...
In this article
...
In this article
...
| title | General Guidelines. Remove Before Publishing. |
|---|
...
- Always use title casing for Heading formats 1 and 2.
- Always use active voice.
- Do not use "Please" anywhere in the document.
- Screenshots
- Always use the New Form UI.
- Be optically similar. Max size 1000 px or corresponding gridline size as in the style guide.
- Do not capture Snap borders when showing configurations in the Examples section. You can add a border in the editor here.
- See Image Style Guide for details.
- Examples must always use first-person plural references. You can use the second-person if needed depending upon the example's content.
| Table of Contents | ||||
|---|---|---|---|---|
|
| Multiexcerpt macro | ||||||
|---|---|---|---|---|---|---|
| ||||||
An account for the Snap You must
An account for the Snap You must define an account for this Snap to communicate with your target CDW. Click the account specific to your target CDW below for more information: |
Overview
You can use this Snap to pass (switch) case arguments that define how the source data should be treated in different scenarios.
...
Prerequisites
- Valid client ID.
- A valid account with the required permissions.
None.
Support for Ultra Pipelines
- Works in Ultra Pipelines.
- Works in Ultra Pipelines if....
- Does not support Ultra Pipelines.
Limitations
None.
The Snap includes these cases accordingly in the incremental SQL statement.
Snap Type
ELT Case Expression Snap is a TRANSFORM-type Snap that allows you to perform a CASE operation (action based on the condition satisfied out of a list of conditions/cases) on the dataset.
Prerequisites
Valid accounts and access permissions to connect to the following:
Source: AWS S3, Redshift, Azure Cloud Storage, or Google Cloud Storage
Target: Snowflake, Redshift, Azure Synapse, Databricks Lakehouse Platform, or BigQuery
Limitations & Known Issues
None.
Snap Input and Output
Input/Output | Type of View | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input | Document |
Binary
Binary or Document
|
...
- Mapper Snap
- Copy Snap
- ..
...
| A document containing the SQL query that yields the data required to perform the SQL case operations. |
Output | Document |
...
Binary or Document
|
...
- ..
- ..
...
|
| A document containing the incremental SQL query that includes the SQL case expressions defined in the Snap. |
Snap Settings
| Note |
|---|
...
| title | Documenting Fields Based On Data Type/UI Element |
|---|
**Delete Before Publishing**
Choose from the following sentences to document specific field types.
...
|
Field Name | Type | Description |
|---|---|---|
Label* | String | Specify a unique label for the Snap. Default Value: ELT Case Expression |
Get preview data | Checkbox | Select this checkbox to include a preview of the query's output. The Snap performs limited execution and generates a data preview during Pipeline validation |
...
Check boxes:
- If selected, <Snap behavior>.
If selected, an empty file is written when the incoming document has no data. - If selected, <behavior>. If not selected/Otherwise, <behavior>
Use "If not selected" if the first sentence is long.
If selected, the Snap uses the file path value as is. Otherwise, the Snap uses the file path value in the URL.
If selected, an empty file is written when the incoming document has empty data. If there is no incoming document at the input view of the Snap, no file is written regardless of the value of the property.
- Select to <action>
Use this if the behavior is binary. Either this or that, where the converse behavior is apparent/obvious.
Select to execute the Pipeline during validation.
Text Fields
- Describe what the user shall specify in this field. Additional details, as applicable, in a separate sentence. Include caveats such as the field being conditionally mandatory, limitations, etc.
Enter the name for new account.
Specify the account ID to use to log in to the endpoint.
Required if IAM Role is selected.
Do not use this field if you are using batch processing.
Numeric Text Fields
- Describe what the field represents/contains. Additional details, as applicable, in a separate sentence. Include caveats such as the field being conditionally mandatory, limitations, etc. Include special values that impact the field's behavior as a bullet list.
The number of records in a batch.
The number of seconds for which you want the Snap to wait between retries.
The number of seconds for which the Snap waits between retries.
Use the following special values:
* 0: Disables batching.
* 1: Includes all documents in a single request.
| Note |
|---|
|
...
Field Name
...
Field Dependency
...
