On this Page
| Snap Type: | Write | ||||||
|---|---|---|---|---|---|---|---|
| Description: | This Snap performs a bulk load operation into a Google BigQuery database. Depending upon the Snap's configuration, it does so either by using data from incoming documents or by using existing files in the Google Cloud Storage bucket. The Snap supports all three file types supported by Google BigQuery - CSV, JSON, and AVRO. When using incoming documents: In the case where data from incoming documents is being loaded, the data is first uploaded to a temporary file on Google Cloud Storage and from that temporary file the data is loaded into the destination table. The user can choose to either retain or delete this temporary file after the Snap terminates. When using existing files from Google Cloud Storage: In the case where existing files from Google Cloud Storage are being used, the data is loaded directly from the specified files into the destination table, there are no temporary files created for this operation. However, the user can choose to either retain or delete these existing files after the Snap terminates. ETL Transformations & Data FlowThe Google BigQuery Bulk Load (Cloud Storage) Snap performs a bulk load of the input records into the specified database. If the data is being loaded from incoming documents, it is sent to a temporary file in the cloud storage and from there to the destination table. The temporary file is retained after Snap's execution. However, the user can choose to delete it if they so wish and configure the Snap accordingly. Input & Output
Modes
Consider the following points when using this Snap:
Snaps in Google BigQuery Snap Pack
So, ensure that you include the time zone in all the datetime values that you load into Google BigQuery tables using this Snap. For example: "2020-08-29T18:38:07.370 America/Los_Angeles", “2020-09-11T10:05:14.000-07:00", “2020-09-11T17:05:14.000Z” | ||||||
| Prerequisites: | Write access to the Google BigQuery Account and Read & Write access from/to the Google Cloud Storage account is required. | ||||||
| Limitations and Known Issues |
When uploading from existing documents on Google Cloud Storage, enabling the Create table if not the present check box throws an exception error. To avoid this, ensure the destination table exists. Known Issue Copying data by creating a table with the same name in Google BigQuery immediately after deleting it, might not insert the rows as expected. This behavior is due to the way the tables are cached and the internal table ID is propagated throughout the system. Workaround We recommend you avoid rewriting in Google BigQuery and suggest the following workarounds. You can choose to use them individually or in unison, to suit your requirement.
| ||||||
| Configurations: | Account & AccessThis Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Google BigQuery Account for information on setting up this type of account. Views
| ||||||
| Troubleshooting: | Mismatch in the order of columns/number of columns between incoming document/existing Google Cloud Storage files in CSV format:
| ||||||
Settings | |||||||
Label* | Specify a name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | ||||||
| Project ID* | Specify the Project ID of the project containing the table. This is a suggestible field and can be populated based on the Account settings. Default value: None | ||||||
| Dataset ID | Specify the dataset ID of the dataset containing the table. This is a suggestible field and all the datasets in the specified project will be populated. Default value: None | ||||||
| Table ID* | Specify the name of the target table into which the records are to be loaded. This is a suggestible field and all the tables in the datasets will be listed. Default value: None | ||||||
| Create table if not present | Select this checkbox to automatically create the target table if it does not exist.
