| Snap type: | Write | ||||||
|---|---|---|---|---|---|---|---|
| Description: | This Snap executes a Redshift bulk load. The input data is first written to a staging file on S3. Then the Redshift copy command is used to insert data into the target table. Table CreationIf the table does not exist when the Snap tries to do the load, and the Create table property is set, the table will be created with the columns and data types required to hold the values in the first input document. If you would like the table to be created with the same schema as a source table, you can connect the second output view of a Select Snap to the second input view of this Snap. The extra view in the Select and Bulk Load Snaps are used to pass metadata about the table, effectively allowing you to replicate a table from one database to another. The table metadata document that is read in by the second input view contains a dump of the JDBC DatabaseMetaData class. The document can be manipulated to affect the CREATE TABLE statement that is generated by this Snap. For example, to rename the name column to full_name, you can use a Mapper (Data) Snap that sets the path $.columns.name.COLUMN_NAME to full_name. The document contains the following fields:
ETL Transformations & Data FlowThis Snap executes a Load function with the given properties. The documents that are provided on the input view will be inserted into the provided table on the provided database. Input & Output:
Modes
| ||||||
| Prerequisites: | IAM Roles for Amazon EC2 The 'IAM_CREDENTIAL_FOR_S3' feature is to access S3 files from EC2 Groundplex, without Access-key ID and Secret key in the AWS S3 account in the Snap. The IAM credential stored in the EC2 metadata is used to gain the access rights to the S3 buckets. To enable this feature, the following line should be added to global.properties and the jcc (node) restarted:
Please note this feature is supported in the EC2-type Groundplex only. For more information on IAM Roles, see http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/iam-roles-for-amazon-ec2.html | ||||||
| Limitations and Known Issues | The Snap will not automatically fix some errors encountered during table creation since they may require user intervention to be resolved correctly. For example, if the source table contains a column with a type that does not have a direct mapping in the target database, the Snap will fail to execute. You will then need to add a Mapper (Data) Snap to change the metadata document to explicitly set the values needed to produce a valid CREATE TABLE statement. If string values in the input document contain the '\0' character (string terminator), the Redshift COPY command, which is used by the Snap internally, fails to handle them properly. Therefore, the Snap skips the '\0' characters when it writes CSV data into the temporary S3 files before the COPY command is executed. | ||||||
| Account: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. The S3 Bucket, S3 Access-key ID and S3 Secret key properties are required for the Redshift-Bulk Load Snap. The S3 Folder property may be used for the staging file. If the S3 Folder property is left blank, the staging file will be stored in the bucket. See Redshift Account for information on setting up this type of account. | ||||||
| Configurations: | Account & AccessThis Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. The S3 Bucket, S3 Access-key ID and S3 Secret key properties are required for the Redshift-Bulk Load Snap. The S3 Folder property may be used for the staging file. If the S3 Folder property is left blank, the staging file will be stored in the bucket. See Redshift Account for information on setting up this type of account. Views:
| ||||||
Settings | |||||||
| Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | ||||||
| Schema name | The database schema name. In case it is not defined, then the suggestion for the Table Name will retrieve all tables names of all schemas. The property is suggestible and will retrieve available database schemas during suggest values. The values can be passed using the pipeline parameters but not the upstream parameter. Example: SYS | ||||||
| Table name | Required. Table on which to execute the bulk load operation. The values can be passed using the pipeline parameters but not the upstream parameter. Example: people Default value: [None] | ||||||
| Create table if not present | Whether the table should be automatically created if it is not already present. Using this option creates a table with all columns of type STRING. Default value: Not selected | ||||||
| Validate input data | If selected, the Snap performs input data validation to verify whether all input documents are flat map data. If any value is a Map or a List object, the Snap writes an error to the error view, and if this condition occurs, no document is written to the output view. See the Troubleshooting section above for information on handling errors caused due to invalid input data. Default value: Not selected Recommendation If this property is not selected, the Snap does not validate the structure of input documents, converts all values to strings, writes the S3 CSV file, and executes the Redshift COPY command. If the COPY command finds error in the input CSV data, it writes errors to the error table, and the Snap routes these errors to the error view (if error view is enabled). However, some errors reported by the COPY command may not be easy to understand. Therefore, it is advisable to enable input data validation during pipeline development and testing, as this may also help troubleshoot the pipeline. Flat Map Data Flat map data is a collection of key-value pairs, where the values are all single-class objects unlike a Map or List. | ||||||
