In this article
Overview
You can use the Azure SQL - Execute Snap to execute single simple DML (SELECT, INSERT, UPDATE, DELETE) type statements.
This Snap work only with single queries.
For the comprehensive scripting functionality offered by the various databases, we recommend you to use the stored procedure functionality offered by their chosen database in the Stored Procedure Snap.

Snap Type
The Azure SQL Execute Snap is a WRITE-type Snap that writes the results of the executed SQL queries.
Prerequisites
Valid Azure Synapse SQL Account.
Access to Azure Synapse SQL and the required permissions to execute T-SQL queries.
Support for Ultra Pipelines
Works in Ultra Pipelines.
Supported Versions
This Snap supports SQL Server 2008 or higher version.
Limitations
When the SQL statement property is an expression, the pipeline parameters are shown in the suggestions list, but not the input schema.
Known Issues
None.
Behavior Change
- In 4.26, when the stored procedures were called using the Database Execute Snaps, the queries were treated as write queries instead of read queries. So the output displayed message and status keys after executing the stored procedure.
In 4.27, all the Database Execute Snaps run stored procedures correctly, that is, the queries are treated as read queries. The output now displays message key, and OUT params of the procedure (if any). The status key is not displayed.
- If the stored procedure has no OUT parameters then only the message key is displayed with value success.
If you have any existing Pipelines that are mapped with status key or previous description then those Pipelines will fail. So, you might need to revisit your Pipeline design.
Snap Views
Type | Format | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input | Document |
|
|
|
Output | Document
|
|
|
|
Error | Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter when running the Pipeline by choosing one of the following options from the When errors occur list under the Views tab:
Learn more about Error handling in Pipelines. | |||
Snap Settings
Asterisk ( * ): Indicates a mandatory field.
Suggestion icon (
 ): Indicates a list that is dynamically populated based on the configuration.
): Indicates a list that is dynamically populated based on the configuration.Expression icon (
): Indicates the value is an expression (if enabled) or a static value (if disabled). Learn more about Using Expressions in SnapLogic.Add icon (
): Indicates that you can add fields in the field set.Remove icon (
): Indicates that you can remove fields from the field set.
Field | Field Type | Description |
|---|---|---|
Label Default Value: Azure SQL - Execute | String | Specify a unique name for the Snap. |
SQL statement* Default Value: N/A | String/Expression | Specifiy the SQL statement to execute on the server. There are two possible scenarios that you encounter when working with SQL statements in SnapLogic. Learn more about scenarios to execute your SQL statements.
|
Pass through Default Value: Selected | Checkbox | Select this checkbox to pass the input document to the output view under the key ' |
Ignore empty result
| Checkbox | Select this checkbox if you want the Snap to ignore empty fields and not write any document to the output view when a SELECT operation does not produce any result. If this property is not selected and the Pass through property is selected, the input document will be passed through to the output view. |
Number of Retries Default Value: 0 | Integer/Expression | Specify the maximum number of retry attempts the Snap must make in case there is a network failure, and the Snap is unable to read the target file. The request is terminated if the attempts do not result in a response. If the value is larger than 0, the Snap first downloads the target file into a temporary local file. If any error occurs during the download, the Snap waits for the time specified in the Retry interval and attempts to download the file again from the beginning. When the download is successful, the Snap streams the data from the temporary file to the downstream Pipeline. All temporary local files are deleted when they are no longer needed. |
Retry Interval (Seconds) Default Value: 1 | Integer/Expression | Specify the time interval between two successive retry requests. A retry happens only when the previous attempt resulted in an exception. |
Auto commit Default Value: Use account setting | Dropdown list | Select one of the options for this property to override the state of the Auto commit property on the account. The Auto commit at the Snap-level has three values: True, False, and Use account setting. The expected functionality for these modes are:
'Auto commit' may be enabled for certain use cases if PostgreSQL JDBC driver is used in either Redshift, PostgreSQL or Generic JDBC Snap. But the JDBC driver may cause out of memory issues when Select statements are executed. In those cases, “Auto commit" in Snap property should be set to ‘False’ and the Fetch size in the “Account setting" can be increased for optimal performance. Behavior of DML Queries in Database Execute Snap when auto-commit is false DDL queries used in the Database Execute Snap will be committed by the Database itself, regardless of the Auto-commit setting. When Auto commit is set to false for the DML queries, the commit is called at the end of the Snap's execution. The Auto commit needs to be true in a scenario where the downstream Snap does depend on the data processed on an Upstream Database Execute Snap containing a DML query. When the Auto commit is set to the Use account setting on the Snap, the account level commit needs to be enabled. |
Snap Execution | Dropdown list | Select one of the three modes in which the Snap executes. Available options are:
|
Additional Information
Scenarios to successfully execute your SQL statements
Scenario 1: Executing SQL statements without expressions.
