On this Page
| Snap type: | Write | ||||||
|---|---|---|---|---|---|---|---|
| Description: | The Snap Performs a bulk load operation from the input view document stream to the target table by using SQLServerBulkCopy API. It uses a memory buffer to send records to the target table instead of a temporary CSV file. The Batch size and Bulk copy timeout values can be used to tune the performance and memory used. ETL Transformations and Data Flow The input document stream is converted to multiple batches, which are bulk-loaded to the target table by using SQLServerBulkCopy API. The Snap converts the input data values according to the corresponding SQL Server column data types to Java class objects which SQLServerBulkCopy accepts. When facing a com.microsoft.sqlserver.jdbc.SQLServerException error, refer to Errors 4000 - 4999 for more details on the error code.Input & Output
While trying to access a column name that contains specific characters as supported by Azure SQL like $, #, @ etc., such field names should be enclosed in the square brackets. | ||||||
Prerequisites: | SQL Server JDBC driver is required in the Azure SQL database account. SQL Server JDBC driver version 4.1 and older do not support SQLServerBulkCopy API. | ||||||
Limitations and Known Issues: |
| ||||||
| Configurations: | Accounts and Access This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Azure SQL Account for information on setting up this type of account. Views
| ||||||
| Troubleshooting: | None. | ||||||
Settings | |||||||
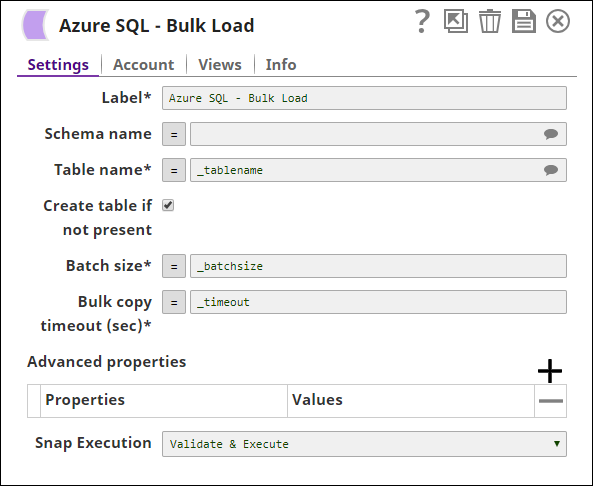
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | ||||||
Schema Name | The database schema name. In case it is not defined, then the suggestion for the table name will retrieve all tables names of all schemas. The property is suggestible and will retrieve available database schemas during suggest values. The values can be passed using the pipeline parameters but not the upstream parameter. Example: SYS Default value: None | ||||||
Table Name | Required. The target table to load the incoming data into. The values can be passed using the pipeline parameters but not the upstream parameter. Example: users Default value: None | ||||||
| Create table if not present | Select this check box to create target table in case it does not exist; else the system throws "table not found" error.
Default value: Deselected This should not be used in production since there are no indexes or integrity constraints on any column and the default varchar() column is over 30k bytes. Due to implementation details a newly created table is not visible to subsequent database Snaps during runtime validation. If you wish to immediately use the newly updated data you must use a child pipeline invoked via a Pipe Exec Snap. | ||||||
Batch size | Sets the number of rows in each batch. Example: 1000 Default value: 10000 | ||||||
Bulk copy timeout (sec) | Sets the number of seconds for each batch operation to complete before it times out. A value of 0 indicates no limit; the bulk copy will wait indefinitely. Default value: 60 | ||||||
| Advanced properties | The following additional options for SQLServerBulkCopy are available (true or false, default: false). Check constraints - Sets whether constraints are to be checked while data is being inserted or not. Fire triggers - Sets whether the server should be set to fire insert triggers for rows being inserted into the database. Keep identity - Sets whether or not to preserve any source identity values. Keep nulls - Sets whether to preserve null values in the destination table regardless of the settings for default values, or if they should be replaced by default values (where applicable). Table lock - Sets whether SQLServerBulkCopy should obtain a bulk update lock for the duration of the bulk copy operation. Use internal transaction - Sets whether each batch of the bulk-copy operation will occur within a transaction or not. Refer to the Microsoft document for further detail. | ||||||
Snap execution | Select one of the three modes in which the Snap executes. Available options are:
|
In a scenario where the Auto commit on the account is set to true, and the downstream Snap does depends on the data processed on an Upstream Database Bulk Load Snap, use the Script Snap to add delay for the data to be available.