Due to implementation details, a newly created table is not visible to subsequent database Snaps during runtime validation. If you want to immediately use the newly updated data you must use a child Pipeline that is invoked through a Pipeline Execute Snap. Default value: Not selected When using "Use existing files Upload type" option Ensure that you do not select Create table if not present check box if you choose the Upload existing files on Google Cloud Storage option for Upload type, else an exception is thrown and the Snap does not execute. | ||||||
| Bucket name | Specify the name of the Google Cloud Storage bucket to be used for the operation. This is a suggestible field and will list all the buckets within the given account. Default value: None | ||||||
| Upload type | Choose an upload type for uploading your documents. The available options are:
These options specify the data source to the Snap. Incoming files or existing files in Google Cloud Storage bucket have to be uploaded. Default value: Upload existing files from Google Cloud Storage Based on the option you choose, only one of the succeeding sections has to be configured. The succeeding sections being Properties for uploading incoming documents and Properties for uploading existing files from Google Cloud Storage. | ||||||
| Properties for uploading incoming documents | |||||||
| This sub-section has to be configured if the option Upload incoming documents was selected in the Upload type property. | |||||||
| File format | Choose the file preferred format of the temporary file. The available options are: CSV, JSON, and AVRO. Default value: CSV File formats and their limitations The file format should be selected based on the data type they support, for example if the incoming document contains arrays or lists then selecting CSV in the File format property will throw an execption and the Snap will not execute. To avoid this, AVRO or JSON must be selected. Similarly, AVRO file format should not be used for Date Time data types. If the incoming documents do not contain all the table columns in the same order as the destination table then do not use CSV. | ||||||
| Temp file name | The name of the temporary file that is created on the Google Cloud Storage bucket. If a filename is not provided, then a system generated file name is used. Default value: [None] | ||||||
| Preserve temp file | Specify whether the temporary file created for the load operation has to be retained or deleted after the Snap's execution. By default the temporary file is deleted. Default value: Selected | ||||||
| Batching | Select if you want the Snap to process the input records in batches. | ||||||
| Batch Size | The number of records batched per request. If the input has 10,000 records and the batch size is set to 100, the total number of requests would be 100. | ||||||
| Batch Timeout (milliseconds) | Time in milliseconds to elapse following which the batch if not empty will be processed even though it might be lesser than the given batch size. | ||||||
| Properties for uploading existing files from Google Cloud Storage | |||||||
| This sub-section has to be configured if the option "Upload existing files from Google Cloud Storage" was selected in the Upload type property. | |||||||
| File paths | Multiple files can be selected based on the need. When the pipeline is executed, the output data will have as many records listed. Based on the number of files added, the Snap will group them into categories (CSV with header & delimiter, CSV with delimiter but without header, JSON, and AVRO). This distinction is maintained in the output preview as well (shown distinctly according to File type). | ||||||
| File format | This is a drop-down list that has three options: CSV, JSON, and AVRO. Default value: CSV | ||||||
| File path | The file's location in the Google Cloud Storage bucket. Example: gs://gcs_existingbucket/exisitng_file.csv. Default value: [None] | ||||||
| CSV file contains headers | Specifies that the CSV file contains headers. Use this option to enable the Snap to differentiate between the headers and records. Default value: Not selected | ||||||
| CSV delimiter | Specify the delimiter for the CSV file. This is needed only for CSV file types. Default value: , (comma) Custom delimiters All custom delimiters supported by BigQuery are supported as well. | ||||||
| Delete files upon exit | Similar operation as Preserve temp file. If this option is enabled, the files from which the data is loaded to the destination table are deleted after Snap's execution. Default value: Not selected | ||||||
Snap execution | Select one of the three modes in which the Snap executes. Available options are:
| ||||||
Writing numeric values into Google BigQuery tables
Google BigQuery tables support columns with NUMERIC data type to allow storing big decimal numbers (up to 38 digits with nine decimal places). But Snaps in Google BigQuery Snap Pack that load data into tables cannot create numeric columns. When the Create table if not present check box is selected, the Snaps create the required table schema, but map big decimals to a FLOAT64 column. So, to store the data into numeric columns using these Snaps, we recommend the following actions:
- Create the required schema, beforehand, with numeric columns in Google BigQuery.
- Pass the number as a string.
The Google API converts this string into a number with full precision and saves it in the numeric column.
Example:
| Value Passed Through Snap | Value Stored in BigQuery | Remarks |
|---|---|---|
"12345678901234567890123456789.123456789" | 12345678901234567890123456789.123456789 | As per this issue logged in Google Issue Tracker, if you send the values as strings, the values are never converted to floating-point form, so this works as expected. |
12345678901234567890123456789.123456789 | 123456789012345678000000000000 | Big decimal values sent as non-string values lose precision. |
Examples
Basic Use Case - 1 (Upload incoming documents)
In this example, incoming documents are used for the bulk load. It will cover two scenarios:
- Temporary file is preserved.
- Temporary file is deleted.