Description
Default Value:
Example:
...
Label*
...
None.
...
Specify a unique label for the Snap.
Default Value: Channel Operations
Example: Delete Member
...
Number of records
...
Sampling Type is Number of records.
...
Enter the number of records to output.
...
Field set
Specify advanced parameters that you want to include in the request.
This field set consists of the following fields:
Field 1
Field 2
Field 3
...
Field 1*
...
Debug mode checkbox is not selected.
Default Value: <value> or None.
Example: <value>
...
Field 2
...
Examples
Excluding Fields from the Input Data Stream
We can exclude the unrequired fields from the input data stream by omitting them in the Input schema field set. This example demonstrates how we can use the <Snap Name> to achieve this result:
<screenshot of Pipeline/Snap and description>
Download this Pipeline.
Downloads
...
.
The number of records displayed in the preview (upon validation) is the smaller of the following:
Rendering Complex Data Types in Databricks Lakehouse Platform Based on the data types of the fields in the input schema, the Snap renders the complex data types like map and struct as object data type and array as an array data type. It renders all other incoming data types as-is except for the values in binary fields are displayed as a base64 encoded string and as string data type. Default Value: Not selected | ||||
Pass through | Checkbox | Select this checkbox to specify that the Snap must include the incoming document (SQL query) in its output document.
| ||
Alias | String | Specify the alias name to use for the case arguments specified. Default Value: None. | ||
Case Arguments | Specify your case arguments using this fieldset. A case argument is essentially an action to perform on the source data when a specific condition is met. Ensure that you specify mutually exclusive case arguments. Specify each value in a separate row. Click This field set consists of the following fields:
| |||
When | String/Expression | Specify the case (condition to be met). Default Value: None. | ||
Then | String/Expression | Specify the action to be performed when the corresponding case (condition) is met. | ||
Else | String/Expression | Specify the action to be performed if none of the case arguments defined is satisfied. Default Value: None. | ||
Troubleshooting
Error | Reason | Resolution |
|---|
...
Batch execution failed
...
The Pipeline ended before the batch could complete execution due to a connection error.
Verify that the Batch size field is configured to handle the inputs properly. If you are not sure when the input data is available, configure this field as zero to keep the connection always open.
Invalid placement of ELT Case Expression snap | ELT Case Expression Snap cannot be used at the start of a Pipeline. | Move the ELT Case Expression Snap to either the middle or the end of your Pipeline. |
The Snap has not been configured properly. | THEN clause expression can not be empty | Ensure that you provide all the THEN clause expressions. |
Examples
Updating a Dataset with New Values Based on Existing Values
We want to read a dataset from a file in S3 and define a new (alias) column for the target table to contain transformed values based on the values in the id column. We can use the following Pipeline for this purpose.

We begin with an ELT Select Snap to read the data from the source table (default.sql_case_expression_src) in S3. We associate a corresponding ELT Database Account (connecting to S3 location that contains the source file) for this Snap. In this example, the account is configured to write transformed data into a Snowflake database.
