ELT Load Snap. Default value: N/A Example: adlsgen2v02 | ||
| Azure Container | Source Location is Azure. | Enter the name of the container in the Azure storage account. Azure Container is not applicable to the Redshift database. Default value: N/A Example: hrdepartment | ||
| Azure Folder | Source Location is Azure. | Enter the relative path for the folder within the container specified above. Leave this field blank to use all the folders in the specified container. Azure Folder is not applicable to the Redshift database. Default value: N/A Example: salaries | ||
| Google Cloud Storage (GCS) Bucket | Source Location is Google Cloud Storage and Authentication is Storage Integration. | Enter the name of the GCS bucket from which to load the data to your Snowflake database. Default value: N/A Example: elt_gcs_bucket_1 | ||
| Google Cloud Storage (GCS) Folder | Source Location is Google Cloud Storage and Authentication is Storage Integration. | Enter the name of the folder in the GCS bucket where the source files are located. Default value: N/A Example: elt_gcs_bucket_1_CSV_Files | ||
| Azure Auth Type (For Azure Synapse only) | Database Type is Azure Synapse. | Select the authentication type to use for accessing the selected Azure external storage location. Then, provide the values for Azure Secret, Storage Key fields for the selected authentication type. See COPY INTO (Transact-SQL) in Microsoft Docs for more information on these authentication types. Available options are:
Default value: Storage Account Key Example: AAD User | ||
| Azure Secret (For Azure Synapse only) | Azure Auth Type is Storage Account Key, Shared Access Signature, or Service Principals. | Enter the Azure Secret corresponding to the selected authentication type. See COPY INTO (Transact-SQL) in Microsoft Docs for more information on the expected values for this field. Default value: N/A Example: UvhVF65Bukk9hVF65BuUvhVF | ||
| Storage Key (For Azure Synapse only) | Azure Auth Type is Shared Access Signature, Managed Identity, or Service Principals. | Enter the storage access key value corresponding to the Azure account mentioned in Storage Account field. See COPY INTO (Transact-SQL) in Microsoft Docs for more information on the expected values for this field. This field is needed only when you want to define the File Name Pattern in the ELT Load Snap to locate and read the file/s from the Azure Folder path. Else, leave it blank. Default value: N/A Example: ufv!befDIuf#fnb$KH&_hweuf | ||
| Client ID | Azure Auth Type is AAD User. | Enter the Client ID of the application created in the Azure Active Directory portal -https://portal.azure.com. This field is needed only when you want to define the File Name Pattern in the ELT Load Snap to locate and read the file/s from the Azure Folder path. Else, leave it blank. Default value: N/A Example: hewr42ap-32jd-pd95-ms38-b342bnasdh80 | ||
| Client Secret | Azure Auth Type is AAD User. | Enter the Client ID of the application created in the Azure Active Directory portal - https://portal.azure.com. This field is needed only when you want to define the File Name Pattern in the ELT Load Snap to locate and read the file/s from the Azure Folder path. Else, leave it blank. Default value: N/A Example: jhweufv!befDIufwb*dsfwujfnb$KH&_ | ||
| Tenant ID | Azure Auth Type is AAD User. | Enter the Tenant ID of the application created in the Azure Active Directory portal - https://portal.azure.com. This field is needed only when you want to define the File Name Pattern in the ELT Load Snap to locate and read the file/s from the Azure Folder path. Else, leave it blank. Default value: N/A Example: b342bnas-he38-apms-dhjd-pd95wr423280 | ||
| Advanced Properties | Other parameters that you want to specify as URL properties. See the following resources for a list of parameters that can be specified in this field set.
In case of Snowflake, DO NOT configure parameters that are already present in the Account Properties field set. For example:
This field set consists of the following fields:
| |||
| URL Properties | String/Integer | The account parameter's name and its corresponding value. Click + to add more rows. Add each URL property-value pair in a separate row. Specify the name of the parameter in the URL Property Name field and its value in the URL Property Value field. | ||
Click Validate after entering the required details to ensure that all fields have been filled accurately. Click Apply to save the settings.
