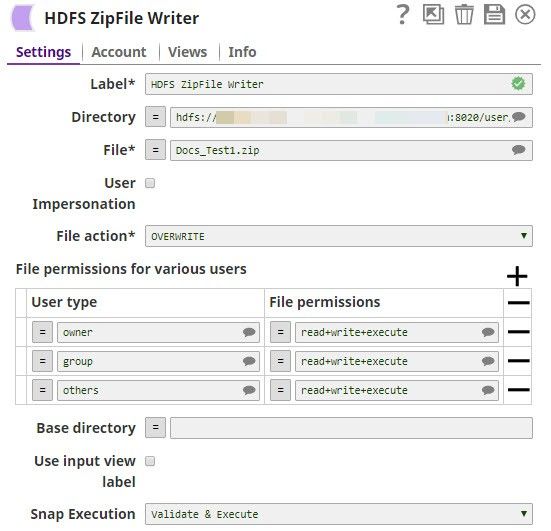
Use the HDFS ZipFile Write Snap to read in-coming data and write it to a ZIP file in an HDFS directory. This Snap also enables you to specify file access permissions for the new ZIP file. You can also configure how the Snap handles the new ZIP file if the destination directory already has another ZIP file with the same name.
For the HDFS protocol, use a SnapLogic on-premises Groundplex and ensure that its instance is within the Hadoop cluster and that SSH authentication is established.
The HDFS protocol supported by this Snap is HDFS 2.4.0.
Expected Input and Output
Expected Input: Binary data stream containing documents to be written to a ZIP file.
Expected Output: Zipped file containing the incoming documents.
Expected Upstream Snaps: Required. Any Snap that offers binary data in its output view. Examples: JSON Formatter, HDFS Reader, File Reader.
Expected Downstream Snaps: Any Snap that takes document data as input. Examples: Mapper, HDFS Reader.
Prerequisites
The user executing the Snap must have Write permissions on the concerned directory.
Configuring Accounts
This Snap uses account references created on theAccountspage of SnapLogic Manager to handle access to this endpoint. See Hadoop Accounts for information on setting up this type of account.
Required. The name for the Snap. Modify this to be more specific, especially if there are more than one of the same Snap in the pipeline.
Directory
The URL for the data source (directory). The Snap supports both HFDS and ABFS(S) protocols.
Syntax for a typical HDFS URL:
Syntax for a typical ABFS and an ABFSS URL:
When you use the ABFS protocol to connect to an endpoint, the account name and endpoint details provided in the URL override the corresponding values in the Account Settings fields.
With the ABFS protocol, SnapLogic creates a temporary file to store the incoming data. Therefore, the hard drive where the JCC is running should have enough space to temporarily store all the account data coming in from ABFS.
Default value: [None]
File
The relative path and name of the file that must be created post execution.
Example:
sample.zip
tmp/another.zip
$filename
Default value: [None]
User Impersonation
Select this check box to enable user impersonation.
For encryption zones, use user impersonation.
Default value: Not selected
For more information on working with user impersonation, click the link below.
User Impersonation Details
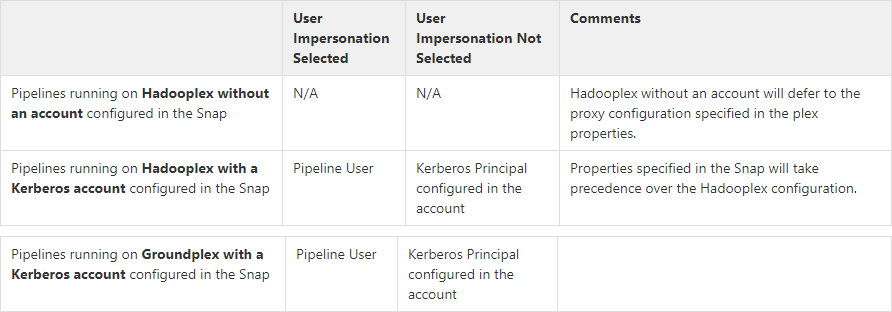
Generic User Impersonation Behavior
When the User Impersonation check box is selected, and Kerberos is the account type, the Client Principal configured in the Kerberos account impersonates the pipeline user.