The SQL statement must not be within quotes.
The $<variable_name> parts of the SQL statement are expressions. In the below example, $id and $book.
Examples:
.png?version=1&modificationDate=1500437287427&cacheVersion=1&api=v2)
email = 'you@example.com'oremail = $emailemp=$emp
Scenario 2: Executing SQL queries with expressions.
The SQL statement must be within quotes.
The + $<variable_name> + parts of the SQL statement are expressions, and must not be within quotes. In the below example, $tablename.
The $<variable_name> parts of the SQL statement are bind parameter, and must be within quotes. In the below example, $id and $book.
"EMPNO=$EMPNO and ENAME=$EMPNAME""emp='" + $emp + "'""EMPNO=" + $EMPNO + " and ENAME='" + $EMPNAME+ "'"
Table name and column names must not be provided as bind parameters. Only values can be provided as bind parameters.
Examples:
.png?version=1&modificationDate=1500437286406&cacheVersion=1&api=v2)
The non-expression form uses bind parameters, so it is much faster than executing N arbitrary SQL expressions.
Using expressions that join strings together to create SQL queries or conditions has a potential SQL injection risk and hence unsafe. Ensure that you understand all implications and risks involved before using concatenation of strings with '=' Expression enabled.
The '$' sign and identifier characters, such as double quotes (“), single quotes ('), or back quotes (`), are reserved characters and should not be used in comments or for purposes other than their originally intended purpose.
Single quotes in values must be escaped
Any relational database (RDBMS) treats single quotes (') as special symbols. So, single quotes in the data or values passed through a DML query may cause the Snap to fail when the query is executed. Ensure that you pass two consecutive single quotes in place of one within these values to escape the single quote through these queries.
For example:
| If String | To pass this value | Use |
|---|---|---|
| Has no single quotes | Schaum Series | |
| Contains single quotes | | 'O''Reilly''s ' |
Examples
Azure SQL - Execute Snap as a Standalone Pipeline
The following pipeline describes how the Snap functions as a standalone Snap in a pipeline:
Extract: The SQL statement, select * from <table_name>, extracts the Azure table data.
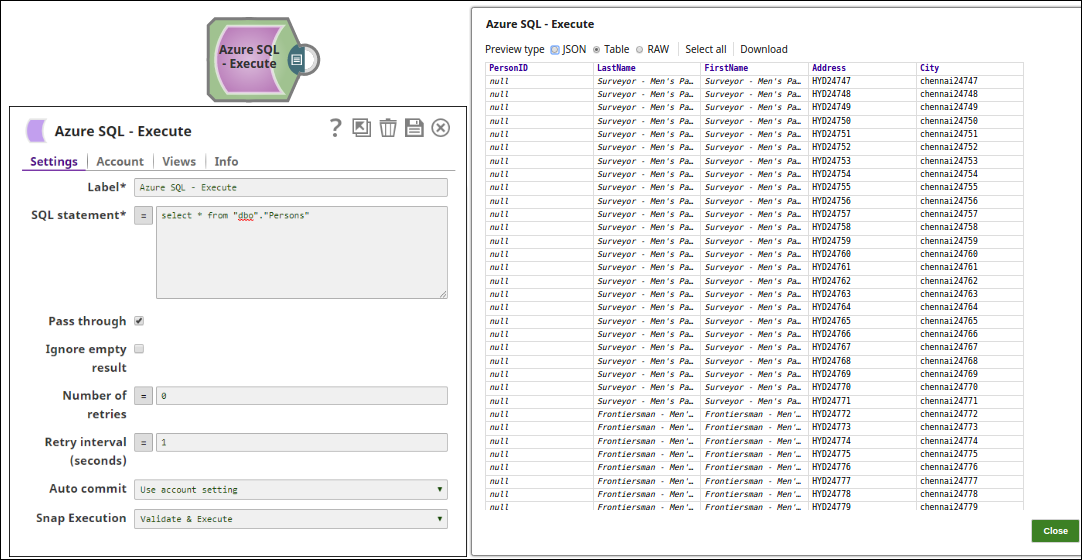
Typical Snap Configurations
The key configuration of the Azure SQL - Execute lies in how you pass the SQL statement to read Azure records. As it applies in SnapLogic, you can pass SQL statements in the following manner:
Without Expression: Directly passing the required SQL statement in the Azure SQL Execute Snap.