Account Validation when using Pipeline parameters
If you have used Pipeline parameters or expressions to define values for the account fields above, the account validation (done by clicking the Validate button) is not supported. However, the Snaps that use this account may connect to the endpoint successfully depending on the accuracy and validity of the expressions and parameters used.
Supported JDBC JAR Versions
You can configure your ELT Database Account to automatically use an appropriate JDBC JAR file for connecting to your target database and performing the load and transform operations.
| Supported CDW | Certified JDBC JAR File |
|---|---|
| Azure Synapse | mssql-jdbc-8.4.1.jre8.jar |
| BigQuery | SimbaJDBCDriverforGoogleBigQuery42_1.2.19.1023.zip |
| Databricks Lakehouse Platform (DLP) | SimbaSparkJDBC42-2.6.21.1021.jar |
| Redshift | redshift-jdbc42-1.2.43.1067.jar |
| Snowflake | snowflake-jdbc-3.12.16.jar |
Using Alternate JDBC JAR File Versions
We recommend you to let the ELT Snaps use the listed JAR file versions. However, you may use a different JAR file version of your choice.
Passing your JDBC URL
Order of Precedence
The parameter values for the URL used to connect to your target database are governed by the following order of precedence:
- JDBC URL field
- Snap Properties (including Advanced Properties)
- Default values
Default Properties set internally
The following properties are passed in the URL internally, by default:
| Target Database | Parameter | Value |
|---|---|---|
| Snowflake | None | None |
| Redshift | tcpKeepAlive | true |
| Azure Synapse | encrypt | true |
trustServerCertificate | false | |
hostNameInCertificate | *.database.windows.net | |
loginTimeout | 300 |
Specific Scenarios
When setting default values for the Database Name, Username, and Password fields:
As a best practice, ensure that the Default Database Name provided in the Snap's properties and the database name in the JDBC URL field match.
Else, make sure that both the database names exist.
However, the username and password from the JDBC URL take precedence over the values provided in the respective fields.
Locating the JDBC URL for Redshift database
Perform the following steps to locate and use the JDBC URL for your Redshift database instance.
- Log into your AWS Console.
- Click Amazon Redshift.
- Click Clusters in the left navigation menu. Ensure that your IT administrator has provided access to the Redshift cluster that you want to use.
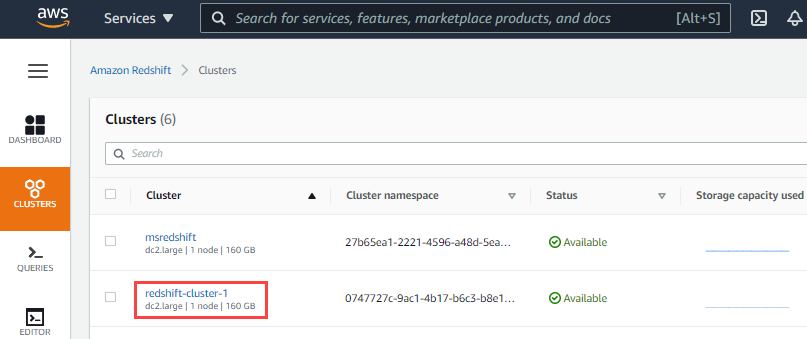
- Click the Cluster name hyperlink in the list of clusters provided.
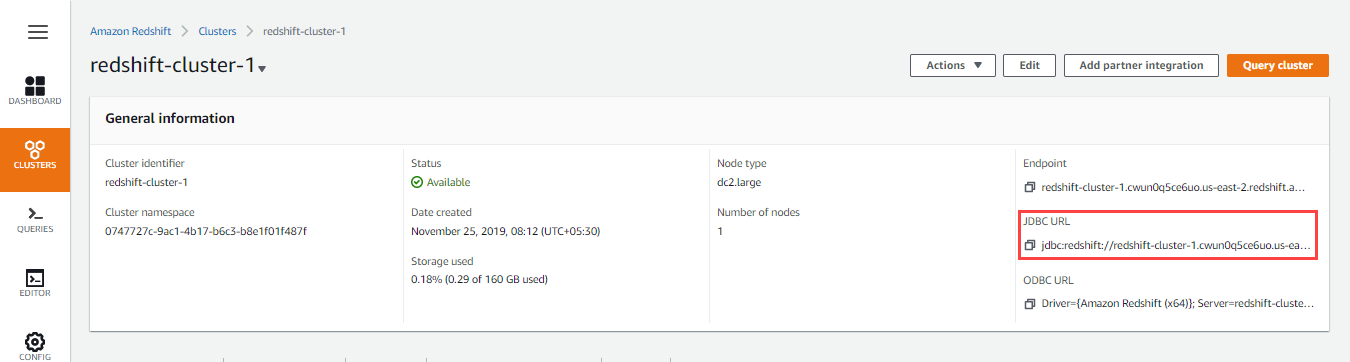
- Click
 next to the JDBC URL to copy the JDBC URL displayed. Paste this URL in your Snap's account settings.
