...
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
You can use this Snap to execute SQL queries in the target database – Snowflakedatabase—Snowflake, Redshift, or Azure Synapse, Databricks Lakehouse Platform, or BigQuery. You can run the following types of queries using this Snap:
Data Definition Language (DDL) queries
Data Manipulation Language (DML) queries
Data Control Language (DCL) queries
...
Prerequisites
Valid accounts and access permissions to connect to the following:
Source: AWS S3, Azure Cloud Storage, or Google Cloud Storage
Target: Snowflake, Redshift, Azure Synapse, or Databricks Lakehouse Platform, or BigQuery
| Note |
|---|
If you want to use the COPY INTO command for loading data into the target database, you must pass (expose) these account credentials inside the SQL statement. Hence, we recommend you to consider using the ELT Load Snap as an alternative. |
Limitations
This Snap does not support multi-statement transaction rollback of any of the DDL, DCL or DML statements specified.
Each statement is auto-committed upon successful execution. In the event of a failure, the Snap can rollback only updates corresponding to the failed statement execution. All previous statements (during that Pipeline execution runtime) that ran successfully are not rolled back.
You cannot run Data Query Language (DQL) queries using this Snap. For example,
SELECTandWITHquery constructs.Use this Snap either at the beginning or in the end of the Pipeline.
This Snap executes the SQL query only during Pipeline Execution. It does NOT perform any action (including showing a preview) during Pipeline validation.
ELT Snap Pack does not support Legacy SQL dialect of Google BigQuery. We recommend that you use only the BigQuery's Standard SQL dialect in this Snap.
Known Issues
ELT Pipelines created prior to 4.24 GA release using one or more of the ELT Insert Select, ELT Merge Into, ELT Load, and ELT Execute Snaps may fail to show expected preview data due to a common change made across the Snap Pack for the current release (4.26 GA). In such a scenario, replace the Snap in your Pipeline with the same Snap from the Asset Palette and configure the Snap's Settings again.
The Snap’s preview data (during validation) contains a value with precision higher than that of the actual floating point value (float data type) stored in the Delta. For example, 24.123404659344 instead of 24.1234. However, the Snap reflects the exact values during Pipeline executions.
In any of the supported target databases, this Snap does not appropriately identify nor render column references beginning with an _ (underscore) inside SQL queries that use the following constructs and contexts (the Snap works as expected in all other scenarios):
WHEREclauseWHENclauseONcondition (ELT Join, ELT Merge Into Snaps)HAVINGclauseQUALIFYclauseInsert expressions (column names and values in ELT Insert Select, ELT Load, and ELT Merge Into Snaps)
Update expressions list (column names and values in ELT Merge Into Snap)
Secondary
ANDconditionInside SQL query editor (ELT Select and ELT Execute Snaps)
As a workaround while using these SQL query constructs, you can:
Precede this Snap with an ELT Transform Snap to re-map the '_' column references to suitable column names (that do not begin with an _ ) and reference the new column names in the next Snap, as needed.
In case of Databricks Lakehouse Platform where CSV files do not have a header (column names), a simple query like
SELECT * FROM CSV.`/mnt/csv1.csv`returns default names such as _c0, _c1, _c2 for the columns which this Snap cannot interpret.To avoid this scenario, you can:
Write the data in the CSV file to a DLP table beforehand, as in:
CREATE TABLE csvdatatable (a1 int, b1 int,…) USING CSV `/mnt/csv1.csv`where a1, b1, and so on are the new column names.Then, read the data from this new table (with column names a1, b1, and so on) using a simple SELECT statement.
