In this article
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
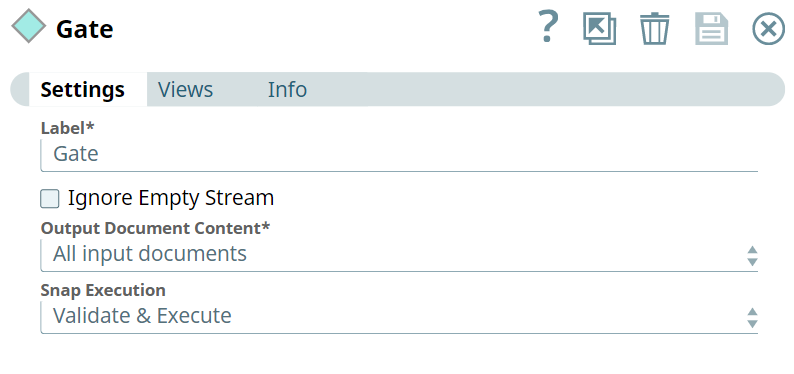
You can use Use this Snap to consolidate all documents from upstream Snaps consolidate multiple input streams into a single output document. Based on the Snap's configuration, , where each input stream displays the count of documents, all records, first record or the final record.
...
is displayed as a label containing the records that were received by that input view.
Note that this Snap does not complete executing until the execution of all upstream Snaps is done.
| Note |
|---|
Unless the Ignore empty stream checkbox is selected, the The Gate Snap always produces an output document, regardless of how many or if no input documents are received. In some Pipeline designs, this functionality can trigger an error message stating, mapped variables are missing, during validation. This error typically occurs when a downstream Snap expects a field based off an output document from the Gate Snap that is empty. To prevent the error from occurring, you can limit empty documents produced by the Gate output from the Gate Snap by inserting a Filter Snap after it with the following expression in the Filter Expression
When you run the Pipeline after adding the Filter Snap with this expression, the Pipeline validates and executes successfully, and the error no longer occurs. |
Prerequisites
If large amounts of data are required for your outputBecause this Snap collects multiple input documents into a single output document, there are system memory limitations, and this Snap should not be used for massive data propagation. If large amounts of data are required, offload your data prior to Snap execution. Instead, and write the your data to a file or database. Upon the completion of ; then, after Snap execution completes, you can use a Reader Snap (such as File Reader and S3 Reader) to read from the offloaded data source.
Support for Ultra Pipelines
Does not support Ultra Pipelines.
Limitations
- This Snap does not have error views. If the Snap fails during validation or execution, documents are not passed through and you receive an error message.You cannot use this Snap for massive data propagation (All input documents), as it collects multiple input documents into a single output document, which leads to severe system memory consumption. To mitigate the memory impact, you can use either of the two alternatives under Output Document Content field.
- Ultra Pipelines: Not supported in Ultra Pipelines.
Troubleshooting
N/A
Snap Input and Output
| Input/Output | Type of View | Number of Views | Examples of Compatible Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
| Input | Document |
|
| One or more documents containing records that must be passed on to downstream Snaps for further processing. |
| Output | Document |
|
| A single document that contains all the records received from the various upstream Snaps. |
Snap Settings
| Parameter Name |
|---|
| Data Type | Description | Default Value | Example |
|---|---|---|---|
| Label | String |
| The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your |
| pipeline. |
Default Value: Gate
Example: Ensure Complete Execution
Select this checkbox to enable the Snap to ignore empty streams received at the input view during Pipeline execution. In such a case, the Snap does not produce any output document; else, the Snap writes an empty array to the output document.