The following pipeline is executed:
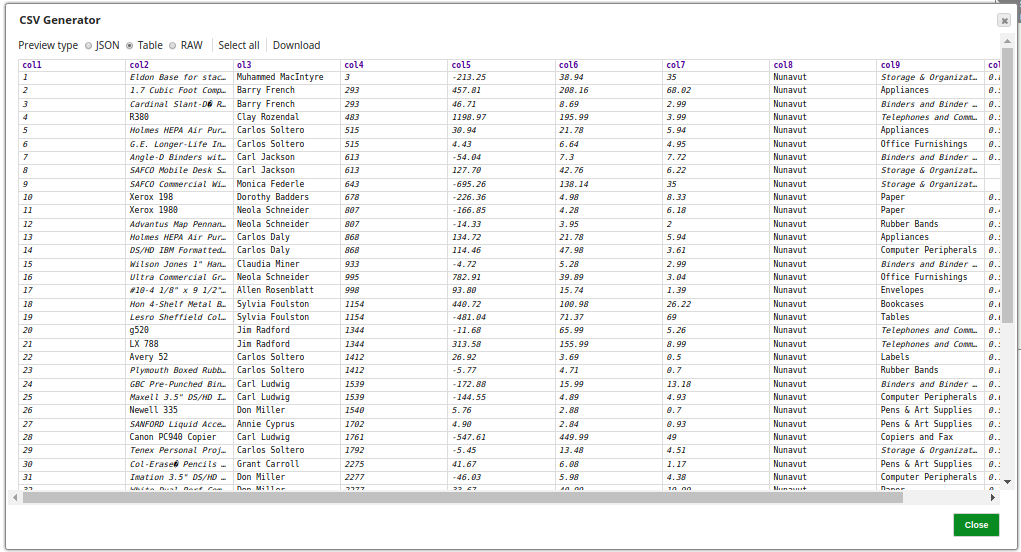
The CSV Generator Snap provides the input data to the Snap. A preview of the sample data from the incoming document is shown below:
Scenario - 1 - Temporary File Preserved
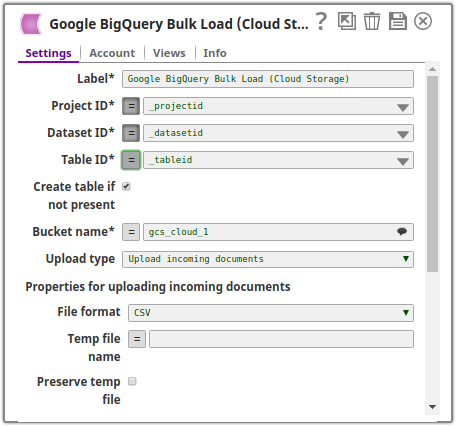
The following image is the configuration of the Google BigQuery Bulk Load (Cloud Storage) Snap:
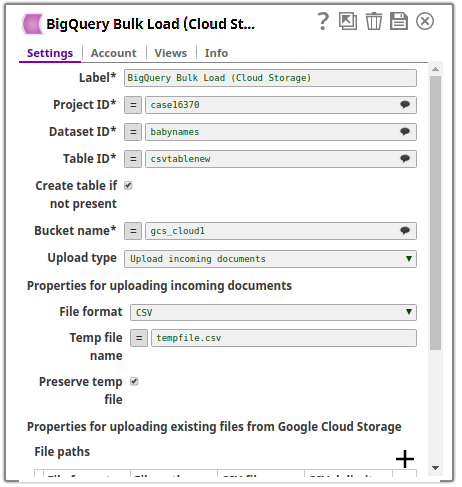
The Preserve temp file checkbox is selected and the temprary file is specified as tempfile.csv. Upon execution, the records from the incoming CSV file are loaded into the temporary file present in the gcs_cloud_1 bucket. From there it is loaded into the destination table csvtablenew in the babynames dataset within the case16370 project.
