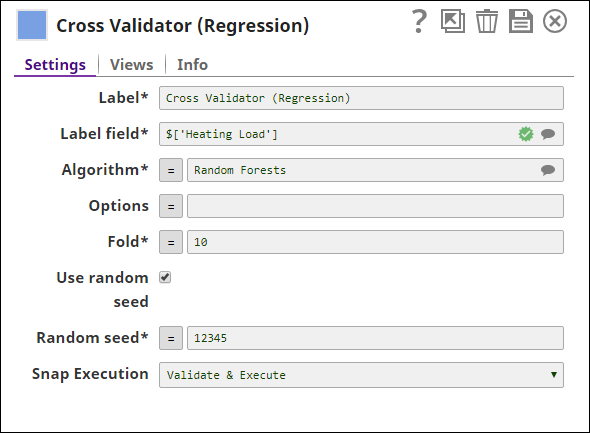
Cross Validator (Regression)
- Amritesh Singh
- Mohammed Iqbal
- John Brinckwirth
On this Page
Overview
This is a Transform type Snap that performs K-fold Cross Validation on a regression dataset. Cross validation is a technique for evaluating ML algorithms by splitting the original dataset into K equally-sized chunks. K is the number of folds. In each of the K iterations, K-1 chunks are used to train the model while the last chunk is used as a test set. The average error and other statistics are computed to be used to select the most suitable algorithm for the dataset.
In the settings, you can select the algorithm, specify parameters, and number of folds. If you want to perform K-fold Cross Validation on classification dataset, use the Cross Validator - Classification Snap instead.
Input and Output
Expected input: The regression dataset.
Expected output: Statistical information about the performance of the selected algorithm on the dataset.
Expected upstream Snap: Any Snap that generates a dataset document. For example, CSV Generator, JSON Generator, or a combination of File Reader and JSON Parser.
Expected downstream Snap: CSV/JSON Formatter Snap and File Writer Snap can be used to write the output statistics to file.
Prerequisites
- The data from upstream Snap must be in tabular format (no nested structure).
- This Snap automatically derives the schema (field names and types) from the first document. Therefore, the first document must not have any missing values.
Configuring Accounts
Accounts are not used with this Snap.
Configuring Views
Input | This Snap has exactly one document input view. |
|---|---|
| Output | This Snap has exactly one document output view. |
| Error | This Snap has at most one document error view. |
Troubleshooting
None.
Limitations and Known Issues
None.
Modes
- Ultra Pipelines: Does not work in Ultra Pipelines.
Snap Settings
| Label | Required. The name for the Snap. Modify this to be more specific, especially if there are more than one of the same Snap in the pipeline. |
|---|---|
| Label field | Required. The label or output field in the dataset. This must be numeric. This is the field that the model will be trained to predict. Default value: None Example: $price |
| Algorithm | Required. The regression algorithm to be used to build the model. There are four regression algorithms available currently:
The implementations are from WEKA, an open source machine learning library in Java. Default value: K-Nearest Neighbors |
| Option | The parameters to be applied on the selected algorithm. Each algorithm has a different set of parameters to be configured in this property. If this property is left blank, the default values are applied for all the parameters. If specifying multiple parameters, separate them with a comma ",". See Options for Algorithms section below for details. Default value: None Examples:
|
| Fold | Required. The number of folds. Minimum value: 2 Default value: 10 |
| Use random seed | If selected, Random seed is applied to the randomizer in order to get reproducible results. Default value: Selected |
| Random seed | Required. Number used as static seed for randomizer. Default value: 12345 |
Snap Execution | Select one of the following three modes in which the Snap executes:
Default Value: Execute only |
Example
Heating Load Prediction – Cross Validation
This pipeline demonstrates a typical cross validation exercise for a dataset before a model is trained to prediction the target field. The dataset is a record of various aspects of a building. The building's required heating load depends upon each of these aspects. The cross validation is to validate the model's ability to predict this heating load.