Default Value: Deselected
Example: N/A
Dropdown list
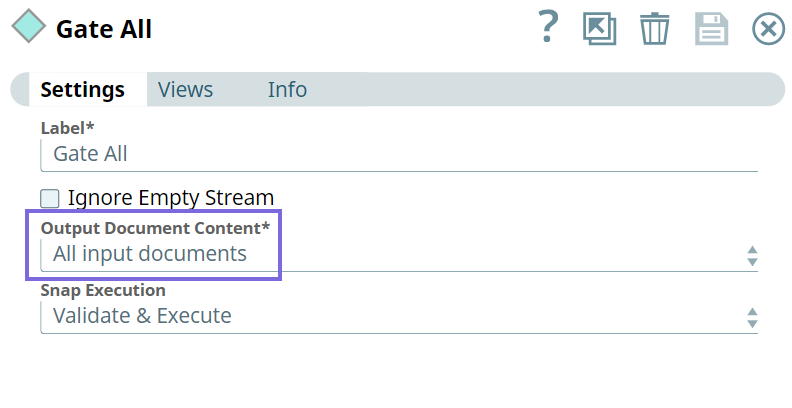
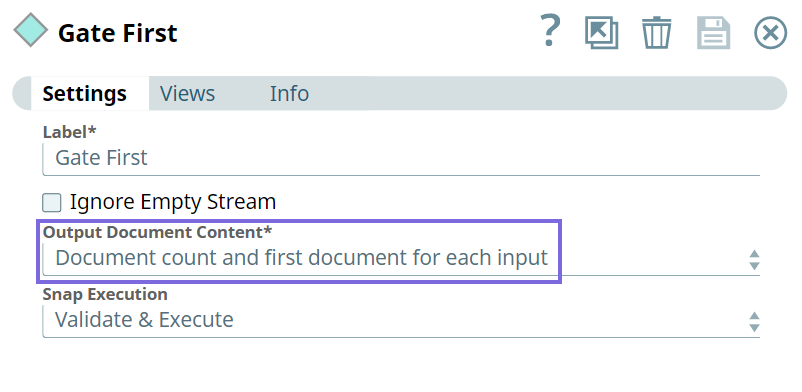
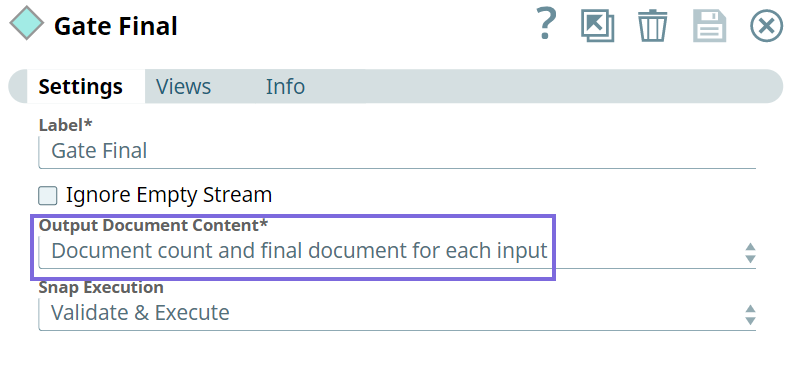
Choose an option to indicate the document count and the specific document to include in the output. This option helps avoid excessive memory consumption. The available options are:
- All input documents: Waits for all the input documents to include in the output.
Document count and first document for each input: Includes document count and the first document from each input in the output. If an input has no documents, the output is displayed as
nullfor the first document from that input.Document count and final document for each input: Includes document count and the final document from each input in the output. If an input has no documents, the output is displayed as
nullfor the final document from that input.
| Info |
|---|
Using All input documents option can consume a lot of memory. If your use case does not require all of this data, consider using other options for Output Document Content, which are less memory intensive. |
For more information, see this example.
Default Value: All input documents
Example: Document count and first document for each input
| N/A | Ensure Complete Execution | |
Snap Execution | String | Specifies the execution type:
|
|---|
|
|
|
|
| Validate & Execute |
| N/A |
Examples
Combining Completed Upstream Execution Output Using the Gate Snap
This example demonstrates how you can use the Gate Snap to combine the complete output of multiple upstream Snaps into a single document. This example also shows how the Gate Snap does not doesn't offer any output until all upstream Snaps have completed executing.
