Atlassian uses cookies to improve your browsing experience, perform analytics and research, and conduct advertising. Accept all cookies to indicate that you agree to our use of cookies on your device. Atlassian cookies and tracking notice, (opens new window)
This Snap reads the data from the SQL server table on the Azure.
ETL Transformations & Data Flow
This Snap enables the following ETL operations/flows:
Extracts the complete table data from the SQL Server DB and writes it to a locally created temporary data file. The data is then processed from the data file and written to the output view.
Input & Output
Input: This Snap can have an upstream Snap that can pass a document output view. Such as Structure or JSON Generator.
Output: The Snap outputs one document specifying the records extracted. Any error occurred during the process is routed to the error view.
Bulk Extract requires a minimum of SQL Server 2016 to work properly.
Must install the BCP utility.
Limitations and Known Issues:
The Azure SQL - Bulk Extract Snap fails when using the Active Directory Service Principal Certificate Authentication type because the BCP utility does not support it. We recommend that you use Active Directory Password authentication to connect to Azure SQL.
Configurations:
Account & Access
This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Configuring Azure SQL Accounts for information on setting up this type of account.
Active Directory-based authentication is not supported in Bulk Extract.
Views
Input
This Snap has exactly one document input view.
Output
This Snap has exactly one document output view.
Error
This Snap has at most one document error view and produces zero or more documents in the view.
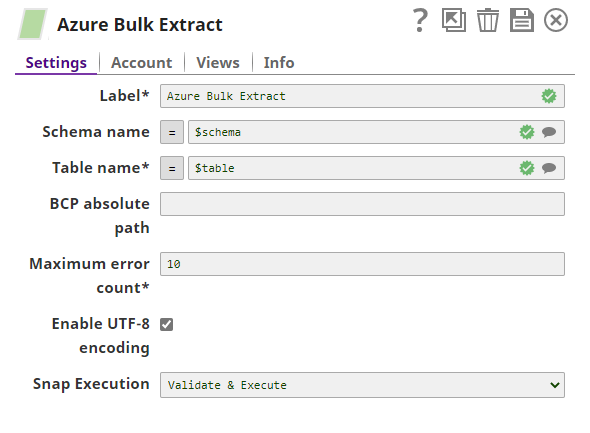
Settings
Label
Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline.
Schema Name
The database schema name. In case it is not defined, then the suggestion for the Table Name will retrieve all tables names from all the schemas. The property is suggestible and will retrieve available database schemas during suggest values.
The values can be passed using the pipeline parameters but not the upstream parameter.
Example: SYS Default value: [None]
Table Name
Required. Table on which to execute the bulk load operation.
The values can be passed using the pipeline parameters but not the upstream parameter.
Example: people
Default value: [None]
Currently, the BCP utility in the Linux environment has a limitation while processing the table names. When loading the data into a selected table and If the table name contains the characters '$%' or '!$', the combination works fine, however, BCP does not support if the table name contains the characters vice-a-versa as'%$' and '$!'.
Examples: Supported by BCP: "dbo"."sqldemo#^&$%"
Not supported by BCP: "dbo"."sqldemo#^&%$"
BCP absolute path
Absolute path of the BCP utility program in JCC's file system. If empty, the Snap will look for it in JCC's environment variable PATH.
Default value: [None]
The path to the BCP executable should include the ".exe" extension to ensure the executable is actually referenced.
Currently, the BCP utility in the Linux environment has a limitation while processing the table names. When loading the data into a selected table and if the table name contains the characters '$%' or '!$', the combination works fine, however, BCP does not support if the table name contains the characters vice-a-versa as'%$' and '$!'.
Examples: Supported by BCP: "dbo"."sqldemo#^&$%" Not supported by BCP: "dbo"."sqldemo#^&%$"
Maximum error count
Required. The maximum number of rows which can fail before the bulk load operation is stopped.
Default value: 10
Enable UTF-8 encoding
Specify whether UTF-8 coding must be enabled or not. If enabled, the Snap updates the BCP command to support UTF-8 encoded characters.