For example, when performing a create, insert and a delete function sequentially on a pipeline, using a Script Snap helps in creating a delay between the insert and delete function or otherwise it may turn out that the delete function is triggered even before inserting the records on the table.
Examples
Basic Use Case
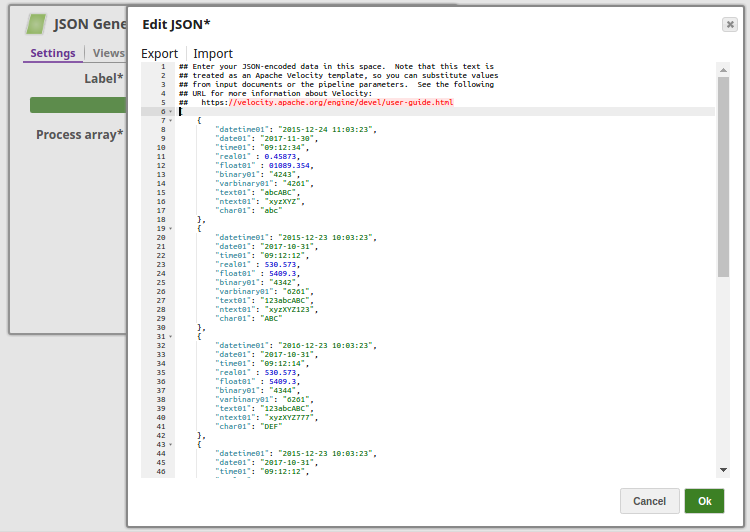
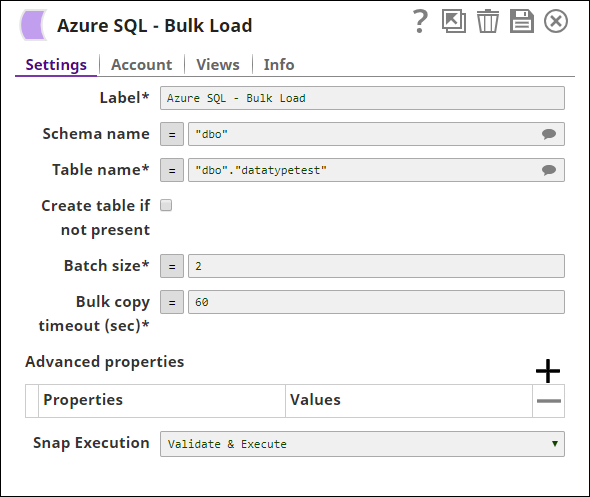
In this pipeline, the Azure SQL Bulk Load Snap loads the data from the input stream. The data is bulk loaded into the table "dbo"."datatypetest".