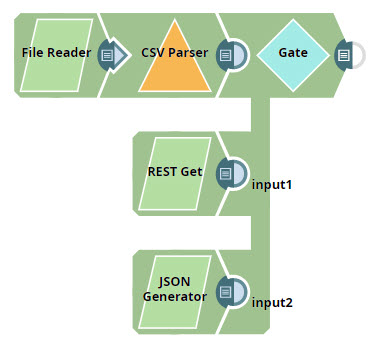
Understanding the Pipeline
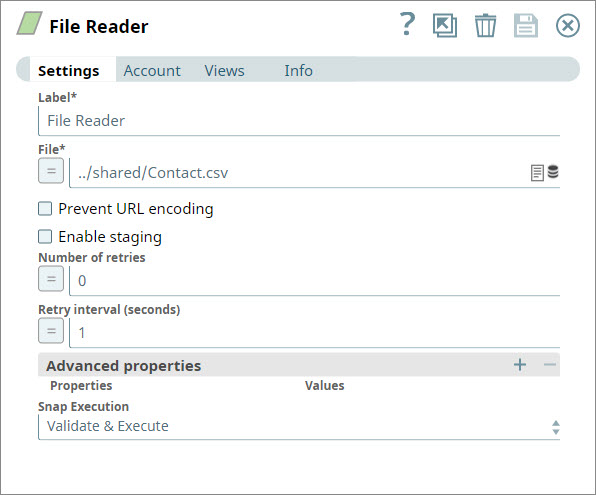
- You add a File Reader Snap to the Pipeline and configure it to read a CSV file containing contact information:
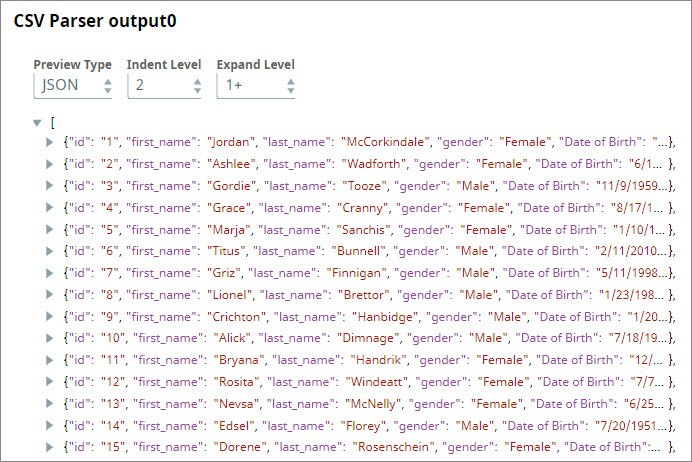
- You add a CSV Parser Snap to read the input binary data as CSV. Once this Snap validatesexecutes, you can view the contents of the file that the File Reader Snap read:
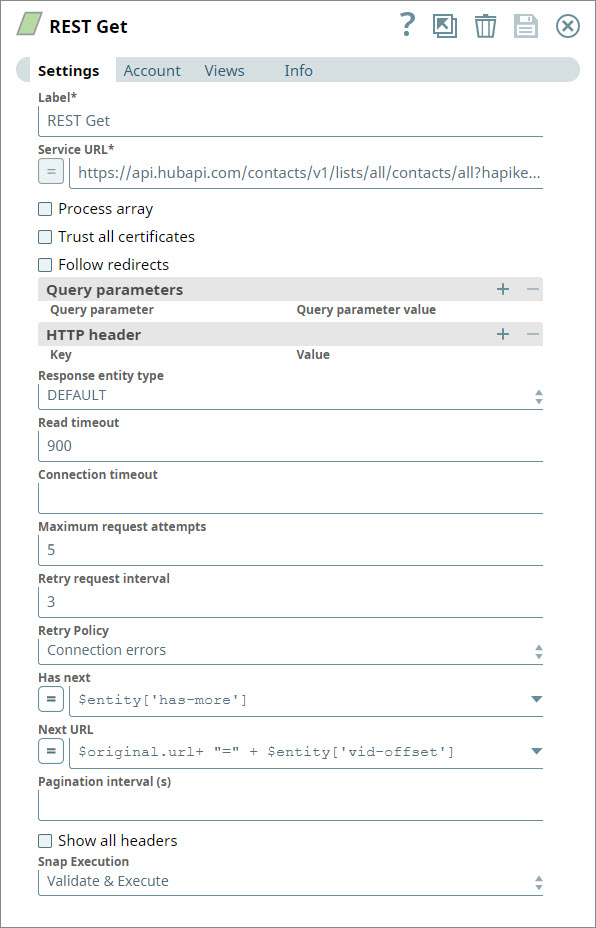
You create a separate branch of the Pipeline by adding an unconnected REST Get Snap. You configure the Snap to retrieve contact