Salesforce Read
- Kalpana Malladi
- Aparna Tayi (Unlicensed)
- Lakshmi Manda (Deactivated)
In this article
Overview
Salesforce Read is a Read-type Snap that provides the ability to retrieve all records for all fields of a Salesforce object from Salesforce.
Prerequisites
None.
Support for Ultra Pipelines
Works in Ultra Task Pipelines.
Limitations
- When using Primary Key (PK) Chunking mode in this Snap, the output document schemas in preview mode and execution mode may differ. For more information, refer to the note in PK Chunking.
When you run more than 10 Salesforce Snaps simultaneously, the following error is displayed
“Cannot get input stream from next records URL" or "INVALID_QUERY_LOCATOR"
We recommend that you not use more than 10 Salesforce Snaps simultaneously because this might lead to the opening of more than 10 query cursors in Salesforce. Refer to this Salesforce Knowledge Article for more information.
Known Issues
None.
Snap Views
| Type | Format | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
| Input | Document | Min: 0 Max: 1 | Mapper Copy | This Snap has at most one input view. |
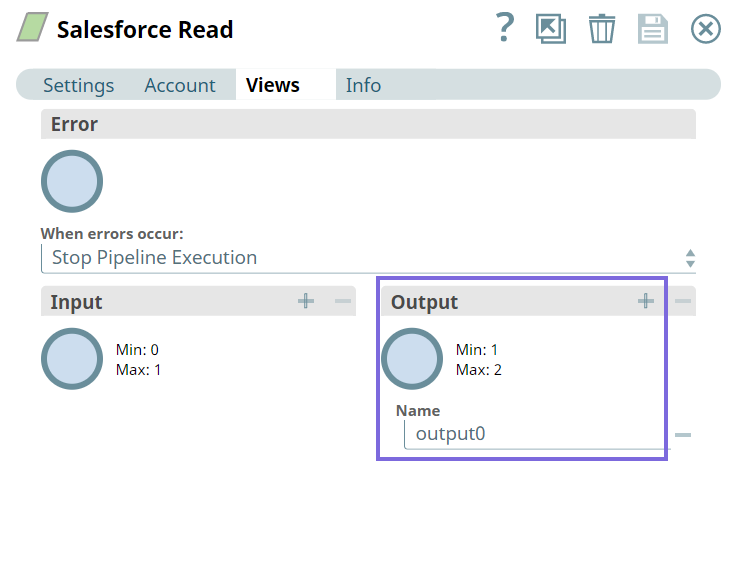
| Output | Document | Min: 1 Max: 2 | Mapper | The snap allows you to add an optional second output view that exposes the schema of the target object as the output document. |
| Error | Document | The error view contains error, reason, resolution and stack trace. For more information, see Handling Errors with an Error Pipeline | ||
Snap Settings
Field | Field Type | Description | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Label* Default Value: Salesforce Read | String | Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. | |||||||||||
Salesforce API* Default Value: REST API | Dropdown list | Choose the Salesforce API mode to use during the pipeline execution. The available options are:
We recommend you to set the Salesforce API mode to Bulk API if the table size of the Salesforce object referred to in the Object Type field is large (that is, 10,000 records or more) to prevent the time-out or connection error. | |||||||||||
Service Version* | Dropdown list | Loading | |||||||||||
Batch Size* Default Value: 2000 | Dropdown list | Specify the size of the records to process in each batch for downloading large query results. Each batch read requires an API call against Salesforce to retrieve the set of records.