Download this pipeline.
Input
The input is generated by the CSV Generator Snap and is composed of the following fields:
- Relative Compactness
- Surface Area
- Wall Area
- Roof Area
- Overall Height
- Orientation
- Glazing Area
- Glazing Area Distribution
- Heating Load
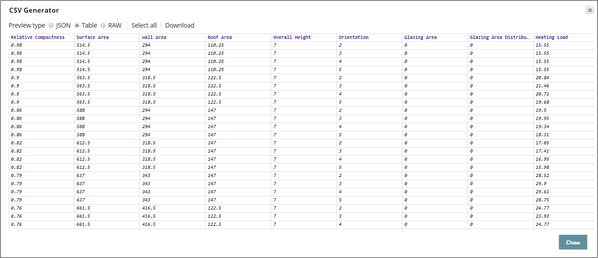
This dataset has been sourced fromUCI Dataset Archive.
Objective
Use Cross Validator (Regression) Snap to evaluate how each ML algorithm performs in this dataset.
Data Preparation
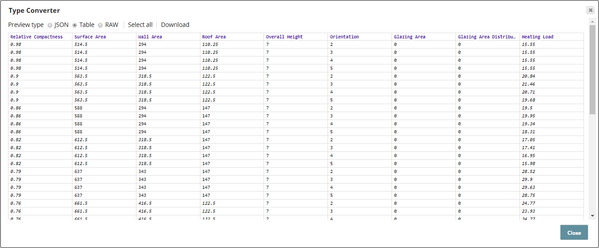
This input document is passed through the Type Converter Snap that is configured to automatically detect and convert the data types. In any ML pipeline, you must first analyze the input document using the Profile Snap and the Type Inspector Snap to ensure that there are no null values or that the data types are accurate. This step is skipped in this example for simplicity's sake.
Below is a preview of the output from the Type Converter Snap:
Cross Validation
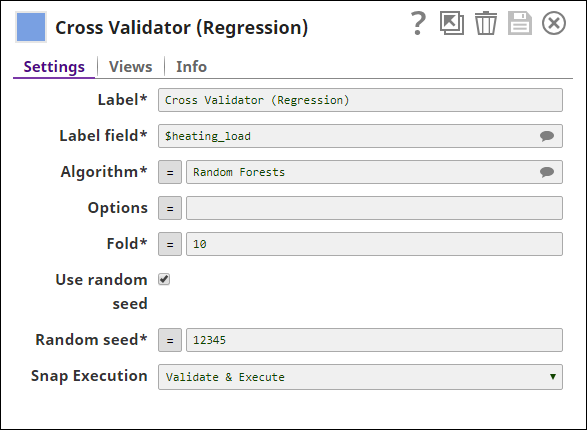
After preparing the data, the first thing to do is K-fold Cross Validation. Cross Validator (Regression) Snap takes the full dataset and randomly splits the dataset into training set and test set which are used to evaluate the selected ML algorithm.
Below is the configuration of the Cross Validator (Regression) Snap:
The output from this Snap is as shown below:
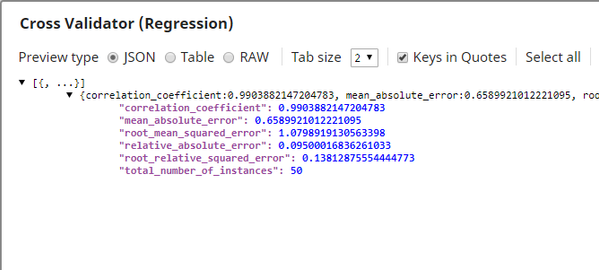
Optionally, you can write the output from the Cross Validator (Regression) Snap into a file using the downstream File Writer Snap.
Download this pipeline.
Additional Example
The following use case demonstrates a real-world scenario for using this Snap:
Downloads
Important steps to successfully reuse Pipelines
- Download and import the pipeline into the SnapLogic application.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.
Snap Pack History
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.