Best Practices for Ultra Tasks
- John Brinckwirth
- Ankur Parekh
- Chandna Mitra
In this Article
Performance
Performance of an Ultra Pipeline largely depends on the response times of the end-system applications to which the Task connects. An Ultra Pipeline containing a large number of high latency endpoint Snaps can result in a congestion of documents, building all the way up through the upstream Snaps to the FeedMaster, until the FeedMaster queue can no longer hold the messages. You can avoid this situation by either creating multiple instances of the Ultra Pipeline or by using the Pipeline Execute with the Reuse functionality enabled and the Pool Size field set to greater than one. Multiple instances of an Ultra Pipeline ensures that even if one instance is slow, others are available to consume documents and keep the FeedMaster queue flowing; a situation you can manage with the Max In-Flight setting on the Task form.
Likewise, you can use a Router Snap in each instance of the pipeline to distribute the documents across multiple endpoint Snaps and improve the performance and add parallel processing capability to an instance. This functionality is in addition to the built-in parallel computation capability of a pipeline which implies that at a given point in time, each Snap in a pipeline is processing a different document.
Scaling
Scaling can be attained by increasing the number of instances in an Ultra Pipeline. The total number of instances required for an Ultra Pipeline is a direct function of the expected response time: the resource utilization of the node (when a single instance of the Task is running) and the functional load on the Snaplex from other pipeline runs. When execution nodes are highly utilized, adding more execution nodes allows the instances of the Task to be distributed horizontally and scaled out across the Snaplex.
High availability Architecture
To avoid service disruption and enable high availability, use a load balancer with two FeedMasters and two execution nodes as the minimum architecture for Ultra Pipeline setup. This architecture also avoids a single point of failure from the FeedMaster or execution node.
Monitoring Tasks in SnapLogic Manager
Each Task is listed in the Manager > Project > Task. To view the number of documents received or processed by each instance of the Task, a drop down menu lists the details of the Task.
Use the Details menu to view the Pipeline Execution stats and monitor documents received by each Snap in the Ultra Pipeline instance. Because the detailed view lists only the documents received by that instance of the Task, a more advanced monitoring plan might be required in case of multiple instances to get an overview of the documents, queues, and subscribers.
Document lineage hierarchy
Every incoming document in an Ultra Pipeline Snap must maintain its lineage across the pipeline. This operation allows the FeedMaster to use the correlation ID to tie the request to the response. To avoid losing a the lineage and identity of a static web service or file, use a Join Snap with a static key to join the static information with each request document. The example shown below demonstrates the usage of a Join Snap with a static configuration file for parameter mapping.
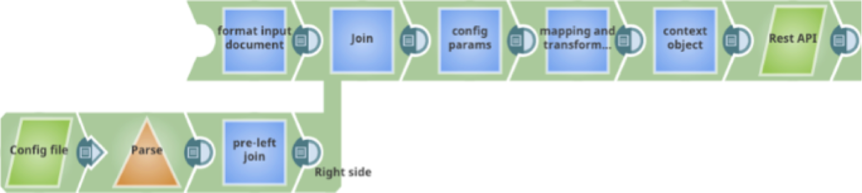
Child Pipelines in Parent Ultra Pipelines
You can also call child (nested) Pipelines through Tasks from Ultra Pipelines by using the Pipeline Execute Snap. However, you should apply error handling to child Ultra Pipelines so that errors occurring in any Snaps can be returned to the parent Pipeline along with the information on the Snap that failed the document processing. You can add error views to the crucial Snaps in the parent Pipeline, then introduce the error views to the Rest Get Snap calling the child Ultra Pipeline.
Pipeline Execute Snap Reuse Mode
Usage Guidelines and Limitations
Ultra Tasks have the following limitations:
- Snaps that wait until something is completed, such as Aggregate, Sort or Join, should not be used in Ultra Tasks. Join Snaps might work with some restrictions. Learn more.
- DB Snaps that write to the database must have the batch size in the account set to one; otherwise, they do not see the effect of the writes.
- For the JSON Formatter Snap, select the 'Format each document' option
- For the XML Formatter Snap, clear the Root Element field
Script and Execute Script Snaps need to pass the original document to the write() method for the output view. The following example shows the body of the loop in a JavaScript:
The original document is needed so that lineage can be maintained.
- If an Ultra Pipeline has an unlinked input view, then it should also have one or more unlinked output views as well.
- By default, if the first run of an Ultra Pipeline fails, SnapLogic attempts to run it for a total of five times. However, you can configure the number of times you want Ultra Pipelines from a specific Snaplex to run by configuring the maximum number of allowed retries for the Pipeline. To do so, modify the
ultra.max_redelivery_countparameter in Global Properties in Snaplex Update to indicate the number of times you want a failed Ultra Pipeline to run. - The maximum payload per request for an Ultra Task is based on the following calculation: 60% of the Java Virtual Machine heap size divided by 16. For example, if the JVM heap size is 10 GB, then the maximum size for the request payload is 375 MB per request (
0.6 * 10 GB / 16). You cannot change Pipeline parameters at run time. These parameters are specified in the Pipeline itself or when the task is created. They are set at pipeline startup, which only happens on initiation, not per document.
As a workaround, the Snaps with limitations may be used in a child Pipeline and invoke locally using the Pipeline Execute Snap. Since this does not require communicating with the Control Plane, the local invocation can be real quick.
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.