In this article
Overview
The Salesforce SOQL Snap is a Read-type Snap that retrieves object records from Salesforce using a Salesforce Object Query Language (SOQL) query. See Introduction to SOQL and SOSL for more information.
Prerequisites
None.
Support for Ultra Pipelines
Works in Ultra Task Pipelines.
Limitations
- For a Salesforce SOQL Snap using the REST API, certain network failures while reading a REST response may result in a socket timeout exception that will not retire.
- When using Primary Key (PK) Chunking mode in this Snap, the output document schemas in preview mode and execution mode may differ. For more information, see the Note under PK Chunking.
- This Snap performs batch processing, that is, a batch of input documents are processed for each HTTP request sent to Salesforce. Values of all the expression-enabled fields must remain constant during the Snap execution or validation. Hence, all expression fields can support Pipeline parameters only when they are expression-enabled. The input data parameters are not supported for expression fields, for example, $serviceVersion.
Known Issues
- None.
Snap Views
| Type | Format | Number of Views | Examples of Upstream and Downstream Snaps |
|---|---|---|---|
| Input | Document | Min: 0 Max: 1 |
|
| Output | Document | Min: 1 Max: 1 |
|
Snap Settings
| Field | Field Type | Description | |
|---|---|---|---|
Label* | String | Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. Default Value: Salesforce SOQL | |
Service Version* | String/Suggestion | Specify the version number associated with the Salesforce service that you want to connect to. Alternatively, click the Suggestion | |
Salesforce API | Dropdown list | Select the Salesforce API mode to Bulk API or REST API. If you select Bulk API, the Object Type field becomes mandatory | |
SOQL Query* | String/Expression | Define the SOQL query statement. You can enter a JavaScript expression, which is evaluated each time the Snap is executed. As shown in the second example below, for each document received from the input view, the
Default value: [None] Using quotes in the WHERE clause
| |
Batch size
| Integer | Specify the number of records to process in a batch. This refers to the number of records in each batch during the download of large query results. Each batch read requires an API call against Salesforce to retrieve the set of records. This Snap does not honor the selection of the Match Data Type checkbox when the valued entered for Batch Size is greater than 50,000.
Default Value: 2000 | |
Object Type* | String | Specify the value for object type that enables you to define the name of the Salesforce object, such as Account. It is not required in REST API. However, SFDC requires it in Bulk API. | |
Polling Interval* | Integer | Specify the polling interval in seconds for the Bulk API query execution. At each polling interval, the Snap checks the status of the Bulk API query batch processing. Maximum value: 60 | |
Polling Timeout* | Integer | Specify the polling timeout in seconds for the Bulk API query batch execution. If the timeout occurs while waiting for the completion of the query batch execution, the Snap throws a SnapExecutionException. | |
Include Deleted records | Checkbox | Select this checkbox to include deleted records in the query result. This feature is supported in REST API version 29.0 or later and Bulk API version 39.0 or later. Default Value: Not selected | |
Pass Through | Checkbox | Select this checkbox to pass the input document through to the output view under the key 'original'. This property is applicable for REST and Bulk APIs. Default Value: Selected | |
Ignore Empty Result | Checkbox | Select this checkbox to ignore empty result, so no document will be written to the output view when the operation does not produce any result. If you deselect this checkbox and select Pass Through, the input document will be passed through to the output view. If you do not select both the checkboxes, Ignore Empty Result and Pass Through, the Snap writes an empty output as below: [{}]
This property does not apply when you run the Snap in Bulk API mode. When you run the Snap in Bulk API mode and the operation does not produce any result, the Snap does not pass the input document to the output view even if the Pass Through checkbox is selected. Default value: Selected | |
Bulk Content Type | Dropdown list | Select the content type for Bulk API: JSON or XML.
Default Value: XML | |
Match Data type | Checkbox | Select this checkbox to match the data types of the Bulk API results with the data types of the REST API. This property applies only when the content type is XML for Bulk API (it does not apply to JSON). If the Bulk content type is XML, Salesforce.com returns all values as strings. If Match data type is selected, the Snap attempts to convert string values to the corresponding data types if the original data type is one of the following: boolean, integer, double, currency, or percent. This property is ignored in REST APIs or when the Bulk Content Type is JSON. For Bulk API, Salesforce.com does not return any value for null. Default Value: Not selected | |
| Escape Single Quotes in Parameter Values | Checkbox | Select this checkbox to escape single quotes in the parameter values when the SOQL query property is expression-enabled. You must use this feature when the WHERE clause values are parameterized and contain single quotes. For example, "SELECT Name,Email FROM Contact WHERE Name='" + $Name + "'". Default Value: Selected | |
| Preview in Bulk API | Checkbox | Select this checkbox to view the preview in Bulk API. If you select this option and the Salesforce API property is Bulk API, the Snap is executed in Bulk API during the preview. If the query is expected to take long to complete its execution, the preview will also take longer or fail with a timeout error. Users may add "LIMIT 50" to the query to get the preview result fast. Default Value: Not selected | |
| Number of Retries | Integer | Specify the maximum number of retry attempts in case of a network failure.