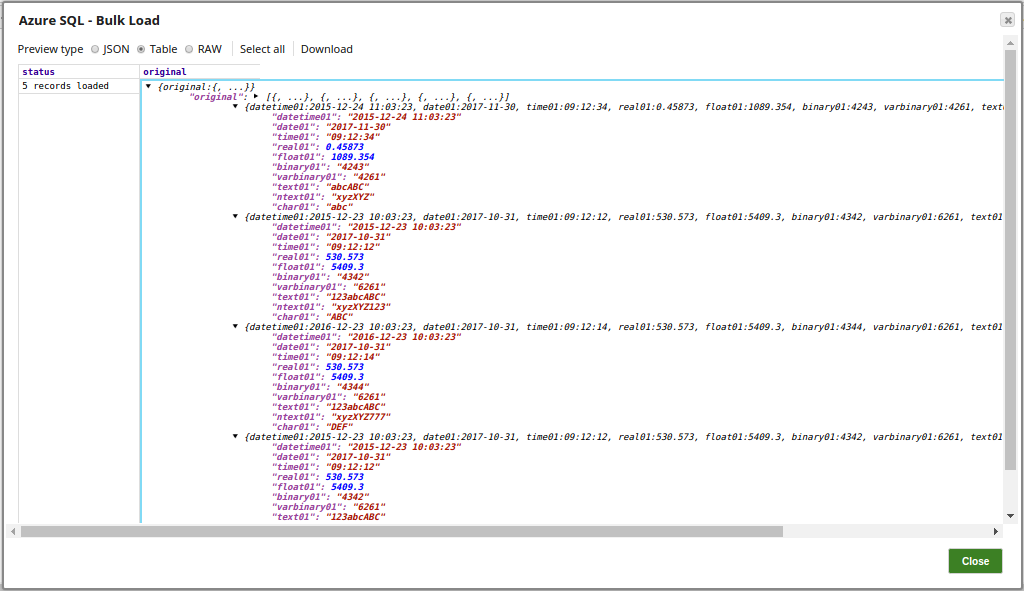
The successful execution of the pipeline displays the below output preview with the status of records loaded:
Typical Snap Configurations
The key configurations for the Snap are:
- Without Expression: Directly passing the values via the CSV Generator and the Mapper Snaps.
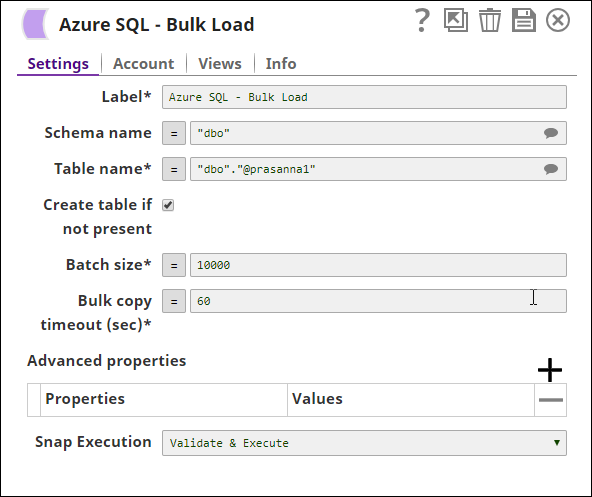
In the below pipeline, the values are passed via the upstream for the Azure Bulk Load Snap to update the table, "dbo"."@prasanna1" on the Azure.
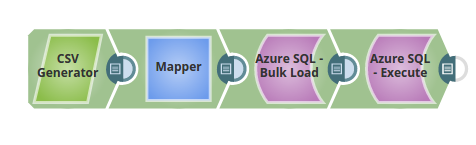
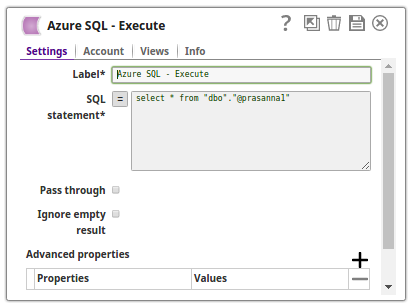
The Azure Bulk Load Snap Loads the data into the table and the Azure Execute Snap reads the table contents respectively:
With Expressions
- Pipeline Parameter: Pipeline parameter set to pass the required table name to the Azure SQL Bulk Load Snap.