| Truncate data | Required. Truncate existing data before performing data load. With the Bulk Update Snap, instead of doing truncate and then update, a Bulk Insert would be faster. Default value: Not selected | ||||||
Update statistics | Required. Update table statistics after data load by performing an Analyze operation on the table. Default value: Not selected | ||||||
| Accept invalid chars | Accept invalid characters in the input. Invalid UTF-8 characters are replaced with a question mark when loading. Default value: Selected | ||||||
| Maximum error count | Required. Maximum number of rows which can fail before the bulk load operation is stopped. Example: 10 (if you want the pipeline execution to continue as far as the number of failed records is less than 10) | ||||||
| Truncate columns | Truncate column values which are larger than the maximum column length in the table Default value: Selected | ||||||
| Disable data compression | Disable compression of data being written to S3. Disabling compression will reduce CPU usage on the Snaplex machine, at the cost of increasing the size of data uploaded to S3. Default value: Not selected | ||||||
| Load empty strings | If selected, empty string values in the input documents are loaded as empty strings to the string-type fields. Otherwise, empty string values in the input documents are loaded as null. Null values are loaded as null regardless. Default value: Not selected | ||||||
| Additional options | Additional options to be passed to the COPY command. Check http://docs.aws.amazon.com/redshift/latest/dg/r_COPY.html for available options. Default value: [None] | ||||||
| Parallelism | Defines how many files will be created in S3 per execution. If set to 1 then only one file will be created in S3 which will be used for the copy command. If set to n with n > 1, then n files will be created as part of a manifest copy command, allowing a concurrent copy as part of the Redshift load. The Snap itself will not stream concurrent to S3. It will use a round robin mechanism on the incoming documents to populate the n files. The order of the records is not preserved during the load. Default value: [None] | ||||||
Server-side encryption | This defines the S3 encryption type to use when temporarily uploading the documents to S3 before the insert into the Redshift. Default value: Not selected | ||||||
| KMS Encryption type | Specifies the type of KMS S3 encryption to be used on the data. The available encryption options are:
Default value: None If both the KMS and Client-side encryption types are selected, the Snap gives precedence to the SSE, and displays an error prompting the user to select either of the options only. | ||||||
| KMS key | Conditional. This property applies only when the encryption type is set to Server-Side Encryption with KMS. This is the KMS key to use for the S3 encryption. For more information about the KMS key, refer to AWS KMS Overview and Using Server Side Encryption. Default value: [None] | ||||||
| Vacuum type | Reclaims space and sorts rows in a specified table after the upsert operation. The available options to activate are FULL, SORT ONLY, DELETE ONLY and REINDEX. Refer to the AWS document on "Vacuuming Tables" for more information. Auto-commit needs to be enabled for Vacuum. Default value: NONE | ||||||
| Vacuum threshold (%) | Specifies the threshold above which VACUUM skips the sort phase. If this property is left empty, Redshift sets it to 95% by default. Default value: [None] | ||||||
Snap execution | Select one of the three modes in which the Snap executes. Available options are:
| ||||||
In a scenario where the Auto commit on the account is set to true, and the downstream Snap does depends on the data processed on an Upstream Database Bulk Load Snap, use the Script Snap to add delay for the data to be available.
For example, when performing a create, insert and a delete function sequentially on a pipeline, using a Script Snap helps in creating a delay between the insert and delete function or otherwise it may turn out that the delete function is triggered even before inserting the records on the table.
Redshift's Vacuum Command
In Redshift, when rows are DELETED or UPDATED against a table they are simply logically deleted (flagged for deletion), not physically removed from disk. This causes the rows to continue consuming disk space and those blocks are scanned when a query scans the table. This results in an increase in table storage space and degraded performance due to otherwise avoidable disk IO during scans. A vacuum recovers the space from deleted rows and restores the sort order.
