...
SnapLogic Studio provides a modern easy-to-use interface. We are releasing functionality incrementally.
New Features
The Infrastructure System overview page provides monitoring capabilities to help you visualize and troubleshoot the behavior of Snaplex instances Snaplexes and their nodes. Org admins can also start and restart nodes and a Snaplex from this page.
...
Change the time period
Refresh the view manually
Search for a Snaplex or node and add Advanced search filtering on type, node status, Snaplex version, and operating system
Switch between map and list views

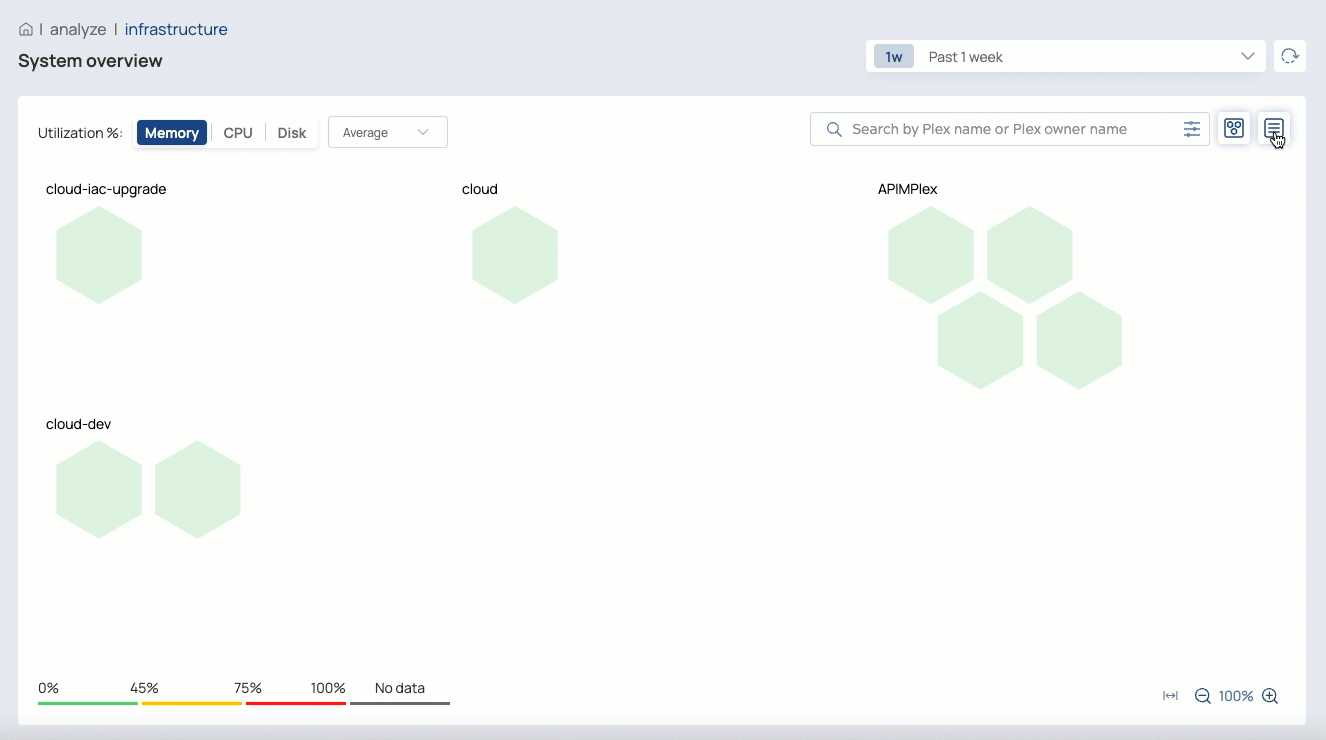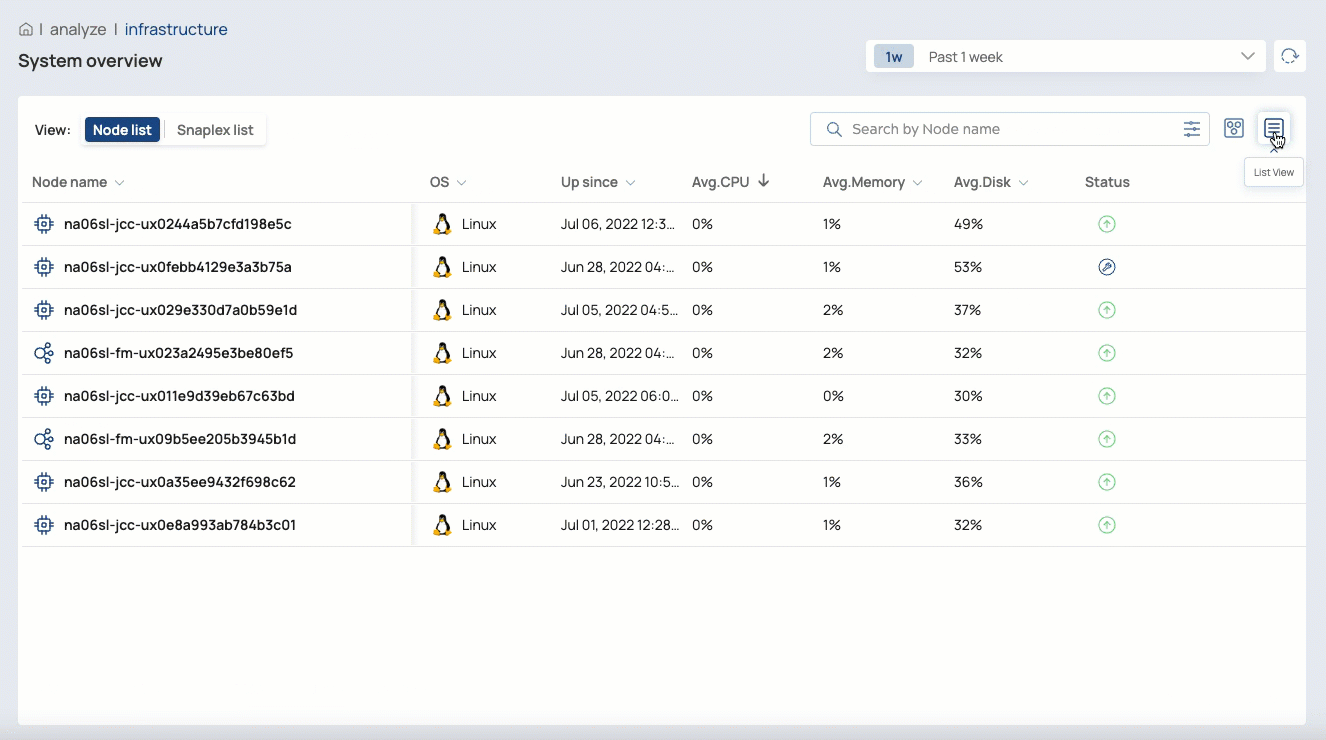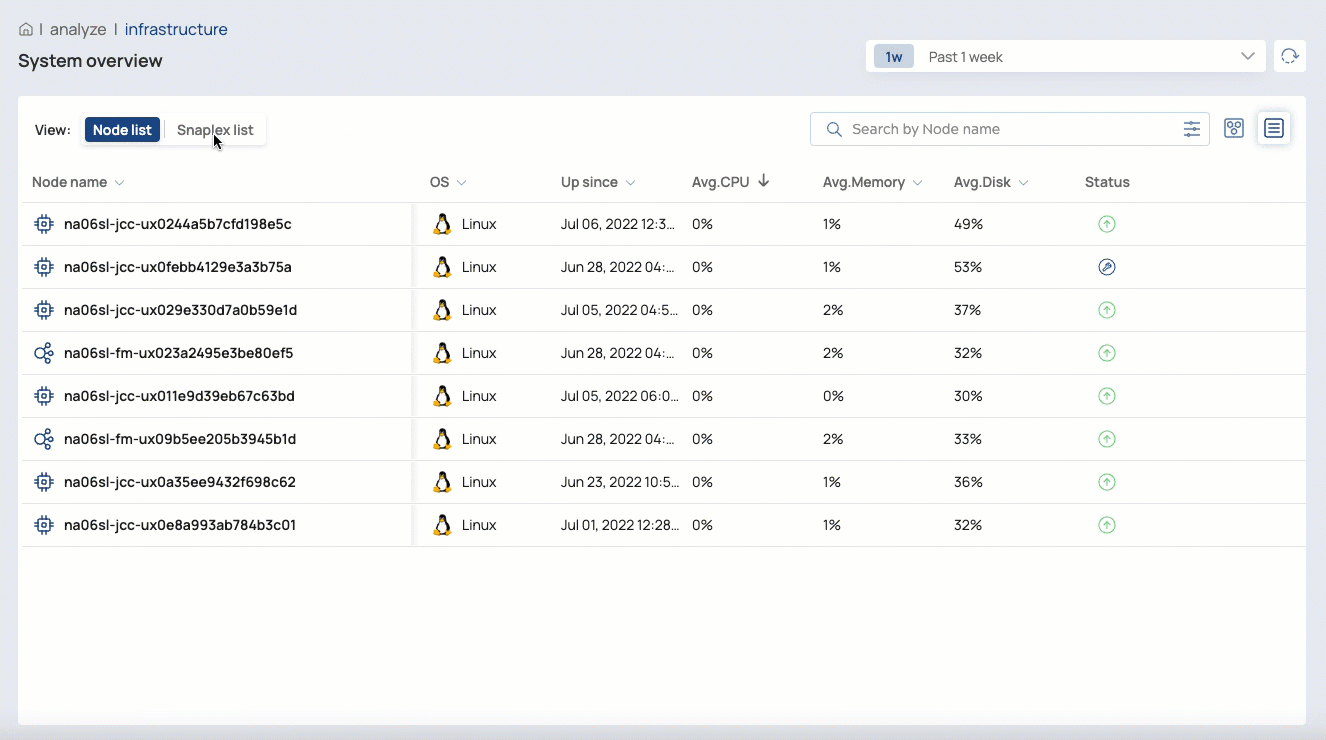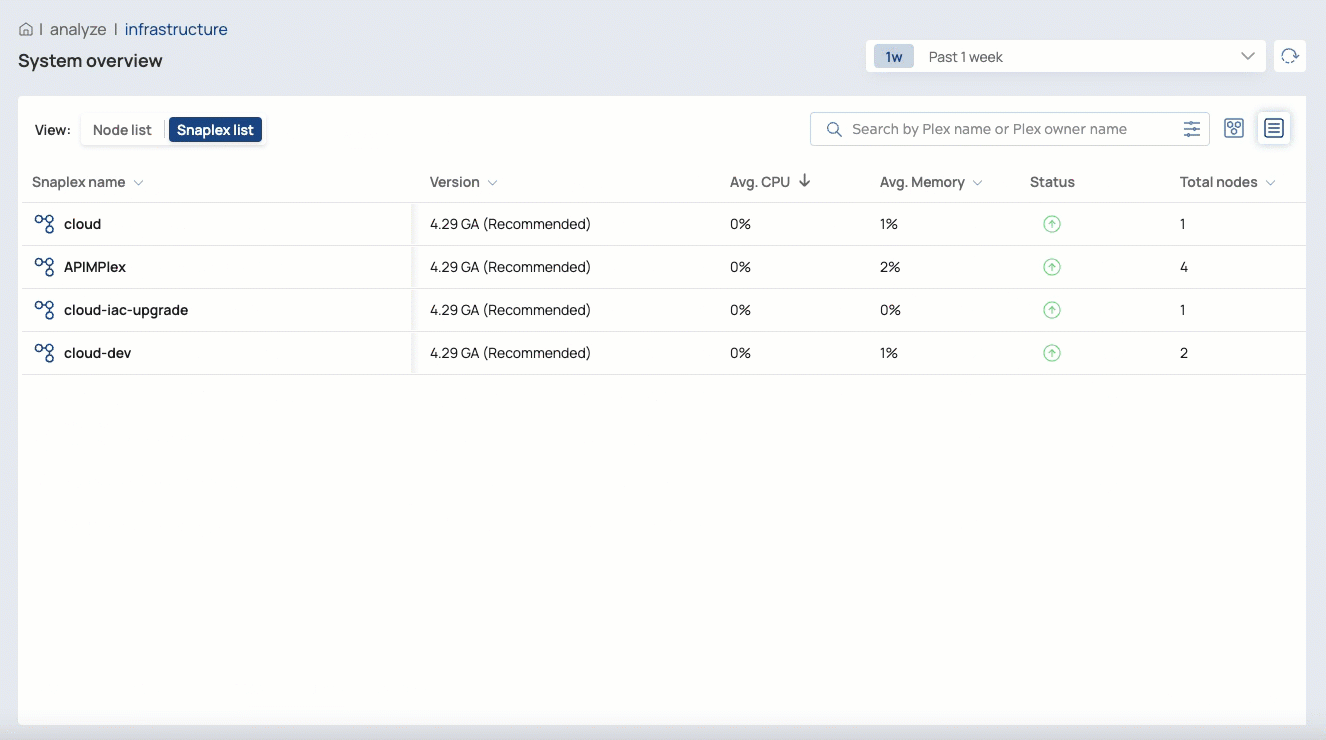
In the Node Map View, you can:
Switch between viewing memory, CPU, and disk usage