The Snap validates using the Bulk API, even if you configure the Snap to use Bulk API with Primary Key (PK) Chunking. | |||||||||||
Use PK chunking if supported Default Value: Deselected | Expression/Checkbox | Appears when you select Bulk API from the Salesforce API dropdown. Select this checkbox to use PK chunking for the bulk API request if the object supports PK chunking. If you select this checkbox, the value from Batch Size is used as the PK chunking batch size. Please note that the chunk size applies to the number of records in the queried table rather than the number of records in the query result. For example, if the queried table has 10 million records and 250,000 is selected for Batch Size, 40 batches are created to execute the bulk query job. One additional control batch is also created and it does not process any records. Learn more about PK Chunking. You can enable expressions for this field in order to use input values from the pipeline parameters. Pipeline parameters are strings, and any non-empty string is treated as | |||||||||||
Object Type* Default Value: Account | String/Expression/Suggestion | Specify the name of the Salesforce object or select one from the suggested list. The Snap does not support Net Zero Cloud Salesforce objects. | |||||||||||
Output Fields | Use this field set to enter a list of field names for the SOQL SELECT statement. If left empty, the Snap selects all fields. | ||||||||||||
Output Fields Default Value: N/A
| String/Expression/Suggestion | Enter output field for SOQL statement. | |||||||||||
Output Field Limit Default Value: N/A | String/Expression | Specify the number of output fields to return from the Salesforce object. | |||||||||||
Output Field Offset Default Value: N/A | String/Expression | Defines a starting field index for the output fields. This is where the result set should start. If you enter an offset value that is greater than 1, the first field "ID" is always returned, but the following fields start from the offset position. This is because the first field is the only unique identifier. | |||||||||||
Where Clause Default Value: N/A | String/Expression | Enter the WHERE clause for the SOQL SELECT statement. Do not include the word WHERE. Using quotes in field names values
| |||||||||||
Order By Clause Default Value: N/A | String/Expression | Enter the ORDER BY clause that you want to use with your SOQL SELECT Query. PK Chunking does not support the ORDER BY clause. | |||||||||||
Limit Clause Default Value: N/A | String/Expression | Enter the LIMIT clause that you want to use with your SOQL SELECT Query. PK Chunking does not support the LIMIT clause. | |||||||||||
Polling Interval* Default Value: 5 | String | Define the polling interval in seconds for the Bulk API read execution. At each polling interval, the Snap checks the status of the Bulk API read batch processing. | |||||||||||
Polling Timeout* Default Value: 3000 | String | This property allows you to define the polling timeout in seconds for the Bulk API read batch execution. If the timeout occurs while waiting for the completion of the read batch execution, the Snap displays an exception. | |||||||||||
Process Date/time Default Value: Deselected | Checkbox | All date/time fields from Salesforce.com are retrieved as string type. Select this checkbox to allow the Snap to convert date/time fields to corresponding date/time types by accessing the metadata of the given SObject.
Deselect this checkbox to allow the Snap to send these date/time fields without any conversion. | |||||||||||
Include Deleted Records Default Value: Deselected | Expression/Checkbox | Select this checkbox to allow the Snap to include deleted records in the query. This feature is supported in REST API version 29.0 or later and Bulk API version 39.0 or later. You can enable expressions for this field in order to use input values from the pipeline parameters. Pipeline parameters are strings, and any non-empty string is treated as | |||||||||||
Pass Through Default Value: Selected | Checkbox | Select this checkbox to pass the input document to the output view under the key ' | |||||||||||
Ignore Empty Results Default Value: Selected | Checkbox | Select this checkbox to ignore empty results; no document will be written to the output view when the operation does not produce any result. If this property is not selected and Pass Through is selected, the input document will be passed through to the output view. If you do not select both the checkboxes, Ignore Empty Result and Pass Through, the Snap writes an empty output as below: [{}]
This property does not apply when you run the Snap in the Bulk API mode. When you run the Snap in Bulk API mode, if the Salesforce result is empty, the Snap does not pass the input document to the output view even if the Pass Through checkbox is selected. | |||||||||||
Bulk Content Type Default Value: XML | Dropdown list | Select the content type for Bulk API: JSON or XML. The numeric type field values will be read as numbers in JSON content type, and as strings in XML content type, in the output documents. JSON content type for Bulk API is available in Salesforce API version 36.0 or higher. In REST API, the number-type field values will always be read as numbers. If the Bulk API has been selected along with 100,000/ 250,000 as batch size value, the content-type will always be CSV regardless of the value set in this property. | |||||||||||
Number Of Retries Default Value: 1 | String/Expression | Specify the maximum number of retry attempts in case of a network failure.