next to the JDBC URL to copy the JDBC URL displayed. Paste this URL in your Snap's account settings.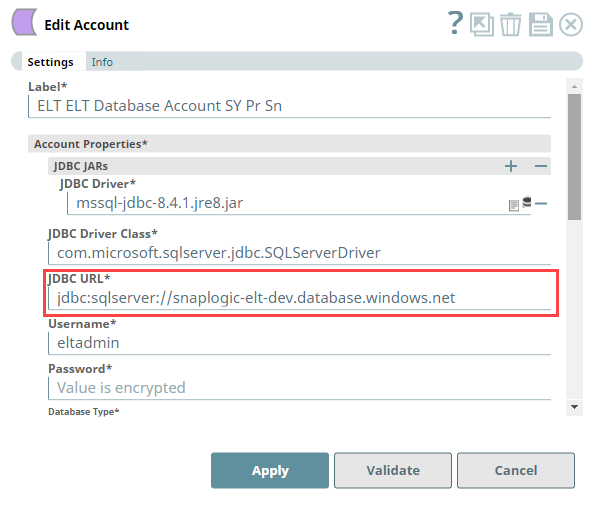
Locating the JDBC URL for Azure Synapse database
Perform the following steps to locate and use the JDBC URL for your Azure Synapse database instance.
- Log into portal.azure.com.

- Click SQL Databases.
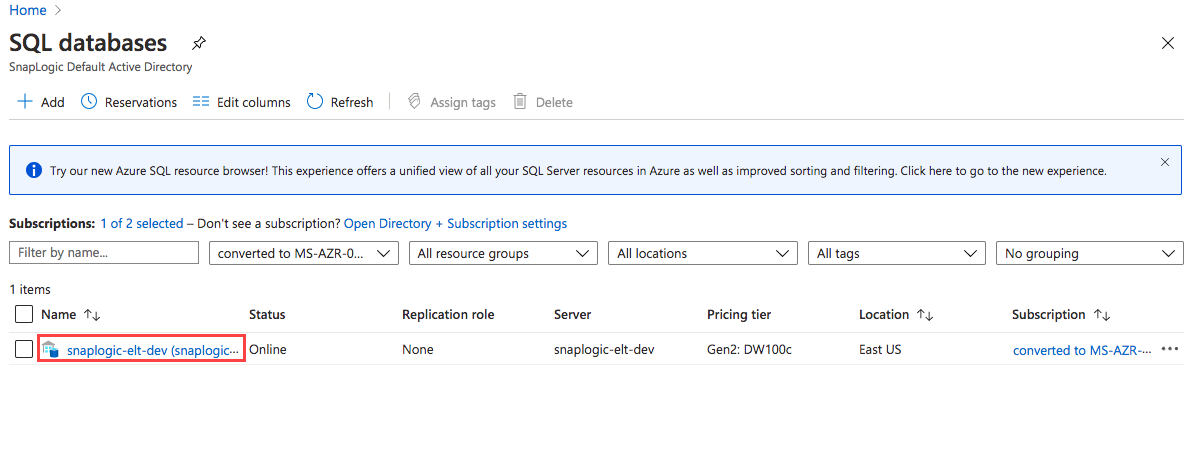
- Click on the Database configured for your organization.