When the User Impersonation option is selected, and Kerberos is not the account type, the user executing the pipeline is impersonated to perform HDFS Operations. For example, if the user logged into the SnapLogic platform is operator@snaplogic.com, the user name "operator" is used to proxy the super user.
User impersonation behavior on pipelines running on Groundplex with a Kerberos account configured in the Snap
When the User Impersonation checkbox is selected in the Snap, it is the pipeline user who performs the file operation. For example, if the user logged into the SnapLogic platform is operator@snaplogic.com, the user name "operator" is used to proxy the super user.
When the User Impersonation checkbox is not selected in the Snap, the Client Principal configured in the Kerberos account performs the file operation.
For non-Kerberised clusters, you must activate Superuser access in the Configuration settings.
HDFS Snaps support the following accounts:
Azure storage account
Azure Data Lake account
Kerberos account
No account
When an account is configured with an HDFS Snap, user impersonation settings have no impact on all accounts, except the Kerberos account.
File Action
Required. Use this field to specify what you want the Snap to do if the file you want it to create already exists. Available options are: Overwrite, Ignore, and Error.
Overwrite: If the target file exists, the Snap overwrites the file.
Ignore: If the file already exists, the Snap neither throws an exception nor does it overwrite the file, but creates an output document indicating that the new data has been ignored.
Error: The error displays in the Pipeline Run Log if the file already exists.
Default value: Overwrite
File Permissions
File permission sets to be assigned to the file. To assign file permissions:
Click the + button against File permissions. This adds a row to the fieldset.
Click the Suggestible icon in the User type field and select the user type for which you want to enable access. This drop-down offers the following options:
Owner: This is the user account under whose name the new file will be created.
Group: This is the user group to which the user being impersonated belongs.
Others: These are all other users who have at least Read access to the concerned directory.
Click the Suggestible icon in the File permissions field and select the permission you want to enable for the user type selected in the User type field.
Base directory
Enter here the name of the root directory in the ZIP file.
Use input view label
If selected, the input view label is used for all names of the files added to the zip file. Otherwise, the input view ID is used instead, when input the binary stream does not have its content-location in its header. When this option is selected, if there are more than one binary input streams in an input view, for the second input stream and after, the file names will be the input view label appended with '_n'. If the label is in the format of 'name.ext', '_n' will be append to the 'name', e.g. name_2.ext for the second input stream.
Example: If this option is selected, if Base directory is testFolder and the input view label is test.csv, the file name for the first binary input stream in that input view will be testFolder/test.csv, and the second, testFolder/test_2.csv, and the third, testFolder/test_3.csv, and so on.
Default value: Not selected
Snap execution
Select one of the three modes in which the Snap executes. Available options are:
Validate & Execute: Performs limited execution of the Snap, and generates a data preview during Pipeline validation. Subsequently, performs full execution of the Snap (unlimited records) during Pipeline runtime.
Execute only: Performs full execution of the Snap during Pipeline execution without generating preview data.
Disabled: Disables the Snap and all Snaps that are downstream from it.
The binary document header content-location of the HDFS ZipFile Writer input is the name within the ZIP file. (Example: foo.txt). The Snap does not include the 'base directory'. It could contain subdirectories though. On the other hand, the binary document header content-location of the output of the HDFS ZipFile Reader is the name of the ZIP file, the base directory, and the content location provided to the writer. Thus, while each Snap works well independent of each other, it's currently not possible to have a Reader > Writer > Reader combination in a pipeline without using other intermediate Snaps to provide the binary document header information.
Troubleshooting
Writing to S3 files with HDFS version CDH 5.8 or later
When running HDFS version later than CDH 5.8, the Hadoop Snap Pack may fail to write to S3 files. To overcome this, make the following changes in the Cloudera manager:
Go to HDFS configuration.
In Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml, add an entry with the following details:
Name: fs.s3a.threads.max
Value: 15
Click Save.
Restart all the nodes.