Minimum value: 0 | |||||||||||
Retry Interval (seconds) Default Value: 1 | String/Expression | Specify the minimum number of seconds for which the Snap must wait before attempting recovery from a network failure. Minimum value: 0 | |||||||||||
Match Data Type Default Value: Not selected | Checkbox | Select this checkbox to match the data types of the Bulk API results with the data types of the REST API. This property applies only when the content type is XML for Bulk API (it does not apply to JSON). If the Bulk content type is XML, Salesforce.com returns all values as strings. If Match data type is selected, the Snap attempts to convert string values to the corresponding data types if the original data type is one of the following: boolean, integer, double, currency, or percent. This property is ignored in REST APIs or when the Bulk Content Type is JSON. For Bulk API, Salesforce.com does not return any value for null. | |||||||||||
Advanced Properties | Use this field set to define additional advanced properties that you want to add to the Snap's settings. Additional advanced properties are not required by default, and the field-set represents an empty table property. Click This field set contains the following fields:
| ||||||||||||
Properties | Dropdown list | You can use one or more of the following properties in this field:
| |||||||||||
| Values | String | The value that you want to associate with the property selected in the corresponding Properties field. The default values for the expected properties are:
| |||||||||||
Snap Execution Default Value: Validate & Execute | Dropdown list | Select one of the following three modes in which the Snap executes:
| |||||||||||
Loading
PK Chunking
PK chunking splits bulk queries on very large tables into chunks based on the record IDs, or primary keys, of the queried records. Each chunk is processed as a separate batch that counts toward your daily batch limit. PK chunking is supported for the following objects: Account, Campaign, CampaignMember, Case, Contact, Lead, LoginHistory, Opportunity, Task, User, and custom objects.
PK chunking works by adding record ID boundaries to the query with a WHERE clause, limiting the query results to a smaller chunk of the total results. The remaining results are fetched with additional queries that contain successive boundaries. The number of records within the ID boundaries of each chunk is referred to as the chunk size. The first query retrieves records between a specified starting ID and the starting ID plus the chunk size, the next query retrieves the next chunk of records, and so on. Since Salesforce.com appends a WHERE clause to the query in the PK Chunking mode, if SOQL Query has LIMIT clause in it, the Snap will submit a regular bulk query job without PK Chunking.
Learn more about the Salesforce PK Chunking Header.
If you select the Use PK chunking if supported checkbox, the value from Batch Size is used as the PK chunking batch size. Please note that the chunk size applies to the number of records in the queried table rather than the number of records in the query result. For example, if the queried table has 10 million records and 250,000 is selected for Batch Size, 40 batches are created to execute the bulk query job. One additional control batch is also created and it does not process any records. The status of the submitted bulk job and its batches can be monitored by logging in to your Salesforce.com account and going to Setup. From Setup, enter Bulk Data Load Jobs in the Quick Find box, then select Bulk Data Load Jobs.
PK Chunking requires Service Version 28.0 or later, cannot be used with Order By Clause or Limit Clause, and isn’t available for all Salesforce objects. Therefore, if Bulk API and Use PK chunking if supported are selected but other settings in the Snap don’t support PK chunking, the Snap will submit a regular bulk query job without PK chunking and display a warning that PK chunking was not used.
If your account doesn’t support PK chunking and you’re using the Bulk API, deselect the Use PK chunking if supported checkbox.
The output document schemas in preview mode (validation) and execution mode for this Snap may differ when using Primary Key (PK) Chunking mode. This is because the Snap intentionally generates the output preview using regular Bulk API instead of PK Chunking, to reduce the costs involved in the PK Chunking operation.
Salesforce recommends the use of PK Chunking if the target Salesforce object (table) is relatively large (for example, more than few 100,000 records).
Examples
Pipeline: Salesforce.com Data to a File: This Pipeline reads data using a Salesforce read and writes it to a file.