Minimum value: 0 Default Value: 1
| |
| Retry Interval (seconds) | Integer | Specify the minimum number of seconds for which the Snap must wait before attempting recovery from a network failure. Minimum value: 0 Default Value: 1 | |
Advanced Properties | Use this field set to set advanced properties. By default, the advanced properties are not required and is an empty table property. Click
| ||
| Properties | Dropdown list | Select either of the following properties:
Default Value: Use temp files in PK-Chunking | |
Use temp files in PK-Chunking | Enter true if Groundplex is located where the network connection to SFDC is relatively slow. This will have the Snap in PK-Chunking download CSV files into compressed temporary local files in order to prevent SFDC to close input streams prematurely. Ensure that the Goundplex node has sufficient free disk space. Compressed local files are less than 10% of the total CSV data size. Setting this property to true may also be necessary if any of the downstream Snaps are relatively slow in processing the document stream. By default, the Snap in PK-Chunking downloads, parses and writes to the output view in streaming mode without using large memory or temporary files. In a normal network condition, this streaming mode is efficient and scalable. However, it has been observed that SFDC tends to close HTTP input streams prematurely if client apps pause reading the input stream momentarily to perform other processing. | ||
Number of threads in PK-Chunking | In PK-Chunking, the Snap invokes multiple threads to download CSV files in parallel with one CSV file per each thread. The maximum number of threads is 8 by default, but a lower number may be more efficient if the network connection to SFDC is relatively slow or downstream Snaps are slow in processing documents. | ||
| Validate record count downloaded in Bulk API | This property applies to Bulks API with Batch size 10,000 or smaller (not including PK Chunking). If set to true, the Snap checks if the number of records downloaded is the same as the one processed in Salesforce.com. Mismatch in Record Count - Error View This property is inherently applied with its default value when the user doesn't explicitly configure it, if it is enabled (set to true) it is advisable that the error view be enabled to allow the Snap to send the output to error view in case of record count mismatch. | ||
| Values | String/Integer | Specify the value for property selected in the Properties field. The default values are:
| |
Snap Execution | Dropdown list | Page lookup error: page "Anaplan Read" not found. If you're experiencing issues please see our Troubleshooting Guide. | |
Temporary Files
During execution, data processing on Snaplex nodes occurs principally in-memory as streaming and is unencrypted. When larger datasets are processed that exceeds the available compute memory, the Snap writes Pipeline data to local storage as unencrypted to optimize the performance. These temporary files are deleted when the Snap/Pipeline execution completes. You can configure the temporary data's location in the Global properties table of the Snaplex's node properties, which can also help avoid Pipeline errors due to the unavailability of space. For more information, see Temporary Folder in Configuration Options.PK Chunking
PK chunking splits bulk queries on very large tables into chunks based on the record IDs, or primary keys, of the queried records. Each chunk is processed as a separate batch that counts toward your daily batch limit. PK chunking is supported for the following objects: Account, Campaign, CampaignMember, Case, Contact, Lead, LoginHistory, Opportunity, Task, User, and custom objects.
PK chunking works by adding record ID boundaries to the query with a WHERE clause, limiting the query results to a smaller chunk of the total results. The remaining results are fetched with additional queries that contain successive boundaries. The number of records within the ID boundaries of each chunk is referred to as the chunk size. The first query retrieves records between a specified starting ID and the starting ID plus the chunk size, the next query retrieves the next chunk of records, and so on. Since Salesforce.com appends a WHERE clause to the query in the PK Chunking mode, if SOQL Query has LIMIT clause in it, the Snap will submit a regular bulk query job without PK Chunking. See PK Chunking Header for more details.