Under Restart Stale Services, select Re-deploy client configuration.
Click Restart Now.
Examples
Writing and Reading a ZIP File in HDFS
The first part of this example demonstrates how you can use the HDFS ZipFile Write Snap to zip and write a new file into HDFS. The second part of this example demonstrates how you can unzip and check the contents of the newly-created ZIP file.
Click here to download this pipeline. You can also downloaded this pipeline from the Downloads section below.
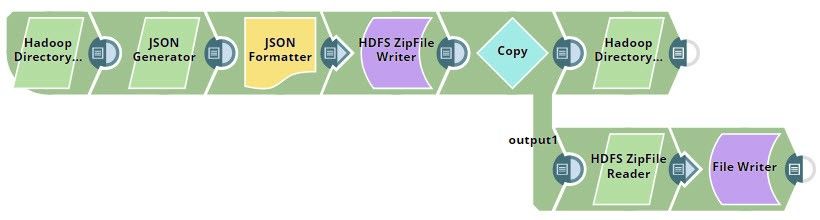
Understanding the Sample Pipeline
Create the pipeline as shown below:
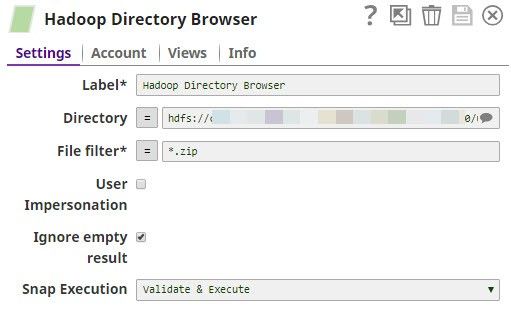
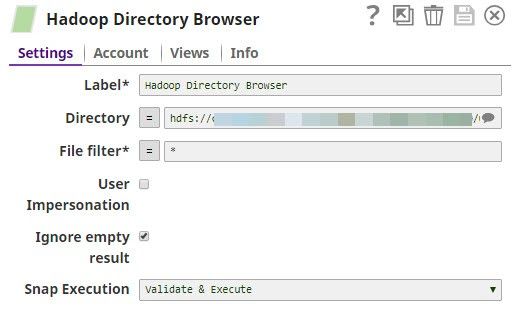
The Hadoop Directory Browser Snap
Use a Hadoop Directory Browser Snap to first check the contents of the target directory. This will help you check whether the new file got added to the HDFS directory as expected, later in the example.
Enter the Directory URL as appropriate and specify the File filter as *.zip. This instructs the Snap to list out all the ZIP files in the target directory.
If the Snap executes as expected, you should see the contents of your target directory, as shown below:
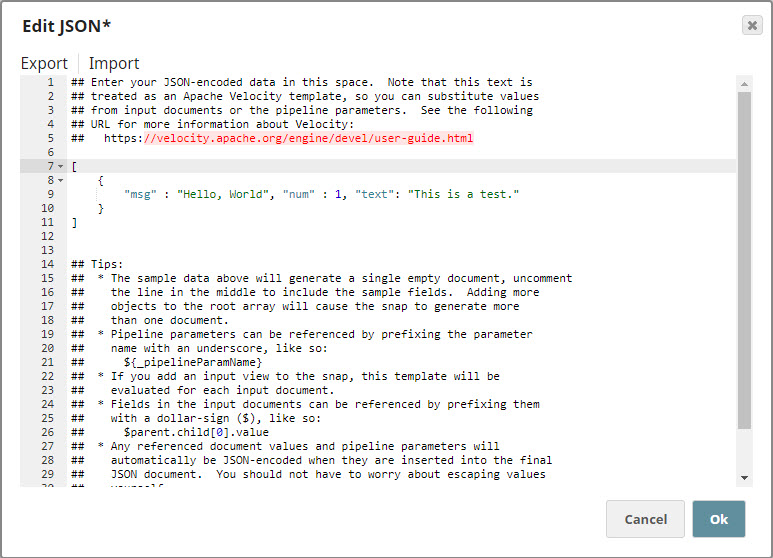
Generating a File for Upload
You now need to choose a file to upload into the target directory. You could either select a file directly or use a JSON Generator Snap coupled with a JSON Formatter Snap, as in the example pipeline.