Reading Records from an Object
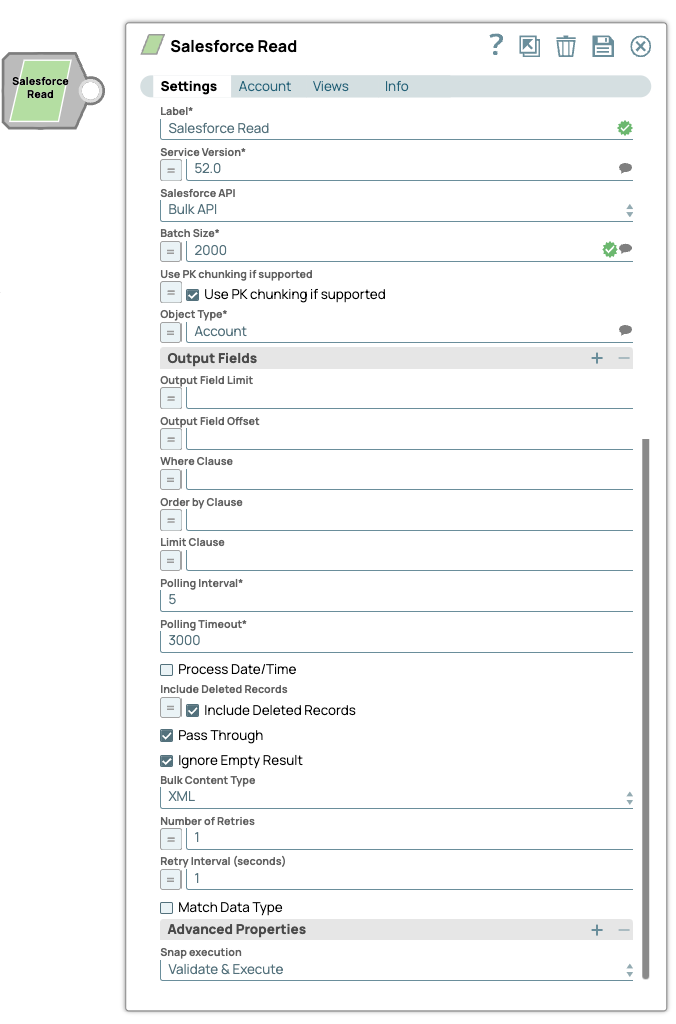
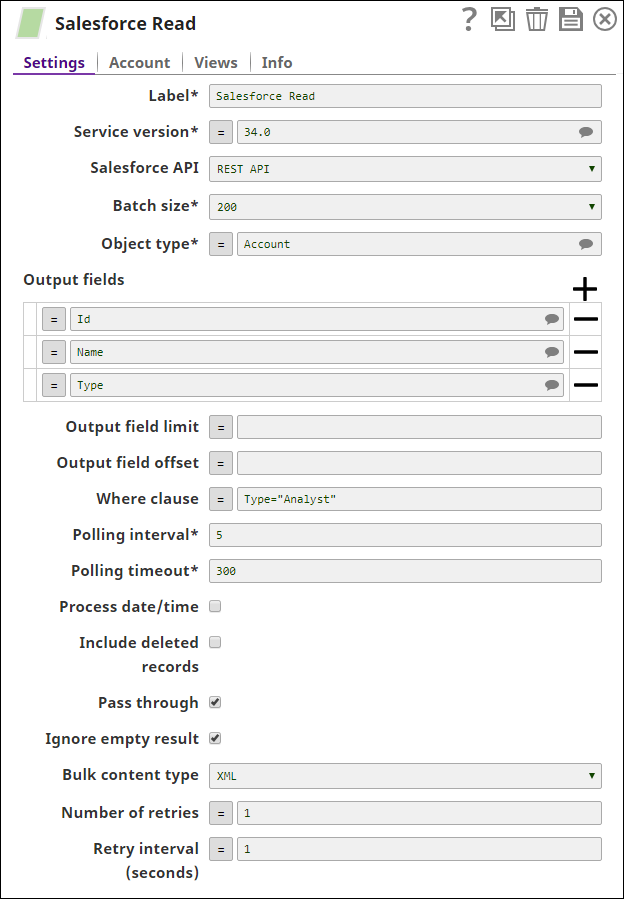
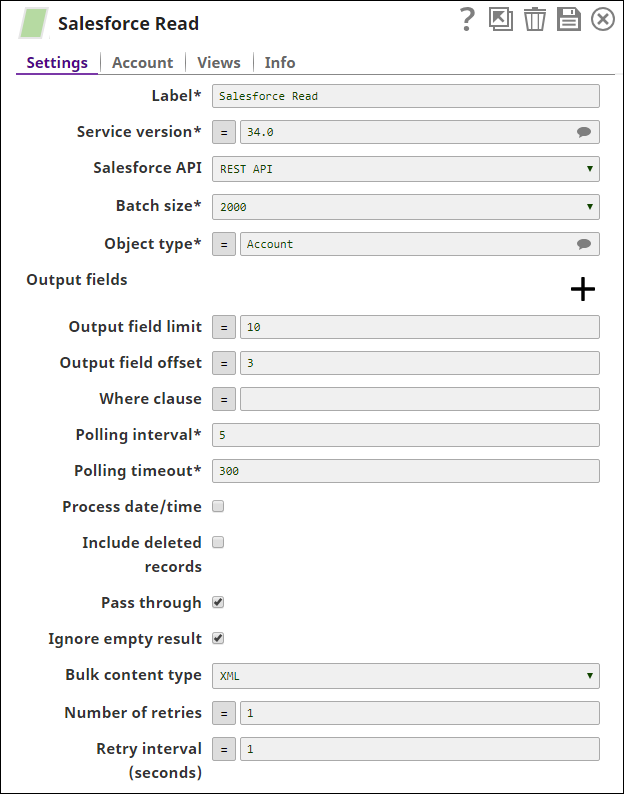
The following Salesforce Read Snap shows how the Snap is configured and how the object records are read. The Snap reads records from the Account object, and retrieves values for the fields, Id, name, & type where the type field value is Analyst:
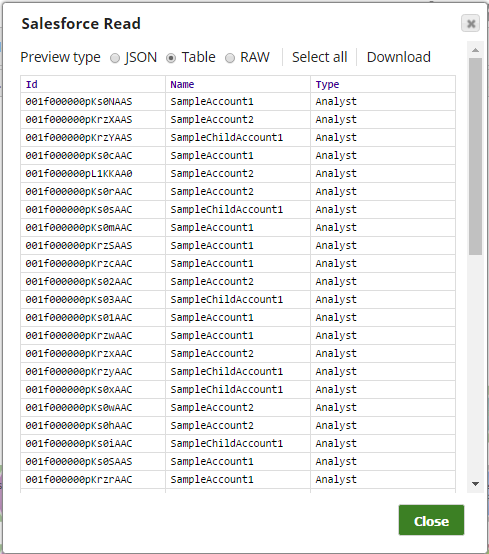
Successful execution of the Snap gives the following preview:
Reading Records in Bulk
The Salesforce Read Snap reads the records from the Standard Object, Account, and retrieves values for the 10 output fields (Output field limit) starting from the 3rd field (Output field offset). Additionally, we are passing the values dynamically for the Access token and the Instance URL fields in the Account settings of the Snap by defining the respective values in the pipeline parameters.