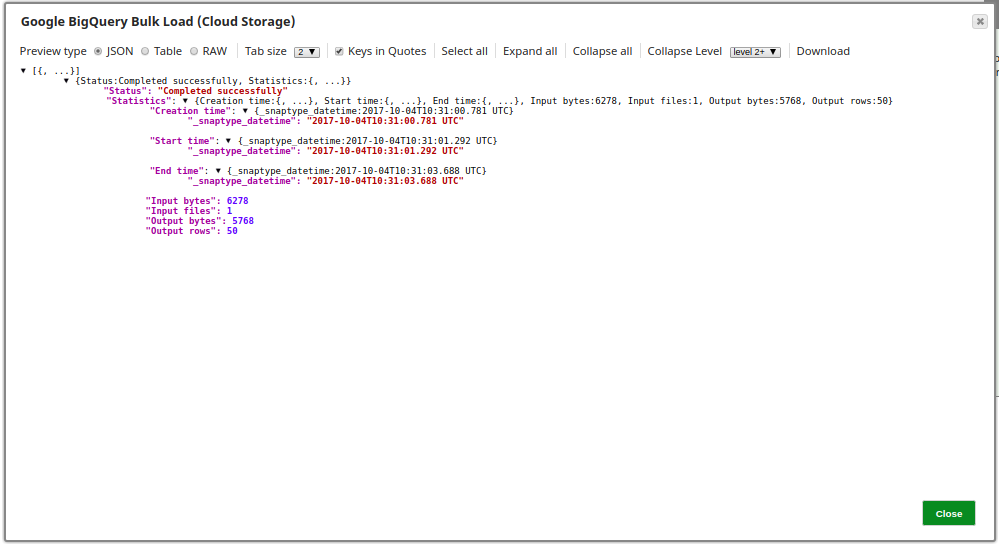
The following is a preview of the data output from the Google BigQuery Bulk Load (Cloud Storage) Snap:
Scenario - 2 - Temporary File Deleted
The following image is the configuration of the Google BigQuery Bulk Load (Cloud Storage) Snap:
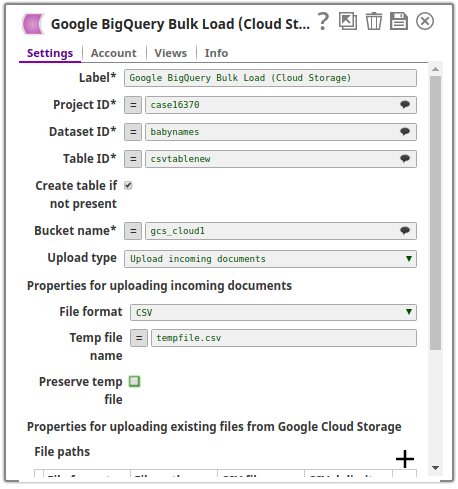
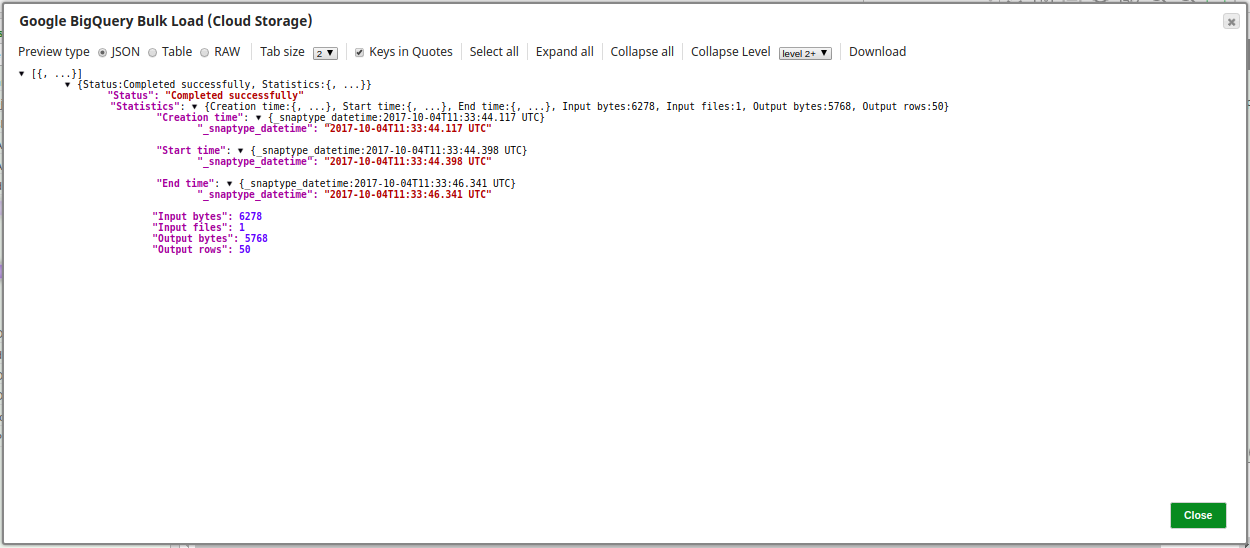
The Preserve temp file checkbox is not selected and the temprary file is specified as tempfile.csv. Upon execution, the records from the incoming CSV file are loaded into the temporary file present in the gcs_cloud_1 bucket. From there it is loaded into the destination table csvtablenew in the babynames dataset within the case16370 project. The temporary file is deleted.