Default value: Selected
Snap Execution
Select one of the three modes in which the Snap executes. Available options are:
Validate & Execute: Performs limited execution of the Snap, and generates a data preview during Pipeline validation. Subsequently, performs full execution of the Snap (unlimited records) during Pipeline runtime.
Execute only: Performs full execution of the Snap during Pipeline execution without generating preview data.
Disabled: Disables the Snap and all Snaps that are downstream from it.
Examples
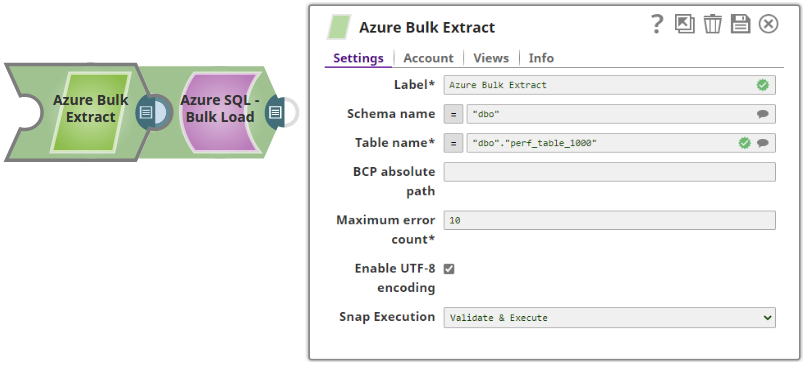
Basic Use Case
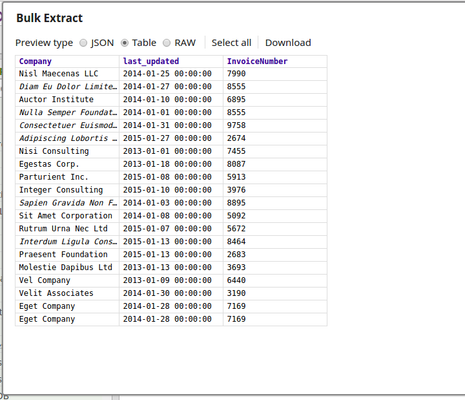
In this pipeline, the Bulk Extract Snap retrieves the data from a table on the Azure Database. The output view in parsed in a JSON format.
Extract: BulkExtract reads the data from the Azure Sql Database.
Transform: JSON Formatter parses the data and converts it into JSON.
The execution displays the following output:
|
Typical Snap Configurations
The key configurations for the Snap are:
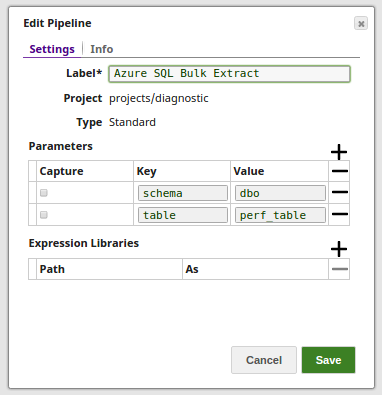
Without Expression: Directly passing the table name from which the data is extracted.