1. The Salesforce Read Pipeline.
.png?version=1&modificationDate=1489678060000&cacheVersion=1&api=v2)
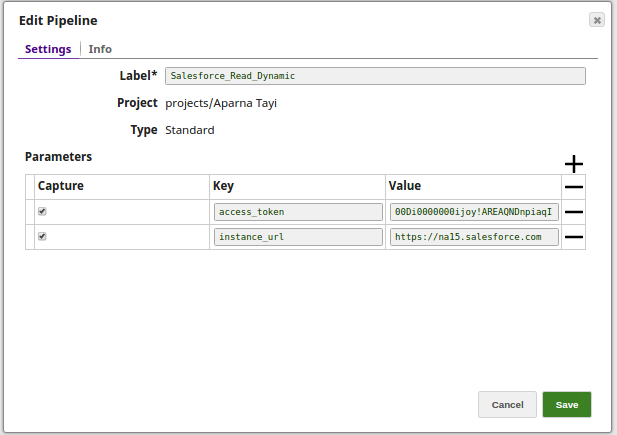
2. The Key and Value parameters are assigned using the Edit Pipeline property on the designer.
For this Pipeline, define the two Pipeline parameters:
- access_Token
- instance_URL
3. The Salesforce Read Snap reads the records from the Standard object, Account, to the extent of 10 output fields starting from the 3rd record(by defining the properties- Output field limit and Output field offset with the values 10 and 3 respectively).
4. Create a dynamic account and toggle (enable) the expressions for Access Token and Instance URL properties in order to pass the values dynamically.