Switch between average and maximum usage
Select a node to view its details
For customer-managed nodes, Org admins can restart a node, put it in maintenance mode, or exit maintenance mode

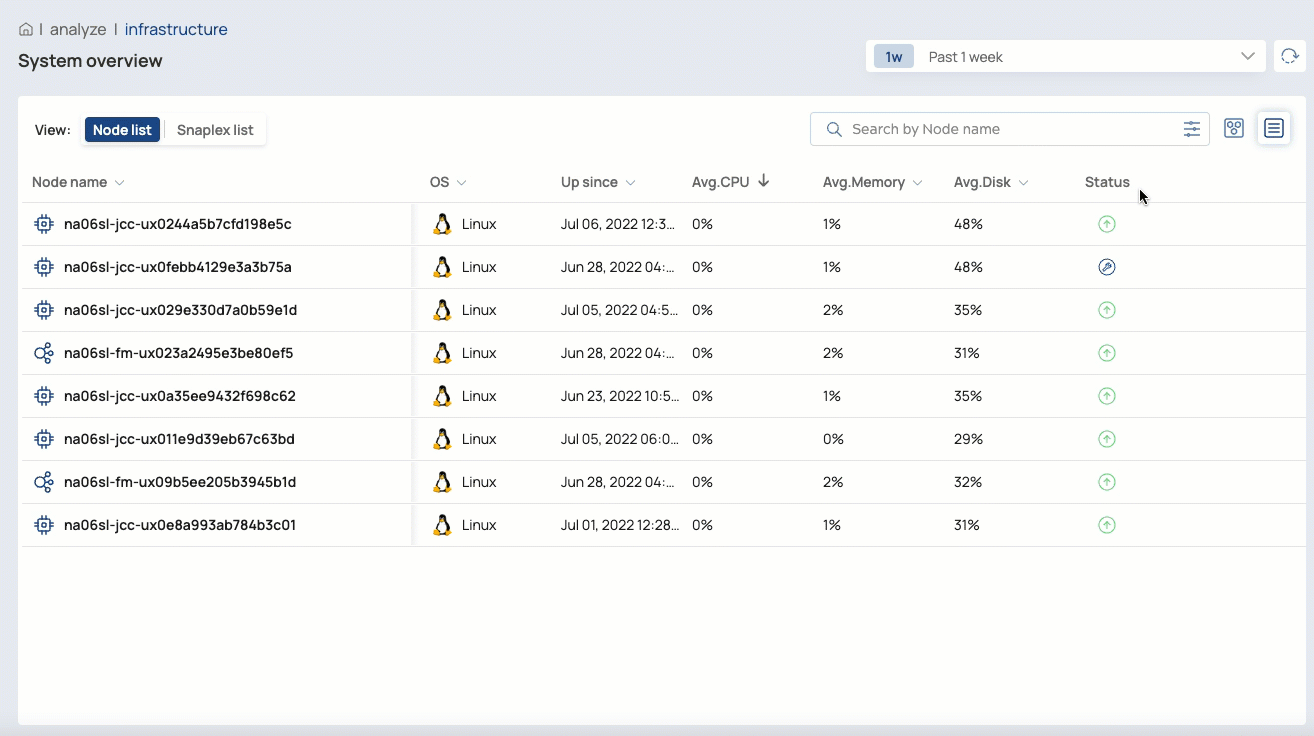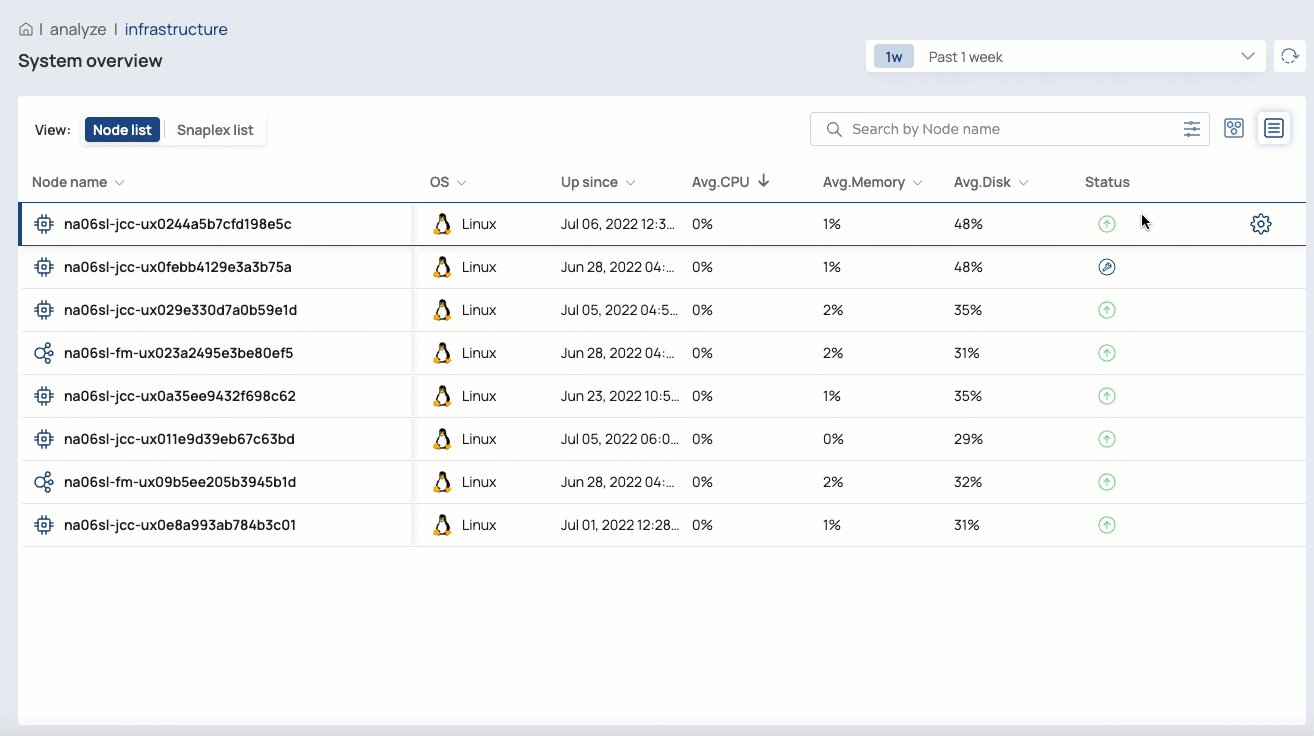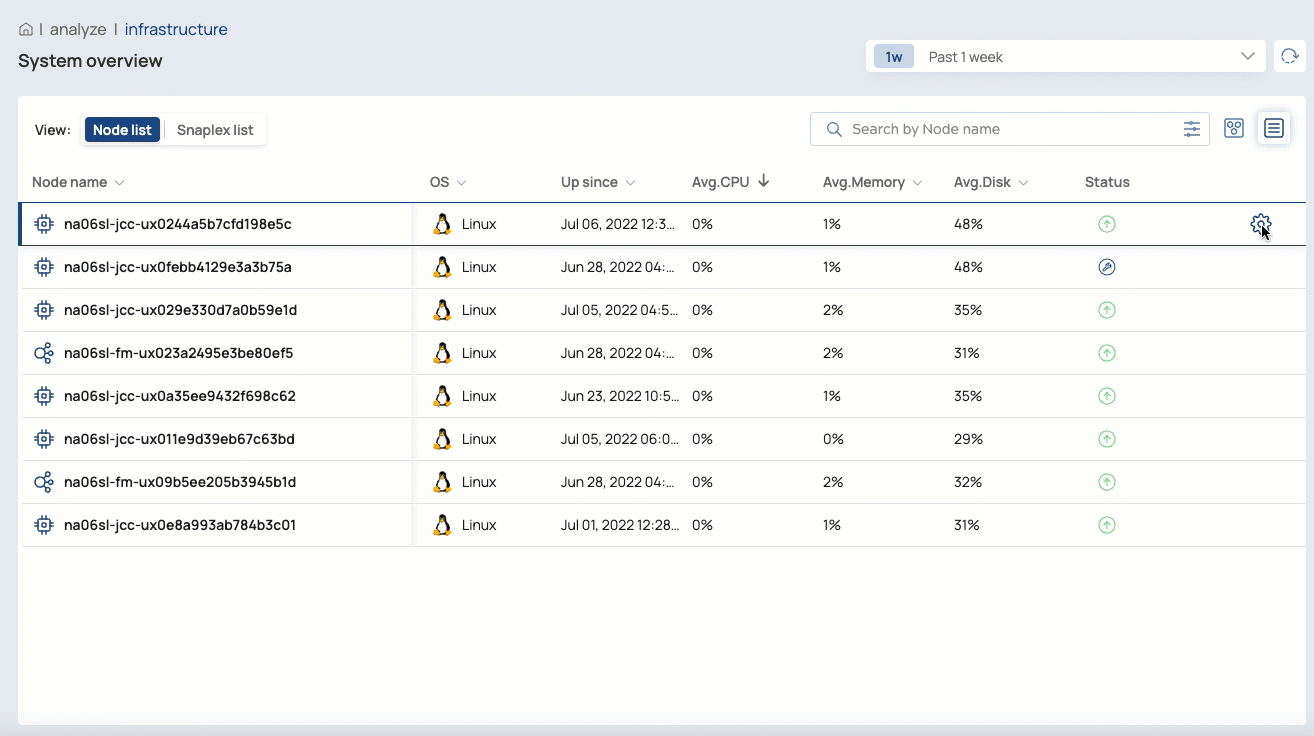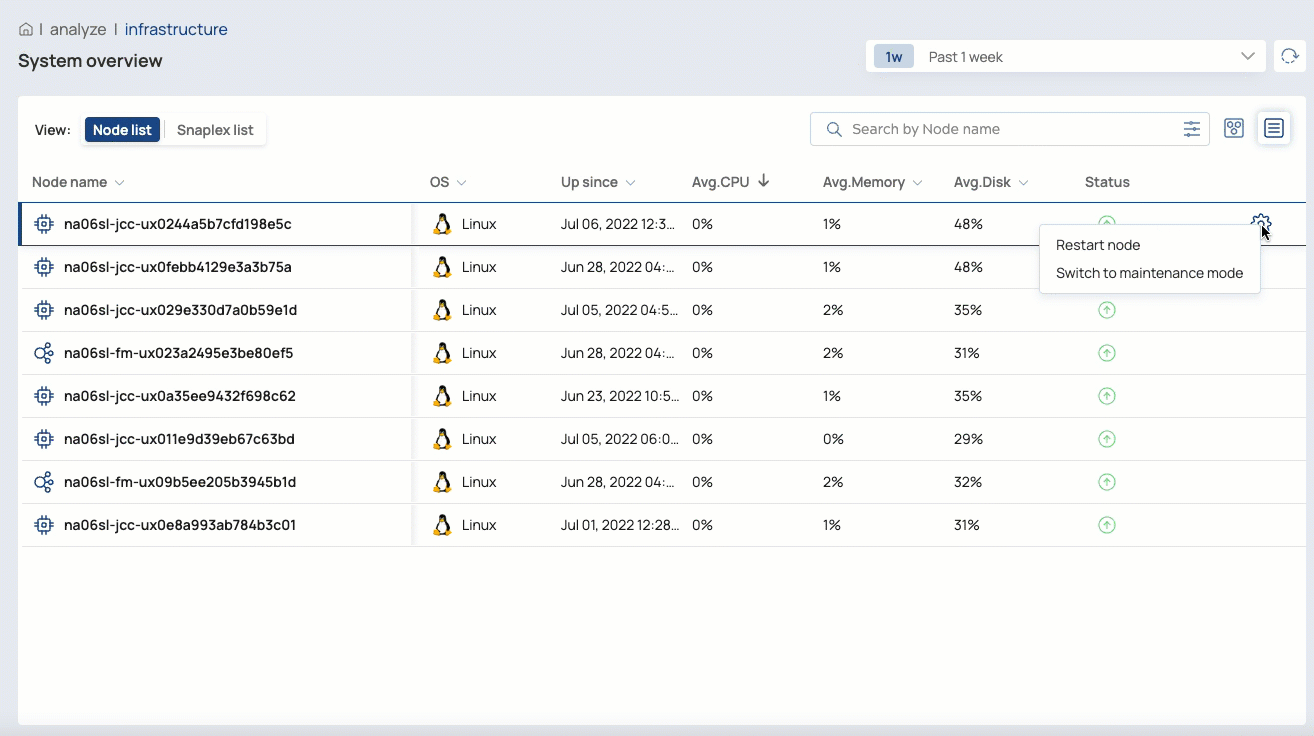
In the List View, you can:
...