With Expressions
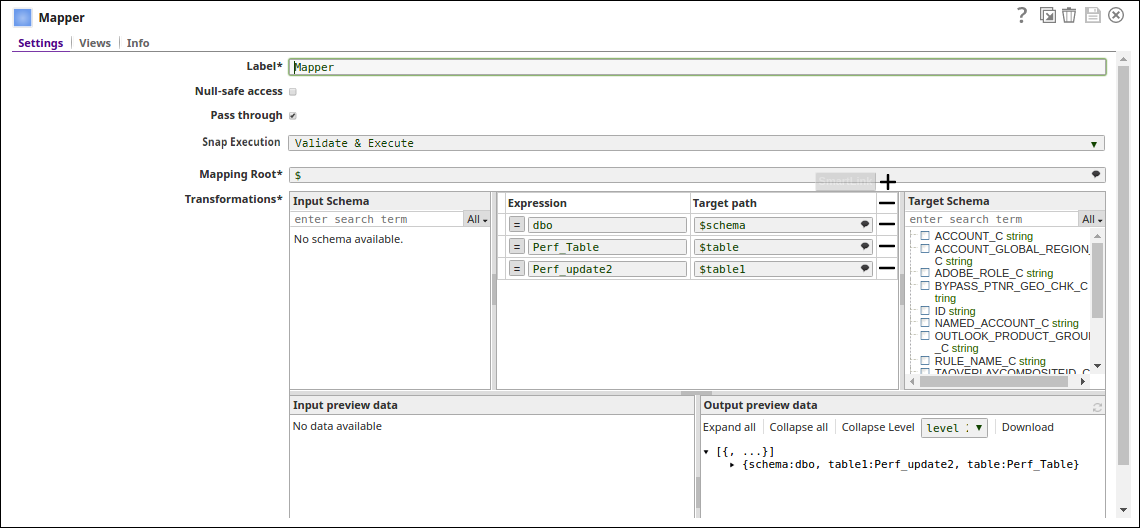
Query from an upstream Snap: The Mapper Snap passing the required Schema and Table name to the Snap.
Pipeline Parameter: Pipeline parameter set to pass the required Schema and Table name to the Snap.
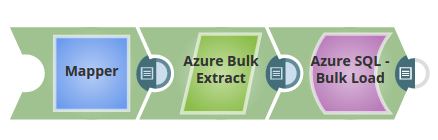
Advanced Use Case
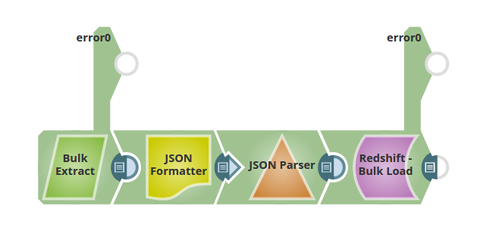
The following describes a pipeline, with a broader business logic involving multiple ETL transformations, that shows how typically in an enterprise environment, Bulk import/read functionality is used.
Pipeline download link is available below.
This pipeline reads and moves data from the Azure SQL database to the Redshift using the Redshift BulkLoad Snap. The data is migrated to Redshift, and the Snap helps in achieving this with high performance and ease of use.
Extract: BulkExtract reads the data from the Azure SQL Database.
Transform: JSON Formatter parses the data and converts it into JSON.
Load: Redshift BulkLoad will loads the data being formatted using the JSON Parser.
Downloads
Important steps to successfully reuse Pipelines
Download and import the pipeline into the SnapLogic application.
Fixed the Null Pointer Exception (NPE) issue in the Azure SQL Snaps. Now, these Snaps display an exception error instead of NPE when the URL properties (key and value) and either key or value are empty.
February 2025
main29887
Stable
Updated and certified against the current SnapLogic Platform release.
November 2024
439patches29842
Latest
Enhanced the Azure SQL Entra and Azure SQL Entra Dynamic Accounts with the ActiveDirectoryServicePrincipalCertificate authentication method for improved security and stronger authentication.
November 2024
main29029
Stable
Updated and certified against the current SnapLogic Platform release.
August 2024
main27765
Stable
Upgraded theorg.json.jsonlibrary from v20090211 to v20240303, which is fully backward compatible.
The Snap displayed an error when the DateTime was of the LocalDateTime type.
The Snap lost milliseconds when the DateTime was in the String data type because the given DateTime format was parsed into a Date object and the timestamp object was created from that date.
Updated and certified against the current SnapLogic Platform release.
November 2023
main23721
Stable
Updated and certified against the current SnapLogic Platform release.
August 2023
main22460
Stable
The Azure SQL Execute Snap now includes a new Query type field. When Auto is selected, the Snap determines the query type automatically.
May 2023
main21015
Stable
Upgraded with the latest SnapLogic Platform release.
May 2023
432patches20967
Latest
Fixed an issue with the connection pool in the Azure SQL accounts, which was affecting the Snap Pack's performance. You should now experience improved performance when using these accounts.