In the below pipeline:
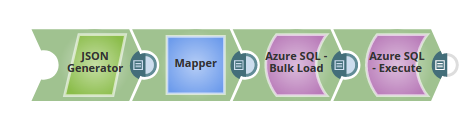
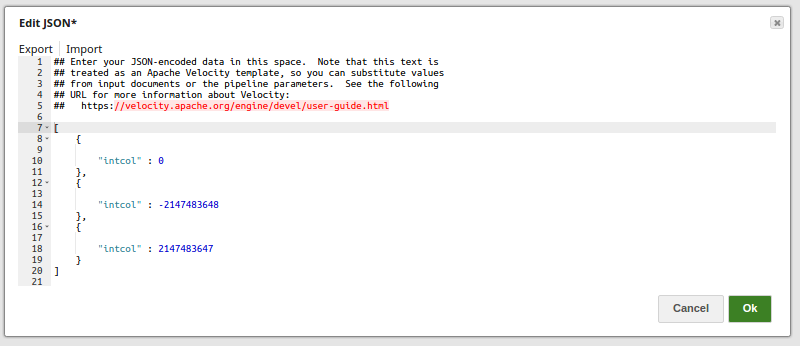
- The JSON Generator Snap passes the values to be added to a table intcol.
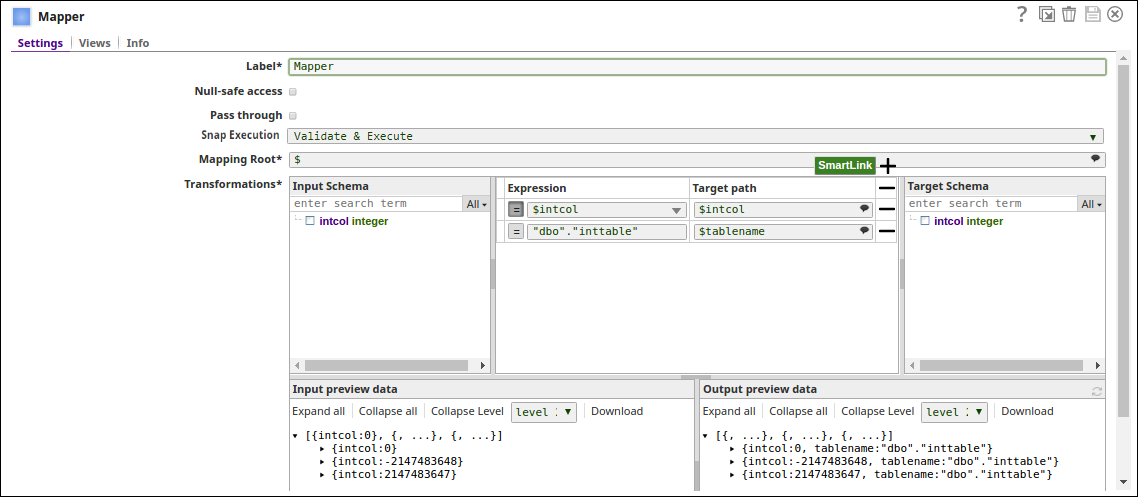
- The Mapper Snap passes the values to the table intcol and "dbo"."inttable" to the target table, tablename.
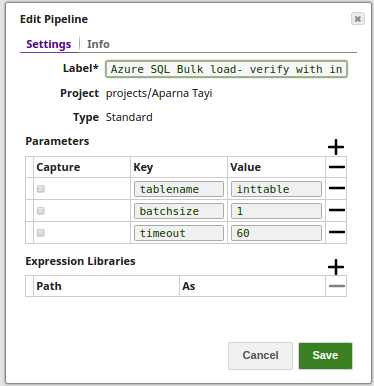
- The pipeline parameters are set with values for Tablename, Batchsize and Timeout.
- The Bulk Load Snap loads the records into the _tablename, with _batchsize (as 1) and _timeout (as 60) using the pipeline param values.
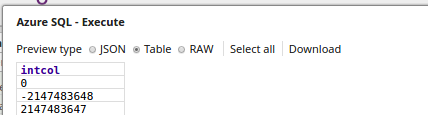
- The Execute Snap reads the data from the table, inttable. The output preview displays the three records as added via the JSON Generator Snap.