Set Access token to _access_token and Instance URL to _instance_url. Note that the values are to be passed manually and are not suggestible.
.png?version=1&modificationDate=1489678265342&cacheVersion=1&api=v2&width=650&height=438)
5. Successful execution of the Pipeline displays the below output preview:
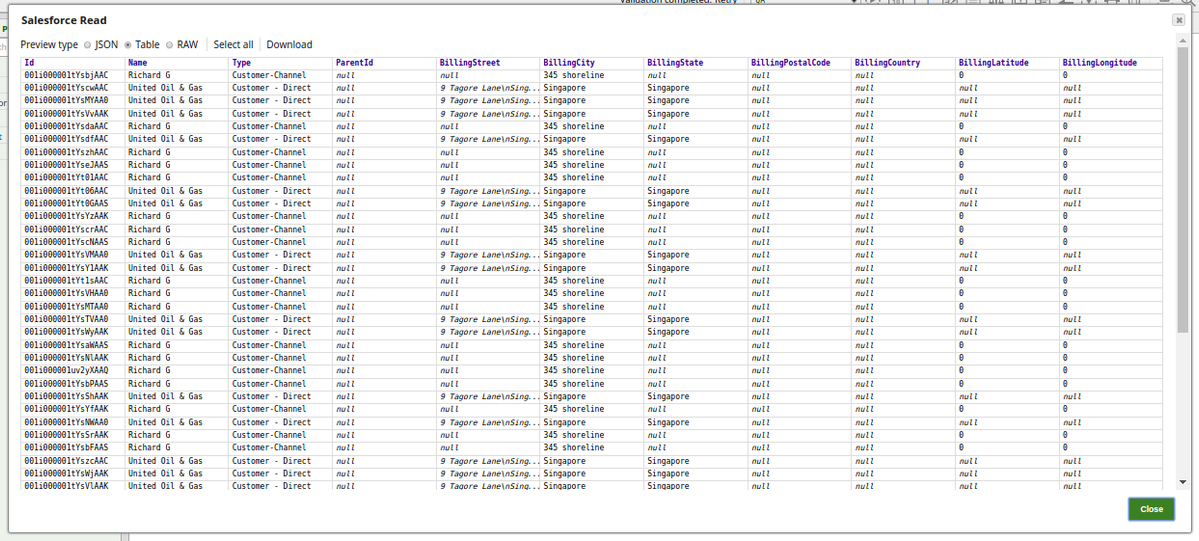
Using Second Output View
This example Pipeline demonstrates how you can add an optional second output view that exposes the schema of the target object as the output document. For this, we configure the Pipeline using the Mapper and Salesforce Read Snaps.
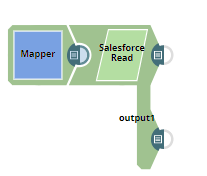 |  |
First, we configure the Mapper Snap as follows. Upon validating the Snap, the target schema is populated in the Mapper Snap. Once this is available, we define the target path variables from the target schema.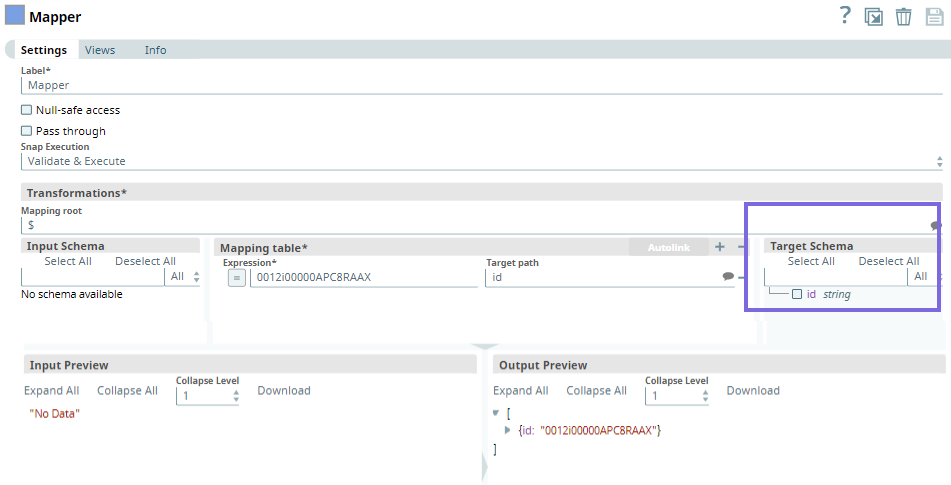
Upon validation, the following output is generated in the Snap's preview.