data from HubSpot, which typically offers data in pages of 20 records each. You use the Has next and Next URL fields to specify how the Snap can retrieve additional pages of data. For step-by-step information on how to use the REST Get Snap to perform this task, see Retrieving Contact Information from HubSpot.
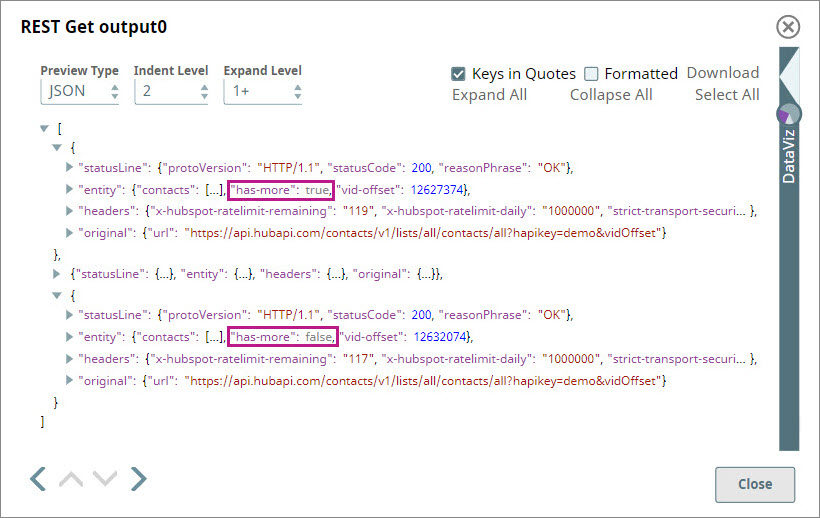
The REST Get Snap retrieves the data in pages of 20 as requested until the value of thehas-morevariable changes to false:Info Note that until the REST Snap completes executing, the Gate Snap doesn't start reading data from any of its input views.