Snap Input and Output
View | Type of View | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input | Document |
|
| An upstream Snap is not mandatory. Use the input view to connect the Snap as the terminating Snap in the Pipeline. |
Output | Document |
|
| A downstream Snap is not mandatory. Use the output view to connect the Snap as the first Snap in the Pipeline. |
Snap Settings
Parameter | Data Type | Description | Default Value | Example |
|---|---|---|---|---|
Label | String | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. | N/A | ELT Execute for SF |
SQL Statements | Required. Use this field set to define your SQL statements, one in each row. Click | |||
SQL Statement Editor | String/Expression | Required. Enter the SQL statement to run, in this field. The SQL statement must follow the SQL syntax as stipulated by the target database—Snowflake, Redshift, Azure Synapse, or Databricks Lakehouse Platform. | N/A | drop table base_01_oldcodes; |
Troubleshooting
Error | Reason | Resolution |
|---|---|---|
Failure: DQL statements are not allowed. | The ELT Execute Snap does not support Data Query Language (DQL) and hence statements containing | Remove any DQL statements (containing
|
Examples
Sample Queries for the ELT Execute Snap
| Code Block | ||
|---|---|---|
| ||
CREATE OR REPLACE WAREHOUSE me_wh WITH warehouse_size='X-LARGE'; CREATE OR REPLACE TABLE "TEST_DATA".NEW_DATA(VARCHAR_DATA VARCHAR(10)); CREATE OR REPLACE TABLE "TEST_DATA".DT_EXECUTE_01(VARCHAR_DATA VARCHAR(100),TIME_DATA TIME,FLOAT_DATA FLOAT,BOOLEAN_DATA BOOLEAN,NUMBER_DATA NUMBER(38,0),DATE_DATA DATE); TRUNCATE TABLE IF EXISTS "public".simple_data_02; INSERT OVERWRITE INTO "BIGDATAQA"."TEST_DATA"."OUT_ELT_EXECUTE_SF_003" SELECT * FROM ( SELECT * FROM "BIGDATAQA"."TEST_DATA"."DT_EXECUTE_03" ) |
Updating a Target Table Based on Updates to Another Table
The following Pipeline updates a target (backup) table - OUT_ELT_EXECUTE_SF_003 periodically based on the updates to another table DT_EXECUTE_03 (source). These tables are present in a Snowflake database, and we use data views from this database to present the updates that the Pipeline does in the target table.
...
Target Table: OUT_ELT_EXECUTE_SF_003 |
|---|
 |
Example 2: Using one ELT Execute Snap to Create and Fill a Table
In this example Pipeline, we create a new table in the Redshift database and fill data into this table using an ELT Execute Snap. We later read the data from this table using an ELT Select Snap.
...
ELT Select Snap |
|---|
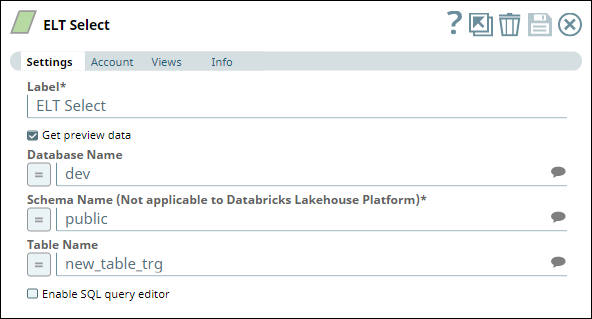 |
Snap Output |
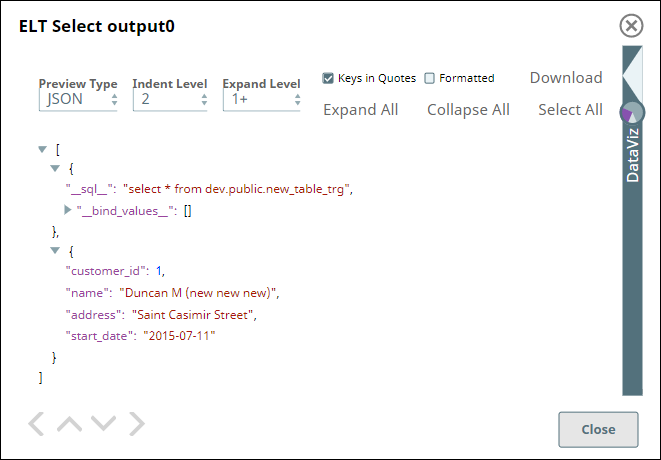 |
Downloads
|
| Attachments | ||||
|---|---|---|---|---|
|
Snap Pack History
| Expand | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
...