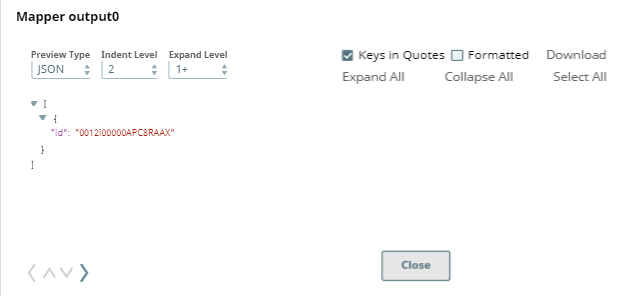
Next, we configure the Salesforce Read Snap to read the specified records.
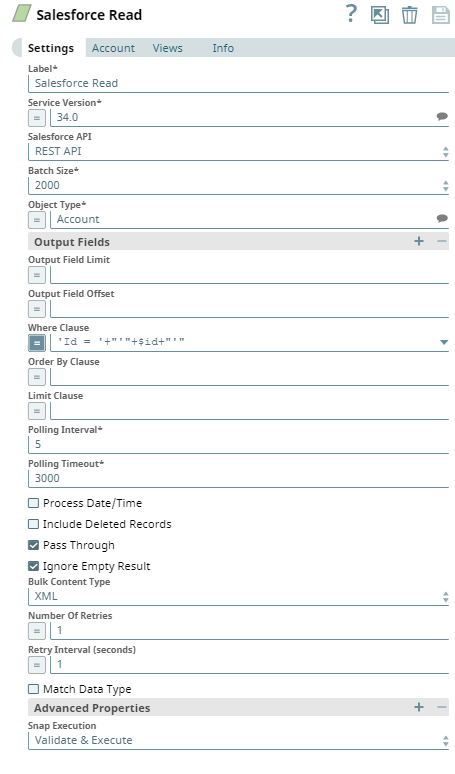
Upon validation, we can see the following outputs in both the output views of the Snap.
Output0 (default)
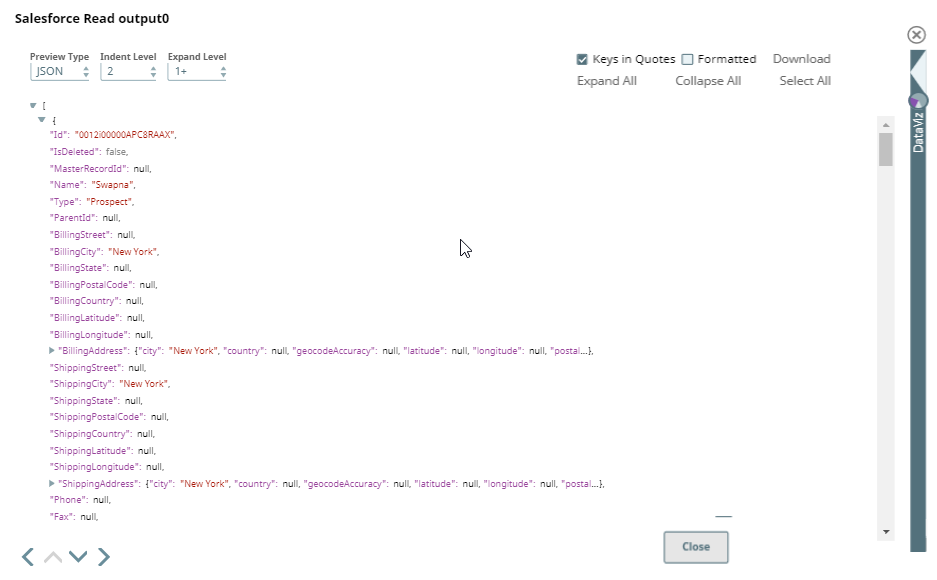
Output 1
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.