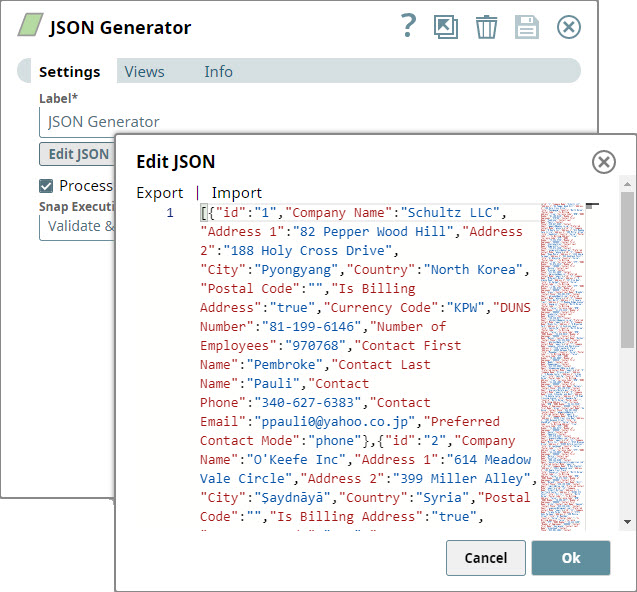
- You create another branch of the Pipeline by adding a JSON Generator Snap that provides customer information:
- You add a Gate Snap and configure it to have three input views:
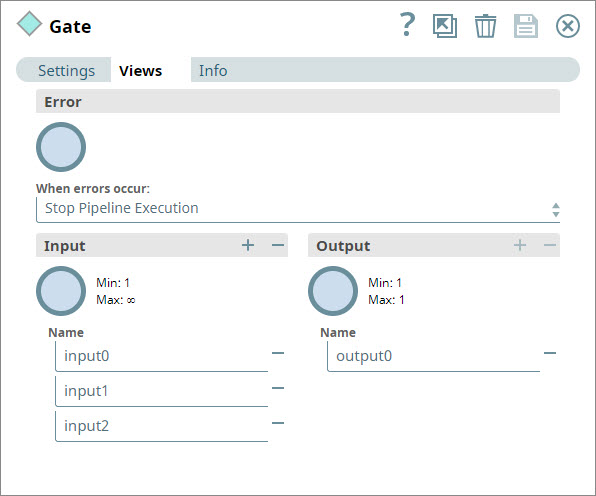
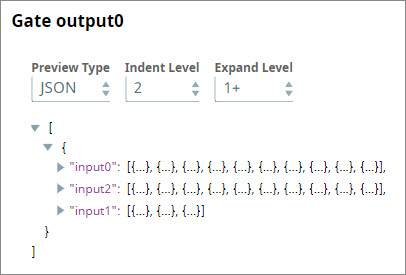
You make no further changes to the Gate Snap and connect its three inputs to each of the branches you created in the steps above. - You save and run the Pipeline. The Gate Snap now collects the completed inputs from all upstream branches and offers them all as separate arrays in a single output document:
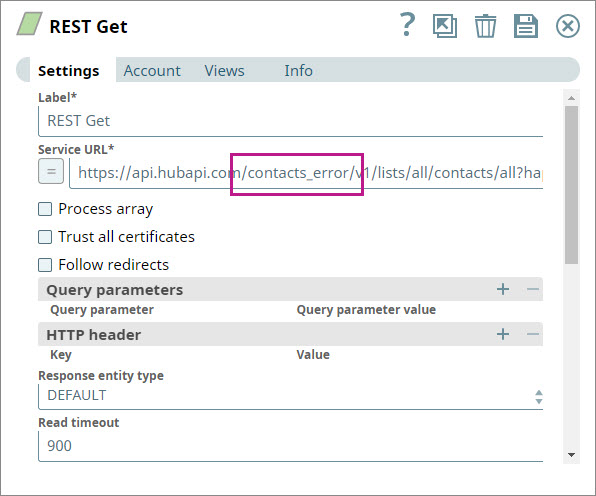
- To check how the Gate Snap behaves when one of the Snaps does not offer any output, you introduce an error into the REST Get Snap:
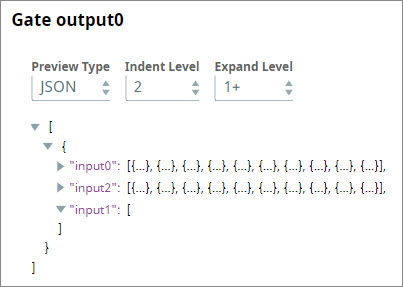
- You now save and re-execute the Pipeline. The Gate Snap now offers an output which contains all the data received from the File Reader and JSON Generator branches; but in the output associated with the REST Get Snap, it outputs a null record:
Collecting the Output Document Content
This example Pipeline demonstrates the following three methods in which to collect the output document content from the upstream Snaps using the Gate Snap.