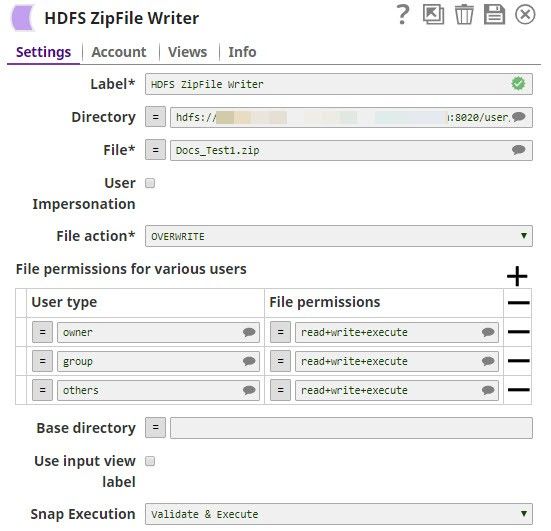
The HDFS ZipFile Writer Snap
Your file is now ready. Configure the HDFS ZipFile Writer Snap to upload the file as a ZIP file into the target directory in HDFS, as shown below.
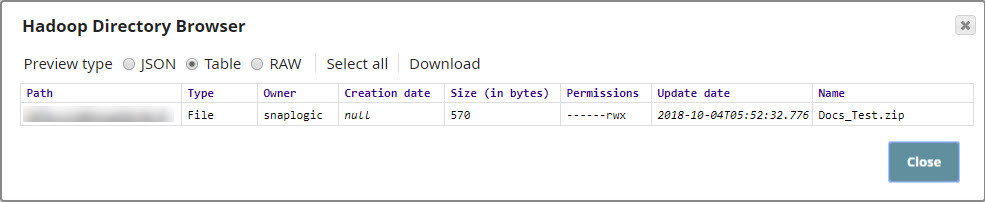
The Hadoop Directory Browser Snap
Use a Copy Snap to perform two tasks after the ZIP file is created: first, to check whether the new file was created as expected and second, to try and read the contents to the newly-created ZIP file from the target HDFS directory.
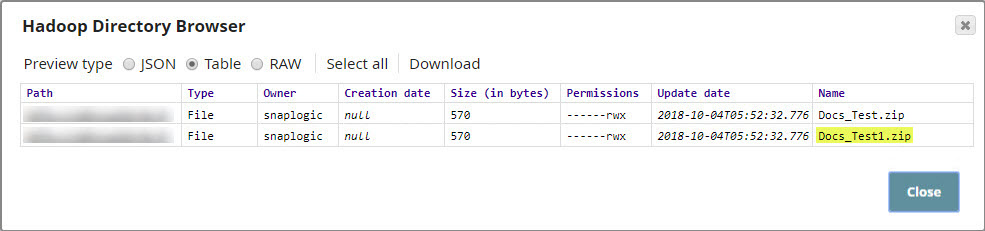
To check whether the new file was created, add an HDFS Directory Browser Snap to the pipeline.
If the ZIP file was created, you should see it in the output, as shown below:
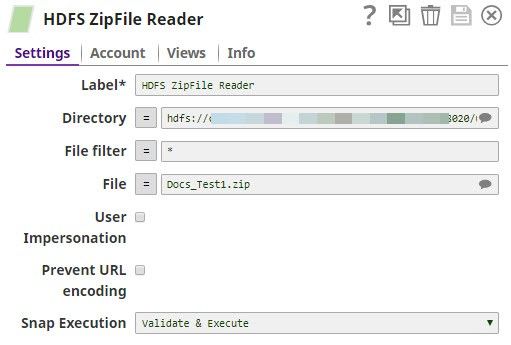
HDFS ZipFile Reader
Once you have confirmed that the new ZIP file has been created, use the HDFS ZipFile Reader Snap to read the new ZIP file. If the contents of the new ZIP file is the same as the contents of the input file, you know that the pipeline works!