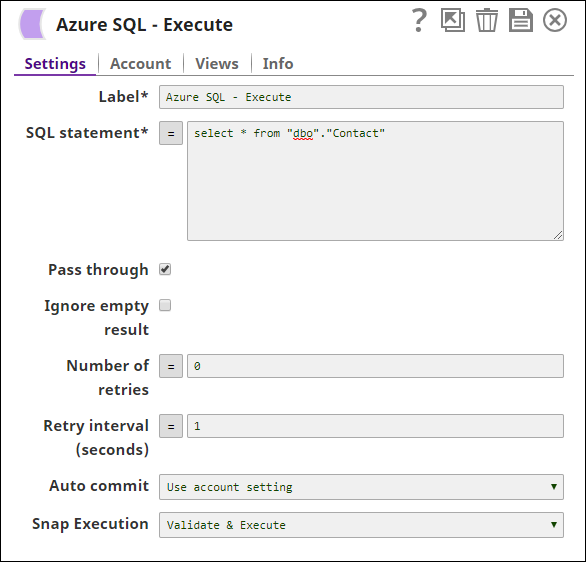
With Expressions
Values from an upstream Snap: The JSON Generator Snap passes the values to be inserted into the table on Azure.
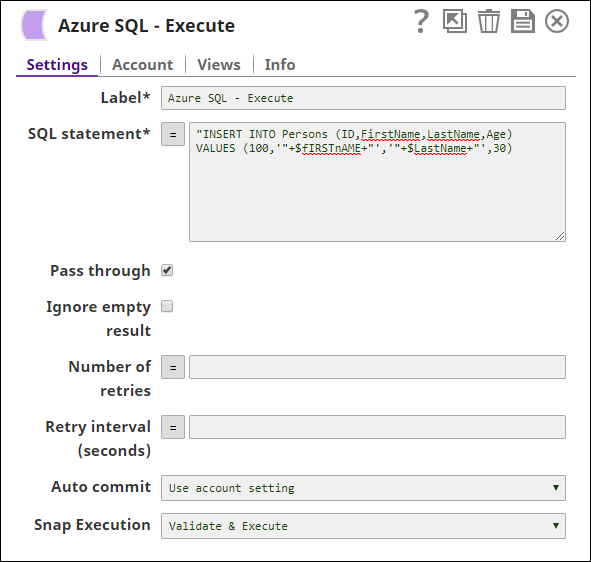
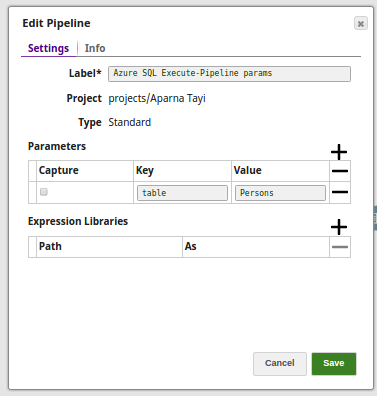
Pipeline Parameter: Pipeline parameter set to pass the required values to the Azure.

Extract, Transform, Load
The following example use case demonstrates a broader business logic involving the ETL transformations, that shows how typically in an enterprise environment, an execute functionality is used. This pipeline reads and moves files from the SQL Server Database to the Azure SQL Database and the Azure SQL Execute Snap reads the newly loaded table on the Azure SQL instance.

Extract: The SQL Server Select Snap reads the data from the SQL Server Database.
Load: The Azure SQL Execute Snap inserts the data into an Azure SQL table.
Read: Another Execute Snap is used to read the data from the newly loaded table on the Azure SQL database.
Downloads
Important steps to successfully reuse Pipelines
- Download and import the pipeline into the SnapLogic application.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.