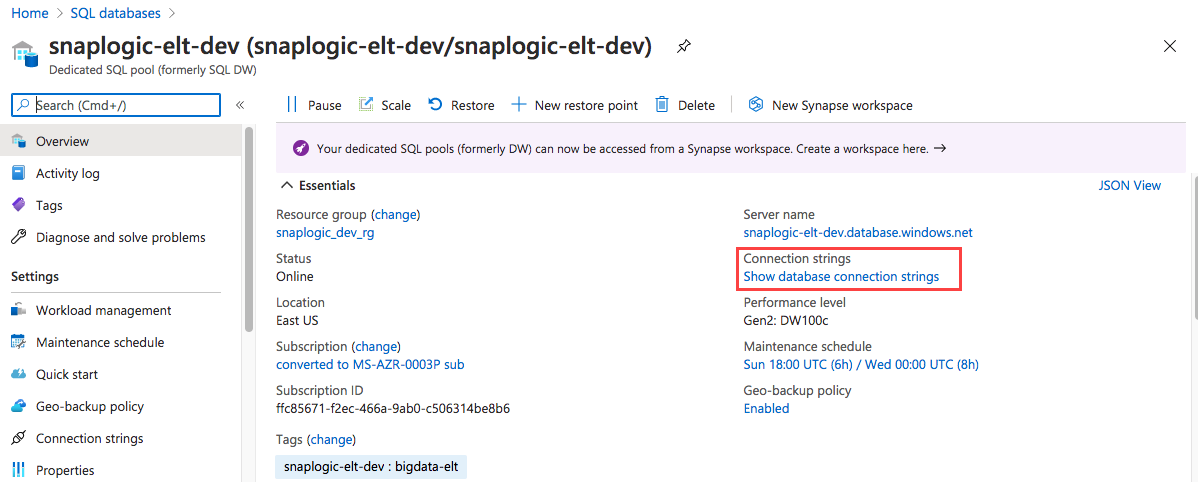
- Click Show Database Connection Strings and click JDBC to get the actual connection string.
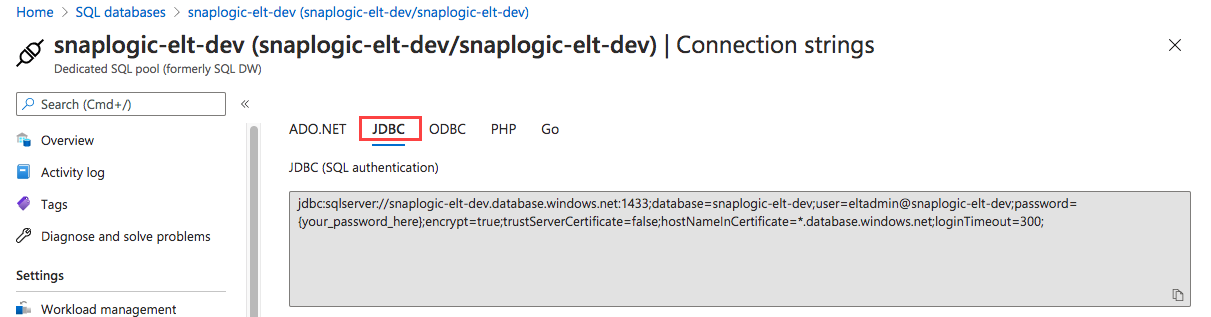
- Click
 to copy the JDBC URL displayed. Paste this URL in your Snap's account settings.
to copy the JDBC URL displayed. Paste this URL in your Snap's account settings.
Alternatively, you can separately pass the base URL in the JDBC URL field and the remaining parameters as a combination of the Snap's account fields and Advanced Properties > URL Properties.
Spark settings required for supporting ELT on DLP
Ensure to configure the following Spark configuration properties/settings for your Azure Databricks cluster. Refer Configuring Clusters for Azure Databricks for information on defining Spark Configuration Properties.
Spark Config Property Name | Expected Property Value |
|---|---|
spark.sql.ansi.enabled | true |
spark.databricks.delta.logStore.crossCloud.fatal | false |
spark.databricks.delta.schema.autoMerge.enabled | true |
spark.sql.legacy.timeParserPolicy | LEGACY |
The following image depicts the Spark configuration properties defined for a sample DLP instance.

Troubleshooting
None.