If 100,000 or 250,000 is selected for Batch size, the value is used as a chunk size in the PK Chunking. Note the chunk size applies to the number of records in the queried table rather than the number of records in the query result. For example, if the queried table has 10 million records and 250,000 is selected for Batch size, 40 batches are created to execute the bulk query job. One additional control batch is also created and it does not process any record. The status of the submitted bulk job and its batches can be monitored by logging onto the your Salesforce.com account in a web browser and going to Setup > Administration Setup > Monitoring > Bulk Data Load Jobs.
PK Chunking requires Service version 28.0 or later. Therefore, if 100,000 or 250,000 is selected for Batch size and Service version is older than 28.0, the Snap submits a regular bulk query job without PK Chunking.
The output document schemas in preview mode (validation) and execution mode for this Snap may differ when using Primary Key (PK) Chunking mode. This is because the Snap intentionally generates the output preview using regular Bulk API instead of PK Chunking, to reduce the costs involved in the PK Chunking operation.
Salesforce recommends use of PK Chunking if the target Salesforce object (table) is relatively large (for example, more than few 100,000 records).
CSV files are generated as a result of PK Chunking Bulk API request in Salesforce.com. The Snap downloads them into temporary files in local disk of the instance where the pipeline is executed. Therefore, users should make sure sufficient free disk space is available for all CSV files. These temporary files are removed when the CSV parsing is completed.
Example
Pipeline: Data from Salesforce.com and ServiceNow: This pipeline makes use of Salesforce SOQL Snap and illustrates how to work with data from Salesforce and ServiceNow.
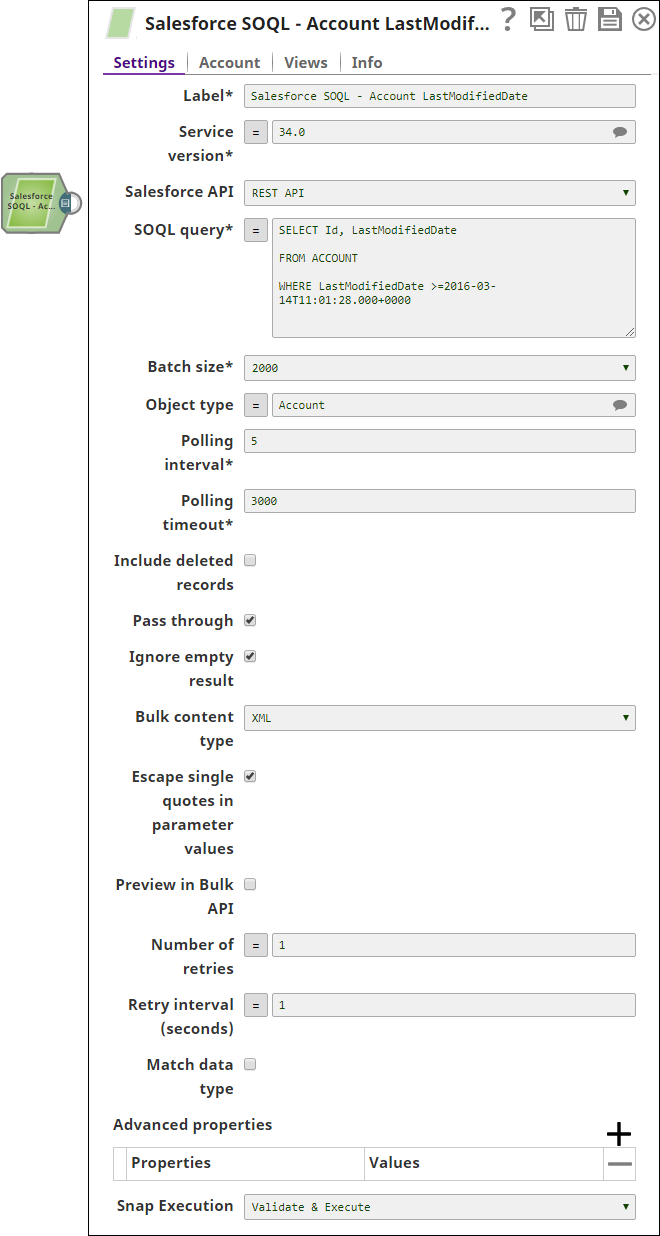
The following Salesforce SOQL Snap shows how the Snap is configured and how the object records are read using SOQL. The SOQL/query retrieves records from Account object that were last modified on a specified date:
Successful execution of the Snap gives the following preview:
.png?version=1&modificationDate=1489698541194&cacheVersion=1&api=v2&width=453&height=413)