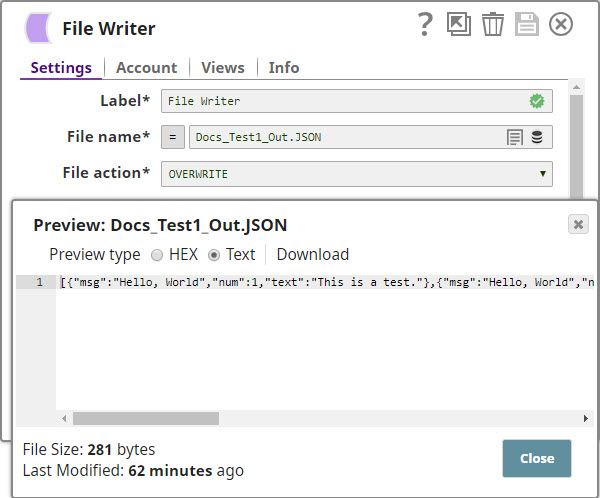
To read the output of the HDFS ZipFile Read Snap, use a File Reader Snap:
If the contents of the new file is the same as the contents of the original file, you know the example works.
Click here to download this Pipeline. You can also downloaded this pipeline from the Downloads section below.
Downloads
File
Modified
No files shared here yet.
Click to view/expand
Release
Snap Pack Version
Date
Type
Updates
February 2025
main29887
Stable
Updated and certified against the current SnapLogic Platform release.
November 2024
439patches29616
Latest
Fixed an issue with the Parquet Writer Snap, where string-formatted timestamps were stored and retrieved as invalid data because of improper handling. Now, the Snap properly handles the string-formatted timestamps through the Timestamp parquet type option. The Timestamp parquet type dropdown option enables you to choose the appropriate Parquet type for your timestamp schema based on the format of the timestamp data.
November 2024
main29029
Stable
Updated and certified against the current SnapLogic Platform release.
August 2024
main27765
Stable
Upgraded the org.json.json library from v20090211 to v20240303, which is fully backward compatible.
May 2024
437patches27226
-
The upgrade of the Azure Storage library from v3.0.0 to v8.3.0 has impacted the Hadoop Snap Pack causing the following issue when using the WASB protocol.
Known Issue
When you use invalid credentials for the WASB protocol in Hadoop Snaps (HDFS Reader, HDFS Writer, ORC Reader, Parquet Reader, Parquet Writer), the pipeline does not fail immediately, instead it takes 13-14 minutes to display the following error:
reason=The request failed with error code null and HTTP code 0. , status_code=error
SnapLogic® is actively working with Microsoft®Support to resolve the issue.
Fixed a resource leak issue with the following Hadoop Snaps, which involved too many stale instances of ProxyConnectionManager and significantly impacted memory utilization.
Enhanced the HDFS Writer Snap with the Write empty file checkbox to enable you to write an empty or a 0-byte file to all the supported protocols that are recognized and compatible with the target system or destination.
May 2024
main26341
Stable
The Azure Data Lake Account has been removed from the Hadoop Snap Pack because Microsoft retired the Azure Data Lake Storage Gen1 protocol on February 29, 2024. We recommend replacing your existing Azure Data Lake Accounts (in Binary or Hadoop Snap Packs) with other Azure Accounts.
February 2024
436patches25902
Latest
Fixed a memory management issue in the HDFS Writer, HDFS ZipFile Writer, ORC Writer, and Parquet Writer Snaps, which previously caused out-of-memory errors when multiple Snaps were used in the pipeline. The Snap now conducts a pre-allocation memory check, dynamically adjusting the write buffer size based on available memory resources when writing to ADLS.
February 2024
435patches25410
Latest
Enhanced the AWS S3 Account for Hadoop with an External ID that enables you to access Hadoop resources securely.
February 2024
main25112
Stable
Updated and certified against the current SnapLogic Platform release.
November 2023
435patches23904
Latest
Fixed an issue with the Parquet Writer Snap that displayed an error Failed to write parquet data when the decimal value passed from the second input view exceeded the specified scale.