Basic Use Case
The following pipeline describes how the Snap functions as a standalone Snap in a pipeline:
Use Case: Replicate a Database Schema in Redshift
MySQL Select to Redshift Bulk Load
In this example, a MySQL Select Snap is used to select data from 'AV_Persons' table belonging to the 'enron' schema. The Mapper Snap maps this data to the target table's schema and is then loaded onto the "bulkload_demo" table in the "prasanna" schema:
Select the data from the MySQL database.
Mapper will be used to map the data to the input schema that is associated with Redshift Bulkload database table.
Loads the input Documents that is coming from the Mapper to a S3 file.
Finally invoke the COPY command to invoke the created S3 file to insert the data into the destination table.
.png?version=1&modificationDate=1510743705391&cacheVersion=1&api=v2&width=490&height=344)
Typical Snap Configurations
Key configuration lies in how the SQL statements are passed to perform bulk load of the records. The statements can be passed:
Without Expression
The values are passed directly to the Snap.
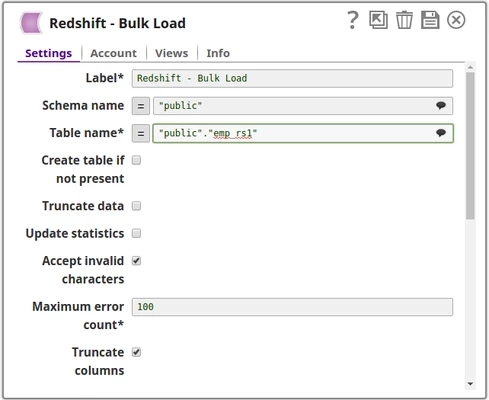
With Expression
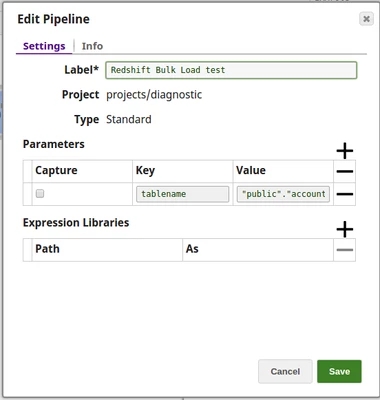
Using Pipeline parameters
The Table name is passed as a Pipeline parameter.
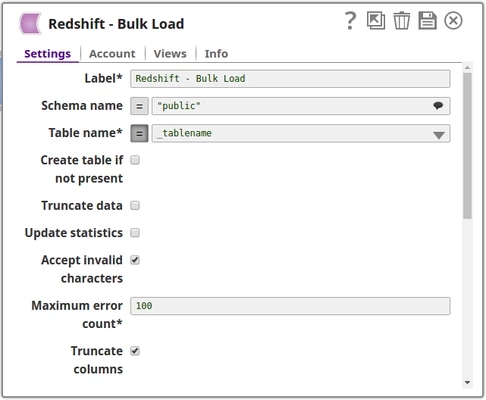
Advanced Use Case
The following describes a pipeline that shows how typically in an enterprise environment, a lookup functionality is used. Pipeline download link is in the Downloads section below. In this pipeline, tweets pertaining to a keyword "#ThursdayThoughts" are extracted using a Twitter Query Snap and loaded into the table "twittersnaplogic" in the public schema using the Redshift Bulk Load Snap. When executed, all the records are loaded into the table.
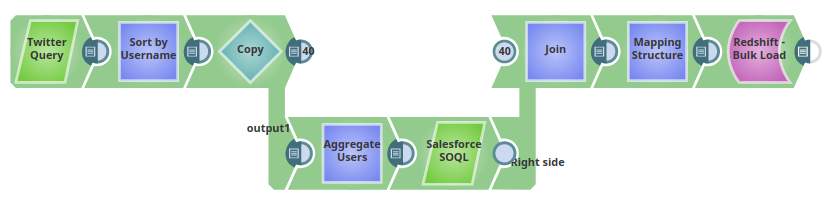
The pipeline performs the following ETL operations:
Extract: Twitter Query Snap selects 25 tweets (a value specified in the Maximum tweets property) pertaining to the Twitter query.