Fixed an issue with the Azure SQL - Bulk Load Snap involving special characters in JDBC URL properties, such as passwords. Special characters are properly escaped now
March 2023
432patches20049
Latest
Intermittent connectivity issues no longer occur when using some Snaps in the Azure SQL Snap Pack. These issues caused the following message to display: The connection is broken and recovery is not possible. The connection is marked by the client driver as unrecoverable. No attempt was made to restore the connection.
February 2023
main19844
Stable
Upgraded with the latest SnapLogic Platform release.
January 2023
431patches19493
Latest
The Azure SQL Active Directory and the Azure SQL Active Directory Dynamic accounts now include an Authentication Mode dropdown list, which allows you to choose the Active Directory authentication mode you would like to use. This enhancement supports Active Directory Service Principal authentication for the Snap Pack.
The Azure Synapse SQL Insert Snap no longer includes the Preserve case-sensitivitycheckboxbecause the database is case-insensitive. The database stores the data regardless of whether the columns in the target table and the input data are in mixed, lower, or upper case.
November 2022
main18944
Stable
The Azure SQL Snap Pack uses the 11.2x driver by default. If you specify any specific driver, ensure that you provide a version higher than 9.1 that is compatible with Microsoft Authentication Library for Java, as this Snap Pack uses the MSAL4J. Otherwise, you may run into issues.
Fixed an issue with the Azure SQL-Stored Procedure Snap where the Snap failed with an Invalid value type error when the stored procedure contained an NCHAR data type.
4.29 Patch
429patches16460
Latest
Fixed an issue with Azure SQL Bulk Load Snap where the Snaplex exited due to insufficient memory when a large number of rows are loaded into the target table and the input data contained a null value for a non-nullable column.
Fixed an issue with the Azure SQL - Update Snap where the Snap failed with an Incorrect syntax error when a column in a table is of NVARCHAR, NCHAR, or NTEXT data type and this column is part of another NVARCHAR, NCHAR, or NTEXT data type column name and the update condition is specified as an expression.
4.28 Patch
428patches15114
Latest
Fixed an issue with the Azure SQL - Bulk Load Snap where the decimal values lost precision when they were inserted into the database.
4.28
main14627
Stable
Upgraded with the latest SnapLogic Platform release.
Upgraded with the latest SnapLogic Platform release.
4.25
main9554
Stable
Upgraded with the latest SnapLogic Platform release.
4.24
main8556
Stable
Enhances the Azure SQL - Stored Procedure to accept parameters from input documents by column keys. If the values are empty, the parameters are populated based on the column keys for easier mapping in the upstream Mapper Snap.
4.23
main7430
Stable
Enhances the Azure SQL - Bulk ExtractSnap by adding a new check box Enable UTF-8 encodingto support UTF-8 encoded characters. This check box allows the Snap to update the BCP command to read the special characters.
4.22 Patch
422Patches6751
Latest
Enhances the Azure SQL - Bulk ExtractSnap by adding a new check boxEnable UTF-8 encoding to support UTF-8 encoded characters. Selected by default, this check box allows the Snap to update the BCP command to read these special characters.
4.22
main6403
Stable
Upgraded with the latest SnapLogic Platform release.
4.21 Patch
421patches6272
Latest
Fixes the issue whereSnowflake SCD2Snap generates two output documents despite no changes toCause-historizationfieldswithDATE, TIME and TIMESTAMPSnowflake data types, and withIgnore unchanged rowsfield selected.
4.21 Patch
421patches6144
Latest
Fixes the following issues with DB Snaps:
The connection thread waits indefinitely causing the subsequent connection requests to become unresponsive.
Fixes the connection issue in Database Snaps by detecting and closing open connections after the Snap execution ends.
4.21
snapsmrc542
Stable
Upgraded with the latest SnapLogic Platform release.
4.20
snapsmrc535
Stable
Upgraded with the latest SnapLogic Platform release.
4.19 Patch
db/azuresql8403
Latest
Fixes an issue with the Azure SQL - Update Snap wherein the Snap is unable to perform operations when:
An expression is used in theUpdate conditionproperty.
Input data contain the character '?'.