The following is a preview of the data output from the Google BigQuery Bulk Load (Cloud Storage) Snap:
Basic Use Case - 2 (Upload Existing Files)
In this example, incoming documents are used for the bulk load. It will cover two scenarios:
- Cloud Storage file is preserved.
- Cloud Storage file is deleted.
The following pipeline is executed:
Scenario - 1 - Cloud Storage File Preserved
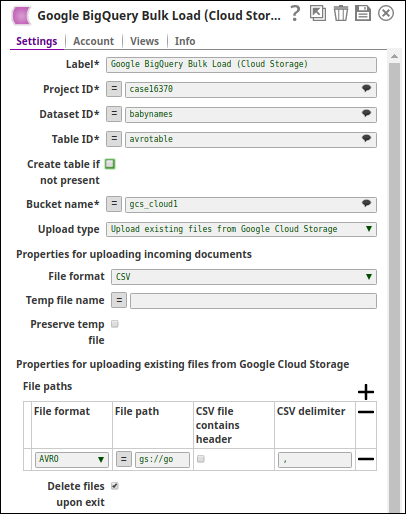
The following image is the configuration of the Google BigQuery Bulk Load (Cloud Storage) Snap:
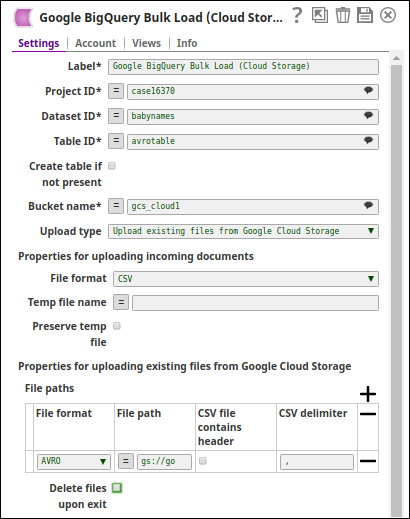
An AVRO file is chosen as the input file and the Delete files upon exit checkbox is not selected. Upon the Snap's execution, the data from the input file is loaded into the table named avrotable in the babynames dataset within the case16370 project. The AVRO file is not deleted.
The following is a preview of the Snap's output:
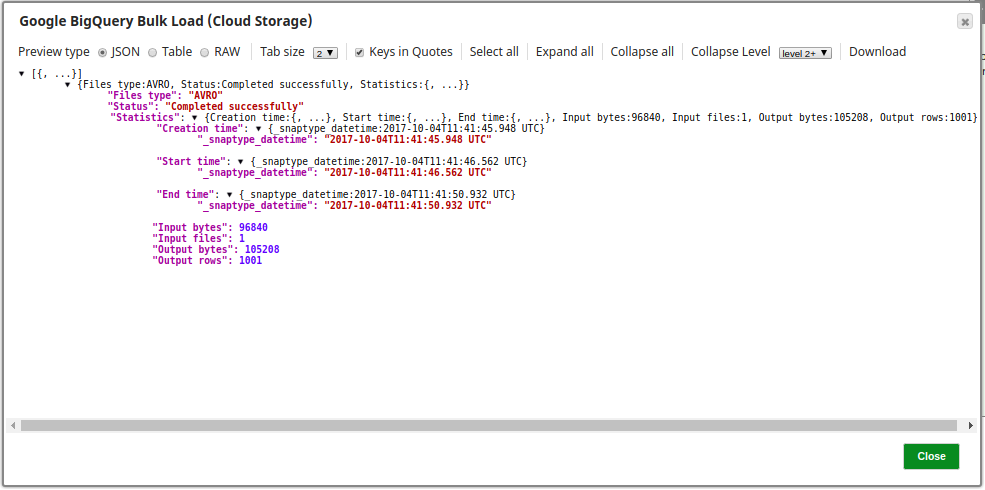
Scenario - 2 - Cloud Storage File Deleted
The following image is the configuration of the Google BigQuery Bulk Load (Cloud Storage) Snap:
The following is a preview of the Snap's output:
.png?version=1&modificationDate=1510459236359&cacheVersion=1&api=v2)
The exported pipeline is available in Downloads section below.