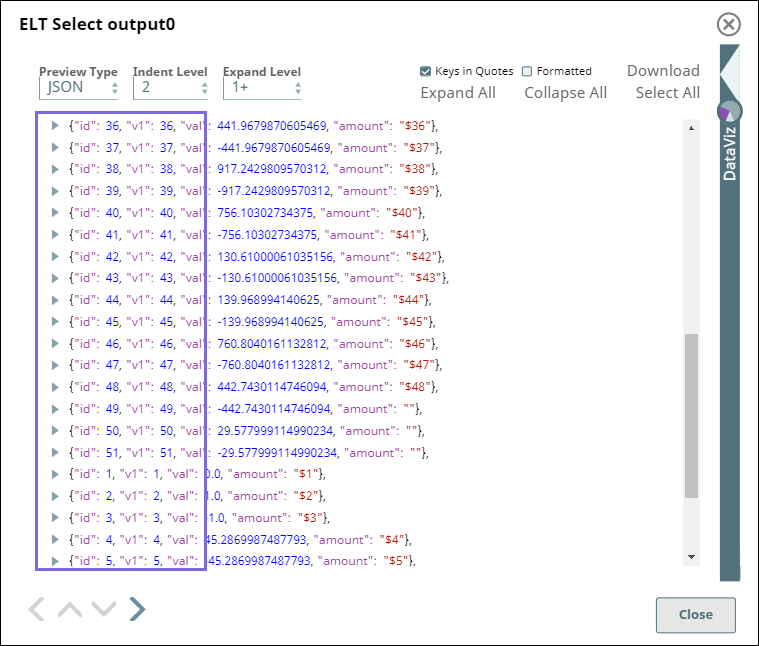
This Snap produces a preview output as shown below:
Next, we configure an ELT Case Expression Snap with the following settings:
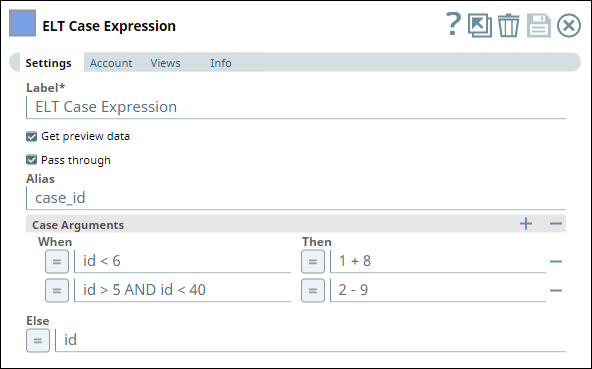
Get preview data (to allow comparison of row values in this example).
Pass through (to allow comparison of row values in this example).
Alias as case_id.
The following Case Arguments:
If id < 6, then value of case_id is 1 + 8 (= 9).
If id > 5 AND id < 40, then value of case_id is 2 - 9 (= -7).
And the Else condition as the value in id column as is.
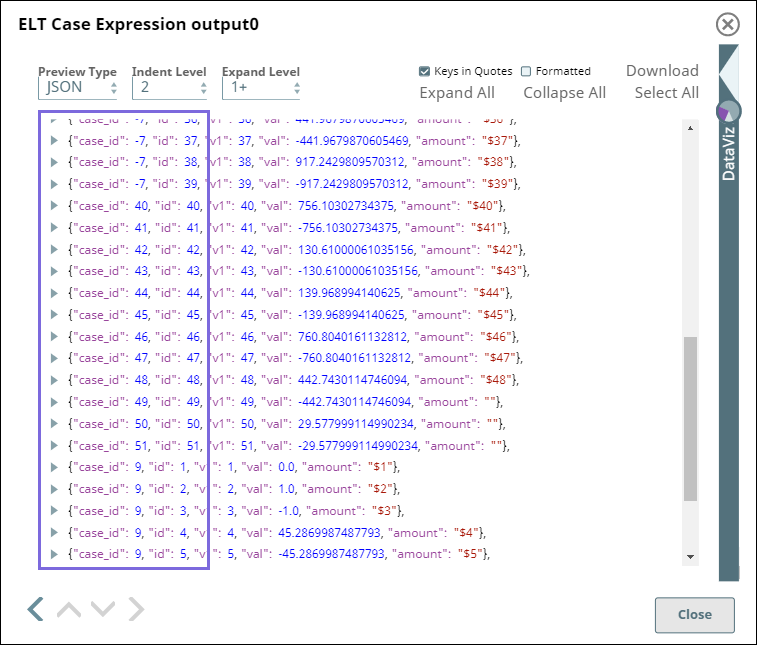
If you compare the highlighted areas in the above images (the two Snap output previews), you can identify that the values for case_id are calculated based on the case arguments we passed.
Then, to conclude this example, we write the transformed data to a table (default.sql_case_expression_tc3) in Snowflake database using an ELT Insert Select Snap.
Downloads
| Note |
|---|
Important Steps to Successfully Reuse Pipelines
|
| Attachments | ||||
|---|---|---|---|---|
|
...
...
Snap Pack History
| Expand |
|---|
...
See ELT Snap Pack |
...
...
See Also
...
...