- All input documents
Document count and first document for each input
Document count and final document for each input
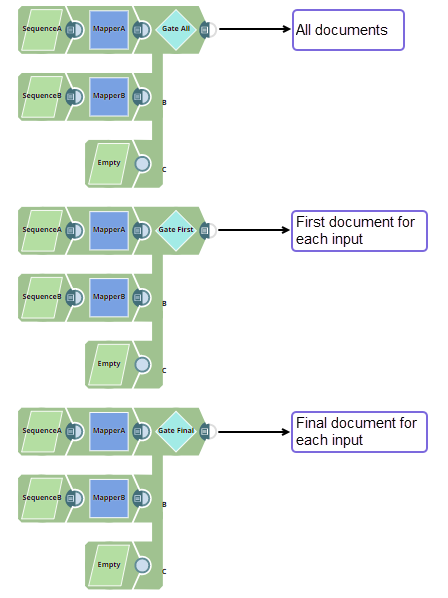
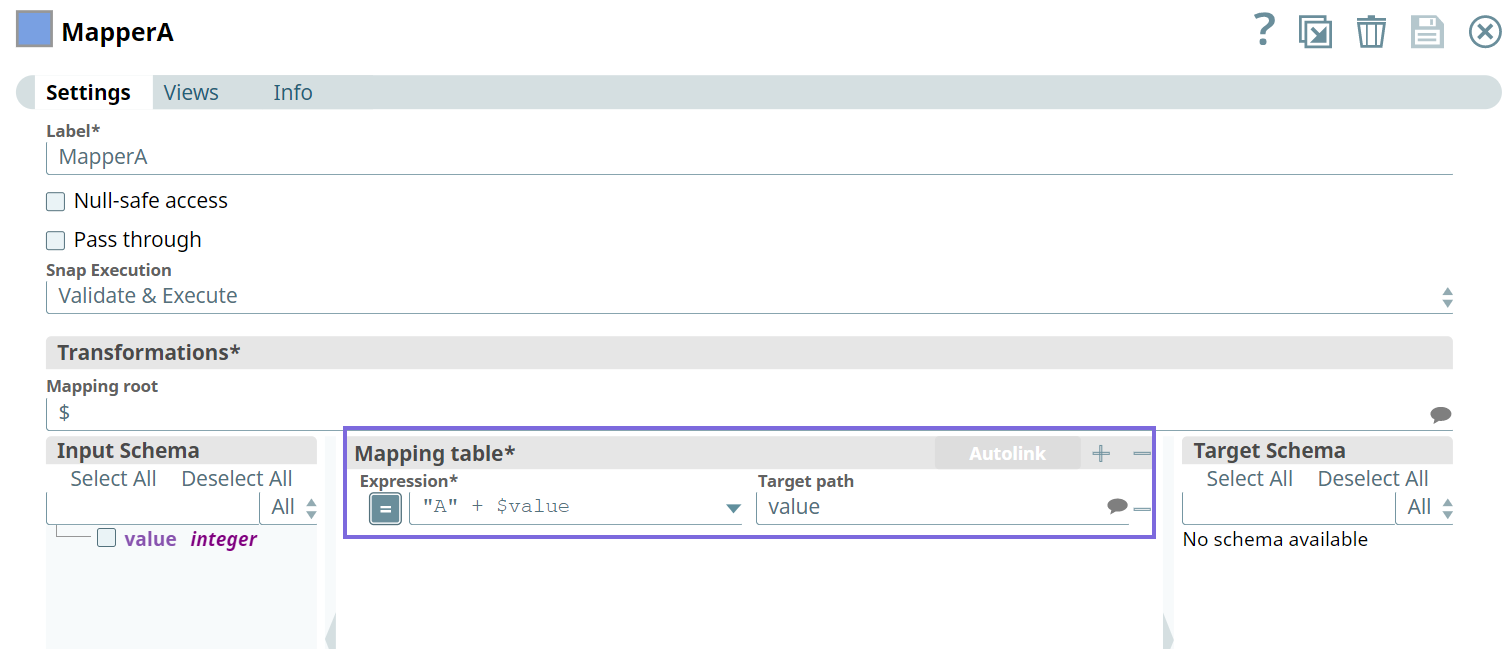