4.19
snaprsmrc528
Stable
Enhanced the error handling in PolyBase Bulk Load Snap when writing to a data warehouse. The Snap writes a new blob in the Azure container. This new blob highlights the first invalid row that caused the bulk load operation to fail.
4.18
snapsmrc523
Stable
Upgraded with the latest SnapLogic Platform release.
4.17
ALL7402
Latest
Pushed automatic rebuild of the latest version of each Snap Pack to SnapLogic UAT and Elastic servers.
4.17
snapsmrc515
Latest
Fixes an issue with the Azure SQL Execute Snap wherein the Snap would send the input document to the output view even if the Pass through field is not selected in the Snap configuration. With this fix, the Snap sends the input document to the output view, under the key original, only if you select the Pass through field.
Added the Snap Execution field to all Standard-mode Snaps. In some Snaps, this field replaces the existing Execute during preview check box.
4.16 Patch
db/azuresql7179
Latest
Fixes an issue with the Azure SQL Bulk Extract Snap wherein the Snap fails to process all the metadata information of the input table and schema.
4.16
snapsmrc508
Stable
Upgraded with the latest SnapLogic Platform release.
4.15 Patch
db/azuresql6327
Latest
ReplacedMax idle timeandIdle connection testperiodproperties withMax life timeandIdle Timeout properties respectively, in the Account configuration. The new properties fix the connection release issues that were occurring due to default/restricted DB Account settings.
4.15
snapsmrc500
Stable
Upgraded with the latest SnapLogic Platform release.
4.14
snapsmrc490
Stable
Upgraded with the latest SnapLogic Platform release.
4.13
snapsmrc486
Stable
Upgraded with the latest SnapLogic Platform release.
4.12
snapsmrc480
Stable
Upgraded with the latest SnapLogic Platform release.
4.11 Patch
azuresql4631
Latest
Fixes an issue with the Azure Polybase Bulk Load Snap that failed with "Parse error" when there was no input.
4.11 Patch
db/azuresql4326
Latest
Fixes an issue with the Azure SQL Polybase Bulk Load Snap, that allowed the Snap to load data into a table with identity columns for Azure SQL Data Warehouse instance.
Fixes encoding issue when using a Windows plex, and added a "Encoding" Snap property that allows user to choose input data's encoding from UTF-8 and UTF-16.
4.11
snapsmrc465
Stable
Upgraded with the latest SnapLogic Platform release.
The new Snap,Azure SQL Bulk Loadis developed has been developed to carry out the bulk load function extensively for Azure SQL DB. (The old Azure Bulk Load has been renamed toPolybase BulkLoad which works for on-premise SQL Server and Azure SQL Data Warehouse with polybase functionality).
AddedAuto commitproperty to the Select and Execute Snaps at the Snap level to support overriding of theAuto commitproperty at the Account level.
Added the below accounts:
Azure SQL Active Directory Account
Azure SQL Active Directory Dynamic Account
4.9 Patch
azuresql3078
Latest
Fixes an issue regarding connection not closed after login failure; Expose autocommit for "Select into" statement in PostgreSQL Execute Snap and Redshift Execute Snap
4.9
snapsmrc405
Stable
Upgraded with the latest SnapLogic Platform release.
4.8 Patch
azuresql2750
Latest
Potential fix for JDBC deadlock issue.
4.8
snapsmrc398
Stable
Info tab added to accounts.
Database accounts now invalidate connection pools if account properties are modified and login attempts fail.
4.7 Patch
azuresql2196
Latest
Fixes an issue for database Select Snaps regarding Limit rows not supporting an empty string from a pipeline parameter.
4.7
snapsmrc382
Stable
Upgraded with the latest SnapLogic Platform release.
4.6
snapsmrc362
Stable
Upgraded with the latest SnapLogic Platform release.
4.5.1
snapsmrc344
Stable
Upgraded with the latest SnapLogic Platform release.
4.5
snapsmrc344
Stable
Upgraded with the latest SnapLogic Platform release.
.png?version=1&modificationDate=1501874648747&cacheVersion=1&api=v2&width=452&height=250)