Typical Snap Configurations
The key configuration of the Snap lies in how the values are passed to the Snap. This can be done in the following ways:
- Without expressions
The values are passed to the Snap directly.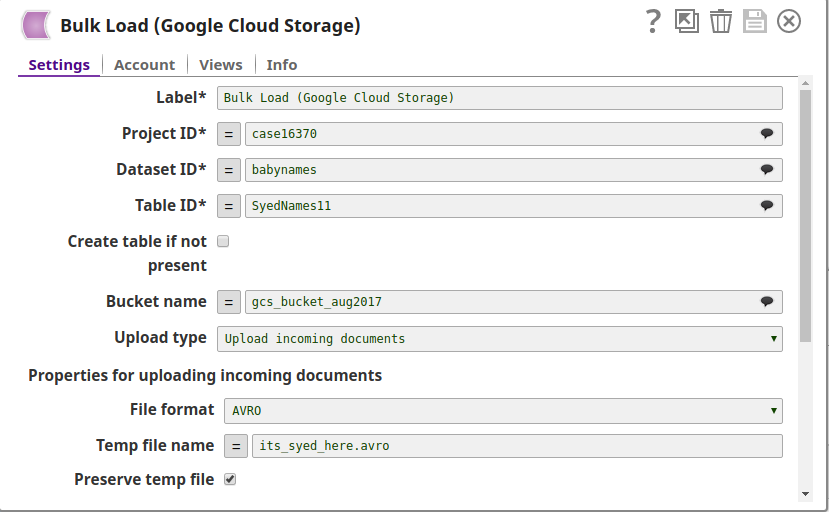
- With expressions
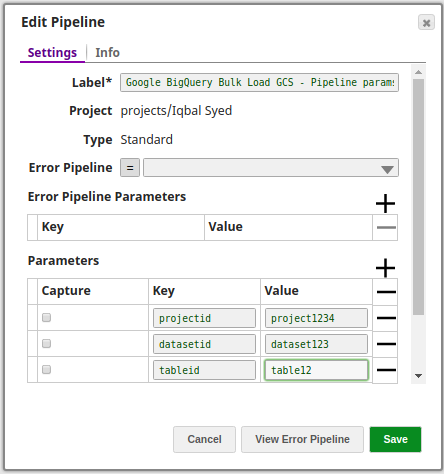
- Using pipeline parameters
The values are passed as pipeline parameters. The parameters to be applied have to be selected by enabling the corresponding checkbox under the Capture column.
- Using pipeline parameters
Advanced Use Case
The following describes a pipeline with a broader business logic involving multiple ETL transformations. It shows how in an enterprise environment, Bulk Load functionality can typically be used.
This pipeline reads social data and writes it into an existing file in the Google Cloud Storage. Bulk load of this social data is then performed from the existing file in the Google Cloud Storage to the destination table.

- Extract: Social data matching a certain criteria is extracted by the Query Snap.
- Transform: The extracted data from the Query Snap is transformed by the CSV Formatter Snap.
- Load: The incoming data from the CSV Formatter Snap is written into a CSV file in Cloud Storage by the File Writer Snap.
- Extract & Load: The Google BigQuery Bulk Load (Cloud Storage) Snap extracts the data from the existing CSV file in Cloud Storage and performs bulk load of this extracted data into the destination table.
- Extract: The Google BigQuery Execute Snap extracts the data inserted into the destination table by the Google BigQuery Bulk Load (Cloud Storage) Snap.
The exported pipeline is available in the Downloads section below.
Downloads