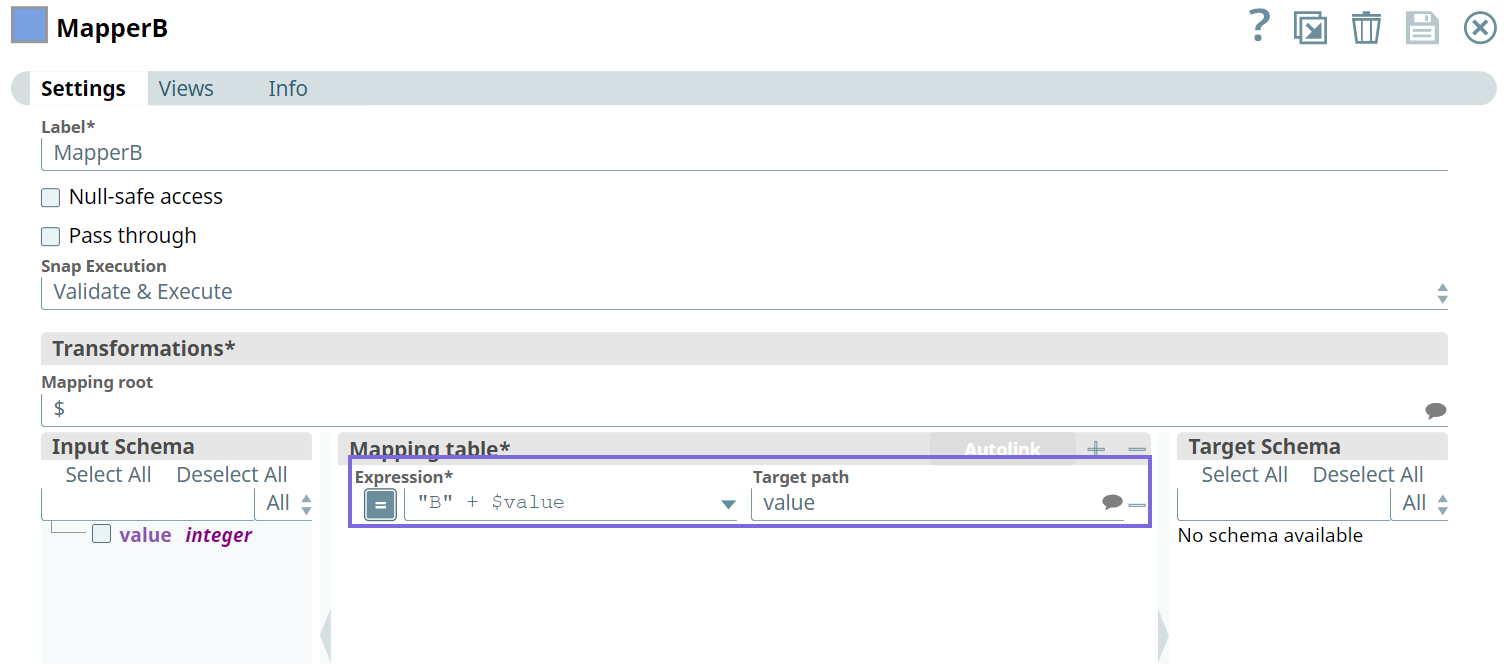
We build three Pipelines to pass data using two Mapper Snaps and empty data from the JSON Generator Snap.
...
...
...

...
...

...
...

Downloads
...
| Attachments | ||
|---|---|---|
|
...