Fixed an issue with the Parquet Writer Snap that previously failed to handle the conversion of BigInt/int64 (larger numbers) after the 4.35 GA now converts them accurately.
November 2023
435patches23780
Latest
Fixed an issue related to error routing to the output view. Also fixed a connection timeout issue.
November 2023
main23721
Stable
Updated and certified against the current SnapLogic Platform release.
August 2023
434patches23173
Latest
Enhanced the Parquet Writer Snap with a Decimal Rounding Mode dropdown list to enable the rounding method for decimal values when the number exceeds the required decimal places.
August 2023
434patches22662
Latest
Enhanced the Parquet Writer Snap with the support for LocalDate and DateTime. The Snap now shows the schema suggestions for LocalDate and DateTime correctly.
Enhanced the Parquet Reader Snap with the Use datetime types checkboxthat supports LocalDate and DateTime datatypes.
Behavior change:
When you select the Use datetime types checkbox in the Parquet Reader Snap, the Snap displays the LocalDate and DateTime in the output for INT32 (DATE) and INT64 (TIMESTAMP_MILLIS) columns. When you deselect this checkbox, the columns retain the previous datatypes and display string and integer values in the output.
August 2023
main22460
Stable
Updated and certified against the current SnapLogic Platform release.
May 2023
433patches22180
Latest
Introduced the HDFS Delete, which deletes the specified file, group of files, or directory from the supplied path and protocol in the Hadoop Distributed File System (HDFS).
May 2023
433patches21494
Latest
The Hadoop Directory Browser Snap now returns all the output documents as expected after implementing pagination for the ABFS protocol.
May 2023
main21015
Stable
Upgraded with the latest SnapLogic Platform release.
February 2023
432patches20820
Latest
Fixed an authorization issue that occurs with the Parquet Writer Snap when it receives empty document input.
February 2023
432patches20209
Latest
The Apache Commons Compress library has been upgraded to version 1.22.
February 2023
432patches20139
Latest
The Kerberos Account that is available for a subset of snaps in the Hadoop Snap pack now supports a configuration that enables you to read from and write to the Hadoop Distributed File System (HDFS) managed by multiple Hadoop clusters. You can specify the location of the Hadoop configuration files in the Hadoop config directory field. The value in this field overrides the value that is set on the Snaplex system property used for configuring a single cluster.
February 2023
main19844
Stable
Upgraded with the latest SnapLogic Platform release.
November 2022
main18944
Stable
The AWS S3 and S3 Dynamic accounts now support a maximum session duration of an IAM role defined in AWS.
Fixed an issue in the following Snaps that use AWS S3 dynamic account, where the Snaps displayed the security credentials like Access Key, Secret Key, and Security Token in the logs. Now, the security credentials in the logs are blurred for the Snaps that use AWS S3 dynamic account.
Upgraded with the latest SnapLogic Platform release.
4.27 Patch
427patches13769
Latest
Fixed an issue with the Hadoop Directory Browser Snap where the Snap was not listing the files in the given directory for Windows VM.
4.27 Patch
427patches12999
Latest
Enhanced the Parquet Reader Snap with int96 As Timestamp checkbox, which when selected enables the Date Time Format field. You can use this field to specify a date-time format of your choice for int96 data-type fields. The int96 As Timestamp checkbox is available only when you deselect Use old data format checkbox.
4.27
main12833
Stable
Enhanced the Parquet Writer and Parquet Reader Snaps with Azure SAS URI properties, and Azure Storage Account for Hadoop with SAS URI Auth Type. This enables the Snaps to consider SAS URI given in the settings if the SAS URI is selected in the Auth Type during account configuration.
4.26
426patches12288
Latest
Fixed a memory leak issue when using HDFS protocol in Hadoop Snaps.
4.26
main11181
Stable
Upgraded with the latest SnapLogic Platform release.
4.25 Patch
425patches9975
Latest
Fixed the dependency issue inHadoop Parquet ReaderSnap while reading fromAWS S3. The issue is caused due to conflicting definitions for some of the AWS classes (dependencies) in the classpath.