Transform: The Sort Snap, labeled Sort by Username in this pipeline, sorts the records based on the value of the field user.name.
Extract: The Salesforce SOQL Snap extract's records matching the user.name field value. Extracted records are LastName, FirstName, Salutation, Name, and Email.
Load: The Redshift Bulk Load Snap loads the results into the table, twittersnaplogic, on the Redshift instance.
The configuration of the Twitter Query Snap is as shown below:

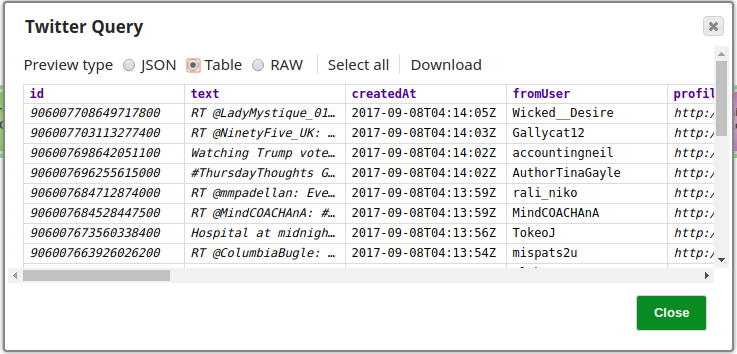
The Twitter Query Snap is configured to retrieve 25 records from the Account, a preview of the Snap's operation is shown below:
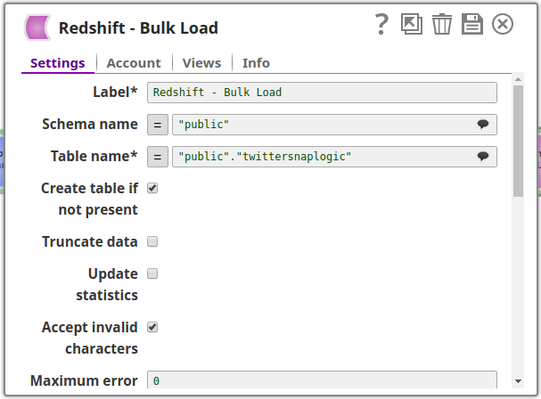
The Redshift Bulk Load Snap is configured as shown in the figure below:
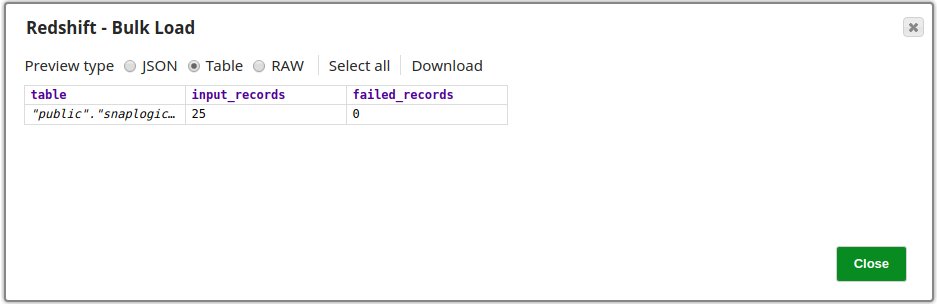
Successful execution of the Snap is denoted by a count of the records loaded into the specified table, note that the number of failed records is also shown provided it does not exceed the limit specified in the Maximum error count property, in which case it would stop the pipeline. The image below shows that all 25 records retrieved in the Twitter Query Snap have been loaded into the table successfully.
Advanced Use Case #2
The following describes a pipeline that shows how typically in an enterprise environment, a bulk load functionality is used. Pipeline download link is in the Downloads section below. In this pipeline, the File Reader Snap reads the data, from which the data will be loaded in to the table using the Redshift Bulk Load Snap. When executed, all the records are loaded into the table.

The pipeline performs the following ETL operations:
Extract: File Reader snap will read the data from the file and submit it to the CSV parser.
Transform: CSV Parser will perform the parsing of the provided data which will be written to the MySQL insert snap.
Extract: The entire data will be loaded into the Redshift table, by creating new table with the provided schema.
Downloads