Example
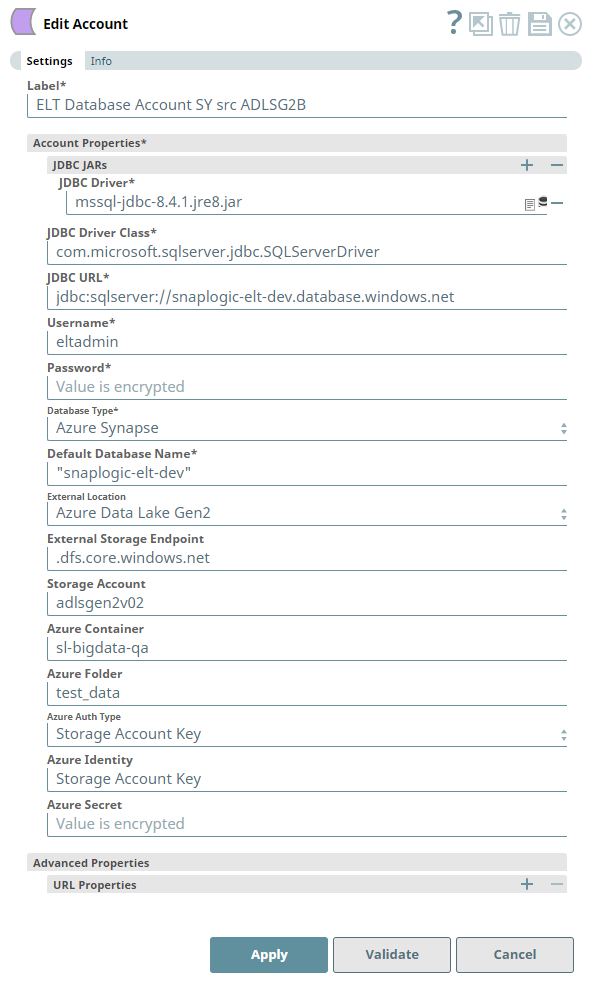
Configuring the ELT Database Account for connecting to a Azure Synapse Database
The following Pipeline is designed to extract data from a Parquet file residing in the ADLS Gen2 storage and load it into a new table in the Azure Synapse database.
Snap Settings
The Pipeline uses an ELT Load Snap to define the source Parquet file in the Azure Data Lake Storage and is configured to perform the following functions.
- Create a new table out_sy_elt_load_02 in the specified target database (Azure Synapse).
- Load the data from Parquet file to this newly-created target table based on the table columns specified.
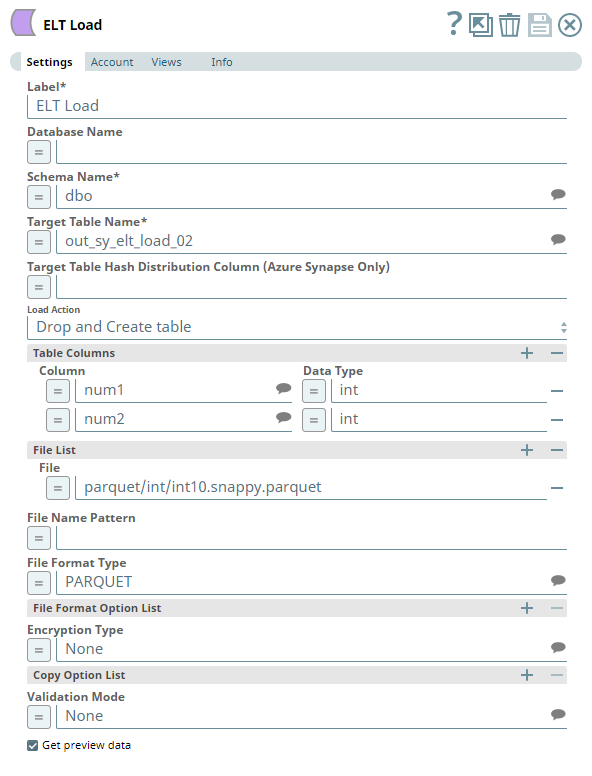
Account Settings
The Pipeline accesses the Parquet file using the Storage Account Key mode of authentication.