4.25
main9554
Stable
Enhanced the HDFS Reader and HDFS Writer Snaps with the Retry mechanism that includes the following settings:
Number of Retries: Specifies the maximum number of retry attempts when the Snap fails to connect to the Hadoop server.
Retry Interval (seconds): Specifies the minimum number of seconds the Snap must wait before each retry attempt.
4.24 Patch
424patches9262
Latest
Enhanced the AWS S3 Account for Hadoop to support role-based access when you select IAM role checkbox.
4.24 Patch
424patches8876
Latest
Fixes the missing library error inHadoop Snap Pack when running Hadoop Pipelines in JDK11 runtime.
4.24
main8556
Stable
Upgraded with the latest SnapLogic Platform release.
4.23 Patch
423patches7440
Latest
Fixes the issue inHDFS ReaderSnap by supporting to read and write files larger than 2GB using ABFS(S) protocol.
4.23
main7430
Stable
Upgraded with the latest SnapLogic Platform release.
4.22
main6403
Stable
Upgraded with the latest SnapLogic Platform release.
4.21 Patch
hadoop8853
Latest
Updates the Parquet Writer and Parquet Reader Snaps to support the yyyy-MM-dd format for the DATE logical type.
4.21
snapsmrc542
Stable
Upgraded with the latest SnapLogic Platform release.
4.20 Patch
hadoop8776
Latest
Updates the Hadoop Snap Pack to use the latest version of org.xerial.snappy:snappy-java for compression type Snappy, in order to resolve the java.lang.UnsatisfiedLinkError: org.xerial.snappy.SnappyNative.maxCompressedLength(I)I error.
4.20
snapsmrc535
Stable
Upgraded with the latest SnapLogic Platform release.
4.19 Patch
hadoop8270
Latest
Fixes an issue with the Hadoop Parquet Writer Snap wherein the Snap throws an exception when the input document includes one or all of the following:
Empty lists.
Lists with all null values.
Maps with all null values.
4.19
snaprsmrc528
Stable
Upgraded with the latest SnapLogic Platform release.
4.18 Patch
hadoop8033
Latest
Fixed an issue with the Parquet Writer Snap wherein the Snap throws an error when working with WASB protocol.
Added ADLS Gen2 support for ABFS (Azure Blob File System) and ABFSS protocols.
4.17
ALL7402
Latest
Pushed automatic rebuild of the latest version of each Snap Pack to SnapLogic UAT and Elastic servers.
4.17
snapsmrc515
Latest
Added the Snap Execution field to all Standard-mode Snaps. In some Snaps, this field replaces the existing Execute during preview check box.
4.16
snapsmrc508
Stable
Added a new property, Output for each file written, to handle multiple binary input data in the HDFS Writer Snap.
4.15
snapsmrc500
Stable
Added two new Snaps: HDFS ZipFile Reader and HDFS ZipFile Writer.
Added support for the Data Catalog Snaps in Parquet Reader and Parquet Writer Snaps.
4.14 Patch
hadoop5888
Latest
Fixed an issue wherein the Hadoop snaps were throwing an exception when a Kerberized account is provided, but the snap is run in a non-kerberized environment.
4.14
snapsmrc490
Stable
Added the Hadoop Directory BrowserSnap, which browses a given directory path in the Hadoop file system using the HDFS protocol and generates a list of all the files in the directory. It also lists subdirectories and their contents.
Added support for S3 file protocol in theORC Reader, andORC WriterSnaps.
Added support for reading nested schema in the Parquet Reader Snap.
4.13 Patch
hadoop5318
Latest
Fixed the HDFS Reader/Writer and Parquet Reader/Writer Snaps, wherein Hadoop configuration information does not parse from the client's configuration files.
Fixed the HDFS Reader/Writer and Parquet Reader/Writer Snaps, wherein User Impersonation does not work on Hadooplex.
4.13
snapsmrc486
Stable
KMS encryption support added to AWS S3 account in the Hadoop Snap Pack.