Advanced Use Case
The following describes a pipeline, with a broader business logic involving multiple ETL transformations, that shows how typically in an enterprise environment, Azure SQL Bulk Load functionality is used. The pipeline download is available below.
In the below pipeline, the records from a table on the SQL Server are loaded into a table on the Azure SQL.The Azure SQL Execute Snap reads the records the loaded records on the Azure SQL table.
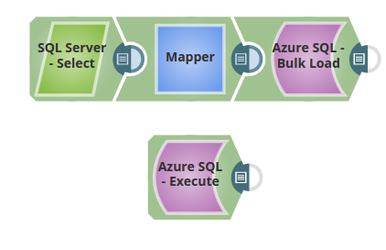
Extract: The SQL Server Select reads the records form a table on SQL Server.
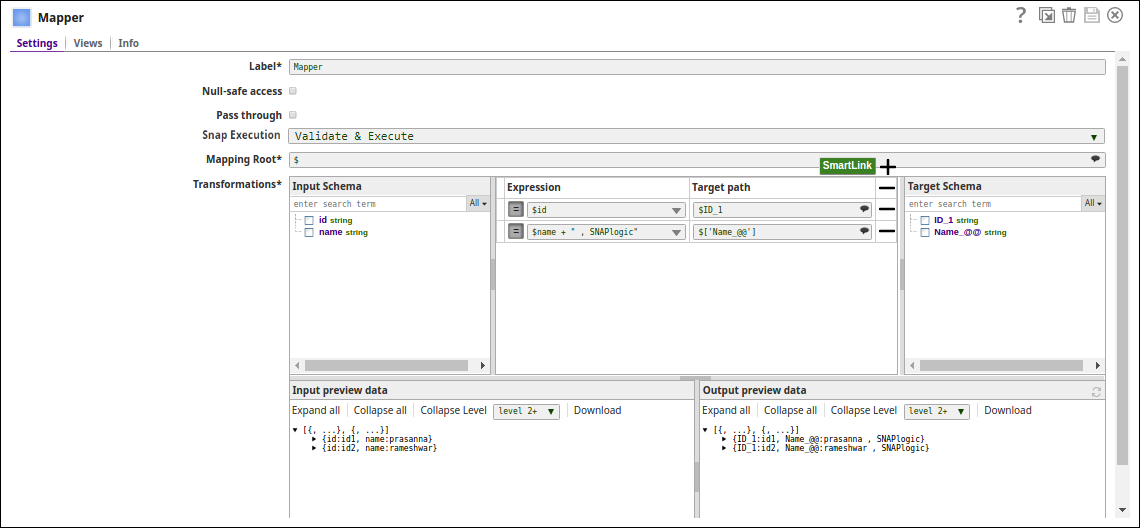
Transform: The Mapper Snap maps the metadata from the input schema (SQL Server) to the output schema (Azure SQL)
Load: Azure SQL Bulk Load Snap loads the records into the Azure SQL table.
Read: The Azure Execute Snap reads the loaded records on the Azure SQL table.
A similar enterprise scenario where the records from the Oracle server are loaded into the Azure SQL Server. The loaded records are transformed to JSON and written to a file. The Azure SQL Execute Snap reads the records from the table on the Azure SQL.
The pipeline download is available below.
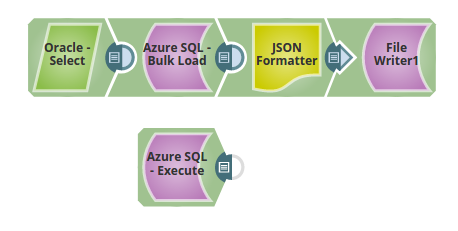
Extract: The Oracle Select reads the records form a table on the Oracle Server.
Transform: The JSON Formatter Snap transforms the output records in to a JSON format and writes them to a file using the File Writer Snap.
Load: Azure SQL Bulk Load Snap loads the records into the Azure SQL table.
Read: The Azure Execute Snap reads the loaded records on the Azure SQL table.