New Public APIs allow you to do the following programmatically:
Copy a list of assets from several projects to a single destination project.
Migrate an API version with its assets to another API.
Retrieve API Management logs that were previously available only through the Dashboard UI.
...
Snap Pack | Date of Update | Snap Pack Version | Updates |
|---|---|---|---|
14 | <429PatchesXXXXX>42920rc17045 | A new Snap Pack for Databricks Lakehouse Platform (Databricks or DLP) introduces the following Snaps:
|
...
The ELT Load Snap can infer the schema from the source files located in S3 buckets and create, overwrite, and append the target table in your Redshift instance with the source data. It can infer the table schema from the data available in AVRO, CSV, JSON, ORC, and PARQUET files.
Enhancements
The ELT SCD2 Snap:
Upon Pipeline validation, displays the final SQL query to be executed on the target CDW, in its output preview.
Can replace an existing target table with a new table and load the SCD2 entries from the source table/files into it. Use the new Overwrite existing table option in the Target Table action field to perform this action
Learn more at Automatic Schema Inference with ELT Load Snap.
Known Issues
When loading data from a CSV file to a target DLP table, the header names in the file must exactly match the column names in the target table. Otherwise, the ELT Load Snap returns the error—
Column names should be the same in the target table and CSV fileand aborts the load operation.You cannot add a column to your BigQuery target table with a deleted column name using the ELT Load Snap, as BigQuery reserves deleted column names and data until the pre-configured time travel duration (from 2 through 7 days).
Due to an issue with the Simba Spark JDBC driver for DLP, you cannot insert a NULL value in the nullable columns of Boolean data type in your DLP instance using any of the write-type Snaps—ELT Load, ELT SCD2, ELT Insert Select, ELT Merge Into, and ELT Execute, when the target table schema is available.
The only workaround currently available for this issue is to upgrade your JDBC driver to databricks-jdbc-2.6.25-1.jar, and use the corresponding JDBC driver class (
com.databricks.client.jdbc.Driver) and JDBC URL in your Snap account.
...
The ELT Load Snap does not cause any NULL values in new columns added to the target table through the Alter table Load Action.
The ELT Merge Into Snap fails when you perform an UPDATE action in the (hash) distribution key column of an Azure Synapse table. The failure occurs because Azure Synapse does not support modifying values in a table (hash) distribution key column.
Due to an issue with DLP, aborting an ELT Pipeline validation (with preview data enabled) causes only those SQL statements that retrieve data using bind parameters to get aborted while all other static statements (that use values instead of bind parameters) persist.
For example,
select * from a_table where id = 10will not be aborted whileselect * from test where id = ?gets aborted.
To avoid this issue, ensure that you always configure your Snap settings to use bind parameters inside its SQL queries.
The ELT Math Function Snap fails during Pipeline execution even after successful validation against the Redshift CDW due to the incompatible or incorrect data types associated with the target table columns created during the Pipeline validation. To prevent this failure, we recommend that you manually delete the table created during validation before running the Pipeline.
When you add an input view to the Databricks - Delete Snap, ensure that you configure the Batch size as 1 in the Snap’s account configuration. For any other batch size, the Snap fails with the exception:
Multi-batch parameter values are not supported for this query type.
Flows
New Features
Introduced the following endpoints:
Redshift as a source to fetch data from a specific table of the Redshift database and also as a target to insert, update, or delete data into its database.
Snowflake as a source to fetch data from a specific table of the Snowflake database and also as a target to insert, update, or delete data into its database.
Google BigQuery as a target to load data into the BigQuery data platform.
MongoDB as a source to execute the find command on your MongoDB database and also as a target to execute the insert, update, or delete command on its database.
PostgreSQL as a source to fetch data from a specific table of the PostgreSQL database and also as a target to execute SQL statements to insert, update, or delete data within a specified table of the PostgreSQL database.
SQL Server as a source to fetch data from a specific table of a SQL Server database and also as a target to insert, update, or delete data within a specific table of the SQL Server database.
Enhancements
Added the source endpoint for MySQL, which you can now use to fetch data from a specific table of the MySQL database.