Enhanced the Parquet Reader, Parquet Writer, HDFS Reader, and HDFS Writer Snaps to support WASB and ADLS file protocols.
Added the AWS S3 account support to the Parquet Reader and Writer Snaps.
Added second input view to the Parquet Reader Snap that when enabled, accepts table schema.
Supported with AWS S3, Azure Data Lake, and Azure Storage Accounts.
4.12 Patch
hadoop5132
Latest
Fixed an issue with the HDFS Reader Snap wherein the pipeline becomes stale while writing to the output view.
4.12
snapsmrc480
Stable
Upgraded with the latest SnapLogic Platform release.
4.11 Patch
hadoop4275
Latest
Addressed an issue with Parquet Reader Snap leaking file descriptors (connections to HDFS data nodes). The Open File descriptor values work stable now,
4.11
snapsmrc465
Stable
Added Kerberos support to the standard mode Parquet Reader and Parquet Writer Snaps.
4.10 Patch
hadoop4001
Latest
Supported HDFS Writer to write to the encryption zone.
4.10 Patch
hadoop3887
Latest
Addressed the suggest issue for the HDFS Reader on Hadooplex.
4.10 Patch
hadoop3851
Latest
ORC supports read/write from local file system.
Addressed an issue to bind the Hive Metadata to Parquet Writer Schema at Runtime.
4.10 Patch
hadoop3838
Latest
Made HDFS Snaps work with Zone encrypted HDFS.
4.10
snapsmrc414
Stable
Updated the Parquet Writer Snap withPartition byproperty to support the data written into HDFS based on the partition definition in the schema in Standard mode.
Support for S3 accounts with IAM Roles added to Parquet Reader and Parquet Writer
HDFS Reader/Writer with Kerberos support on Groundplex (including user impersonation).
4.9 Patch
hadoop3339
Latest
Addressed the following issues:
ORC Reader passing, but ORC Writer failing when run on a Cloudplex.
ORC Reader Snap is not routing error to error view.
Intermittent failures with the ORC Writer
4.9.0 Patch
hadoop3020
Latest
Added missing dependency org.iq80.snappy:snappy to Hadoop Snap Pack.
4.9
snapsmrc405
Stable
Upgraded with the latest SnapLogic Platform release.
4.8
snapsmrc398
Stable
Snap-aware error handling policy enabled for Spark mode in Sequence Formatter and Sequence Parser. This ensures the error handling specified on the Snap is used.
4.7.0 Patch
hadoop2343
Latest
Spark Validation: Resolved an issue with validation failing when setting the output file permissions.
4.7
snapsmrc382
Stable
Updated the HDFS Writer and HDFS Reader Snaps with Azure Data Lake account for standard mode pipelines.
HDFS Writer: Spark mode support added to write to a specified directory in an Azure Storage Layer using the wasb file system protocol.
HDFS Reader: Spark mode support added to read a single file or an HDFS directory from an Azure Storage Layer.
4.6
snapsmrc362
Stable
The following Snaps now support error view in Spark mode: HDFS Reader, Sequence Parser.
Resolved an issue in HDFS Writer Snap that sends the same data in output & error view.
4.5
snapsmrc344
Stable
HDFS Reader and HDFS Writer Snaps updated to support IAM Roles for Amazon EC2.
Support for Spark mode added to Parquet Reader, Parquet Writer
The HBase Snaps are no longer available as of this release.
4.4.1
Stable
Resolved an issue with Sequence Formatter not working in Spark mode.
Resolved an issue with HDFSReader not using the filter set when configuring SparkExec paths.
4.4
Stable
NEW! Parquet Reader and Writer Snaps
NEW!ORC Reader and Writer Snaps
Spark support added to the HDFS Reader, HDFS Writer, Sequence Formatter, and Sequence Parser Snaps.
Behavior change: HDFS Writer in SnapReduce mode now requires the File property to be blank.
4.3.2
Stable
Implemented wasbs:// protocol support in Hadoop Snap Pack.
Resolved an issue with HDFS Reader unable to read all files under a folder (including all files under its subfolders) using the ** filter.